
作者:Athavale Vilas, Matte Ravinder, Anand Sid, Verma Shrity, Gopalani Naresh, Avalani Bhaven
摘要沃尔玛部署了 Apache Kafka,涉及超过 25000 个 Kafka 消费者,横跨多个云环境(包括公共云和私有云)。支持关键业务应用场景,包括数据传输、基于事件的微服务以及实时数据分析。这些应用场景需要达到四个九(即 99.99)的可用性,并要求我们快速解决由于流量突增而产生的任何积压。在沃尔玛的规模下,我们有一系列多样化的 Kafka 消费者应用程序,这些应用程序使用多种语言编写。这种多样性加上我们的可靠性需求,需要消费者应用程序采用最佳做法以确保高可用性的服务等级目标(SLO)。由于 Kafka 消费者重新平衡导致的高消费者延迟是大规模操作 Kafka 消费者时最常见的挑战。在本文中,我们强调了如何在每天处理数万亿条消息的规模下可靠地处理 Apache Kafka 消息,同时保持低成本和高弹性。
面临的挑战 消费再平衡在Kafka的生产部署中,经常遇到的一个问题是消费端的重新均衡。Kafka的重新均衡是指通过重新分配分区,确保每个消费端处理大致相等的分区数量。这确保了数据处理在消费者之间均匀分布,并且每个消费者都在尽可能高效地处理数据。Kafka应用程序可以在容器或虚拟机(又称VM)上运行。本文主要讨论容器环境,因为这是当前行业中的主流。基于容器镜像构建的Kafka消费者应用运行在WCNP(沃尔玛云原生平台)——这是一个企业级的多云容器编排框架,基于Kubernetes框架。引发消费者重新平衡的因素有很多,包括:
- 消费者 pod 离开消费者组:这可能是由 K8s 部署或滚动重启或自动或手动减少规模引起的。
- 消费者 pod 进入消费者组:这可能是由 K8s 部署或滚动重启或自动或手动增加规模引起的。
- Kafka 代理相信消费者已经失败(例如,如果代理在 session.timeout.ms 内未从消费者接收到心跳):这将在 JVM 退出或长时间的垃圾收集暂停时触发。
- Kafka 代理认为消费者卡住了(例如,如果消费者花费的时间超过 max.poll.interval.ms 来轮询下一个批次的记录来消费):这将在已经处理之前轮询的记录超出此间隔时触发。
虽然消费者重平衡在应对计划维护(例如,代码发布)、标准操作(例如,手动调整最小和最大Pod数)和自动修复(如Pod崩溃和自动扩展)时实现了弹性,但它导致延迟增加。鉴于当今商业的近乎实时特性,许多Kafka用例具有严格的交付时间协议——这些应用程序在生产环境中因频繁且不可预测的再平衡而持续收到延迟警报。
目前还没有简单的方法来配置消费者以避免在Kafka中重新分配。虽然社区提供了静态消费者成员列表以及增量协作重新平衡,但这些方法也带来了各自的挑战。
毒丸条款头消息(Head-of-line, HOL)阻塞现象是一种可能出现在网络和消息系统中的性能限制现象。如果Kafka消费者遇到一条无法成功处理的消息,这种情况就会发生。如果消息处理导致Kafka消费者线程抛出未处理的异常,消费者将在下一次从代理轮询时重新消费同一消息批次——该批次中的“毒丸”消息会导致相同的异常。除非通过部署修复代码跳过有问题的消息,或正确处理它,或者通过更改消费者偏移量来跳过问题消息,否则这个循环将持续无限期。这进一步证明了在按顺序处理分区数据流时可能会遇到的另一个问题。Apache Kafka并不会自动处理这种“毒丸”消息。
花费主题中的分区与其读取它们的消费者线程之间耦合度很高。如果消费者无法跟上主题的数据量(即,无法维持较低的消费者滞后),增加消费者只能在所有分区都被分配给特定消费者线程之前起到一定作用。需要增加分区数量来容纳更多的消费者。虽然这听起来可能是个好办法,在达到需要升级代理节点到更大规格之前,可以在代理上添加的分区数量有一定的通用规则(每代理4000个分区)。如您所见,消费者滞后增加会导致更多的分区,甚至可能需要将代理升级到更大规模,尽管代理本身可能有足够的资源(例如,内存、CPU和存储)。这种分区和消费者之间的紧密联系长期以来一直是许多工程师在Kafka中保持低延迟的困扰,尤其是在流量增加时。
Kafka 分区的可扩展性当管道数量达到数千条时,增加分区在操作上变得复杂,需要生产者、消费者和平台团队之间的协调工作,同时会导致短暂停机。突然的流量激增和大量积压都需要增加分区和Pod数量。
解答为解决上述的一些挑战,比如 Kafka Consumer Rebalancing,Kafka 社区提出了以下 Kafka 改进提案(KIP-932):KIP-932: Kafka 队列功能。
消息代理服务(MPS)是一个可用的不同通道。MPS 通过代理消息到 HTTP REST 端点来使得 Kafka 的消费不再受制于分区约束,消费者现在在这些端点之后等待。通过 MPS 方法,Kafka 消费不再受到重新平衡的影响,同时还能在使用更少分区的情况下提高吞吐量。
MPS方法的好处之一是,应用团队不必再使用Kafka消费者客户端。这样,Kafka团队也不用再督促应用团队更新Kafka客户端库。
设计MPS Kafka 消费者由两个独立的线程组组成:Kafka 消息读取线程(即一个线程)和消息处理与写入线程。这些线程组通过标准缓冲模式(pendingQueue)隔开。读取线程在轮询时将消息写入有界缓冲区,而写入线程从该缓冲区读取消息。
有界缓冲区还可以控制读取和写入线程的速度。当 pendingQueue 达到最大缓冲区大小的限制时,message_reader 线程会暂停消费者线程。
将读取线程和写入线程分离使得读取线程非常轻量,并且不会因为在max.poll.interval.ms时间内超时而触发重新平衡操作。现在,写入线程可以花更多时间来处理消息。以下图表展示了组件和设计。
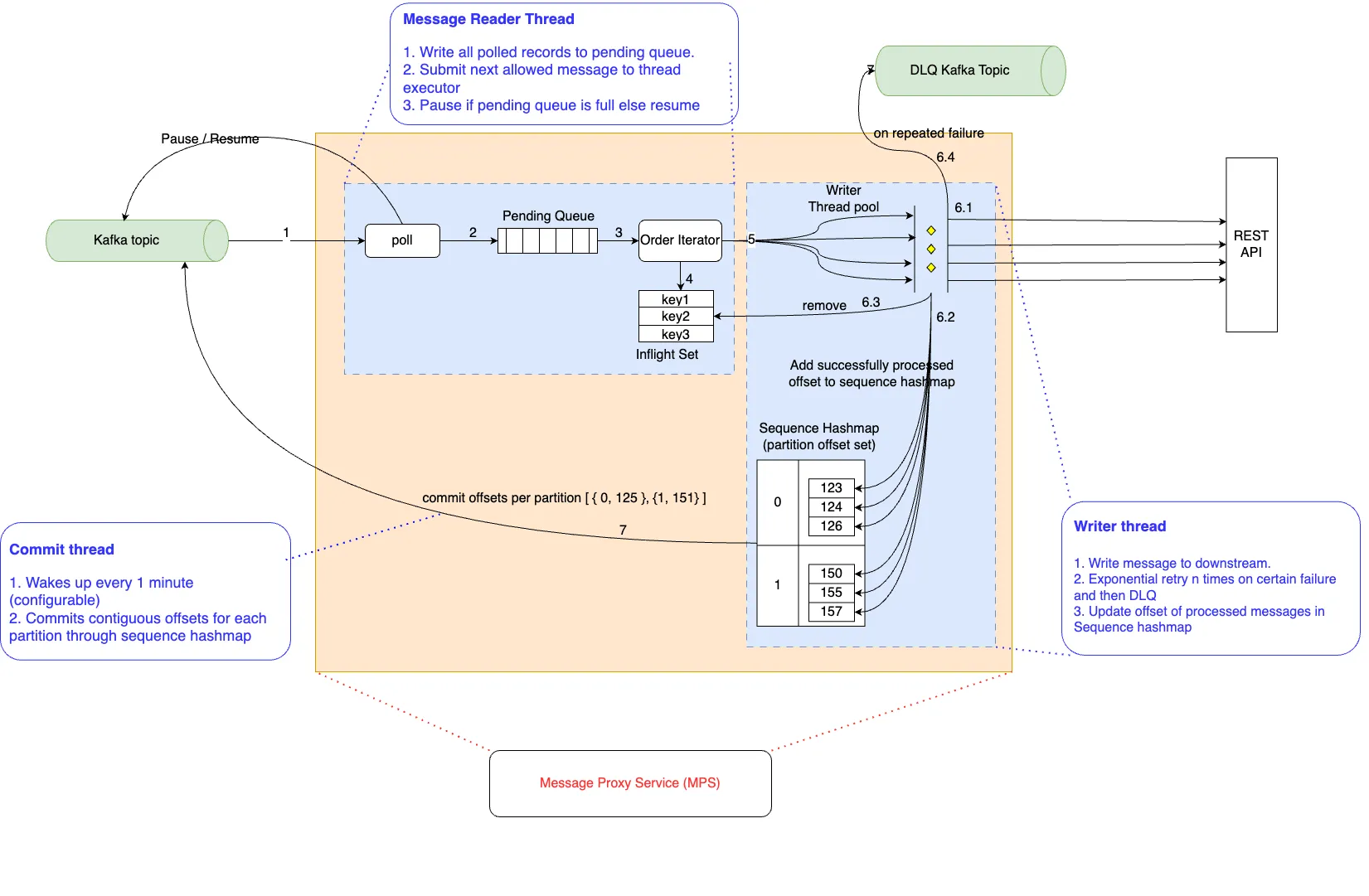
zh: 设计和组件的示意图。
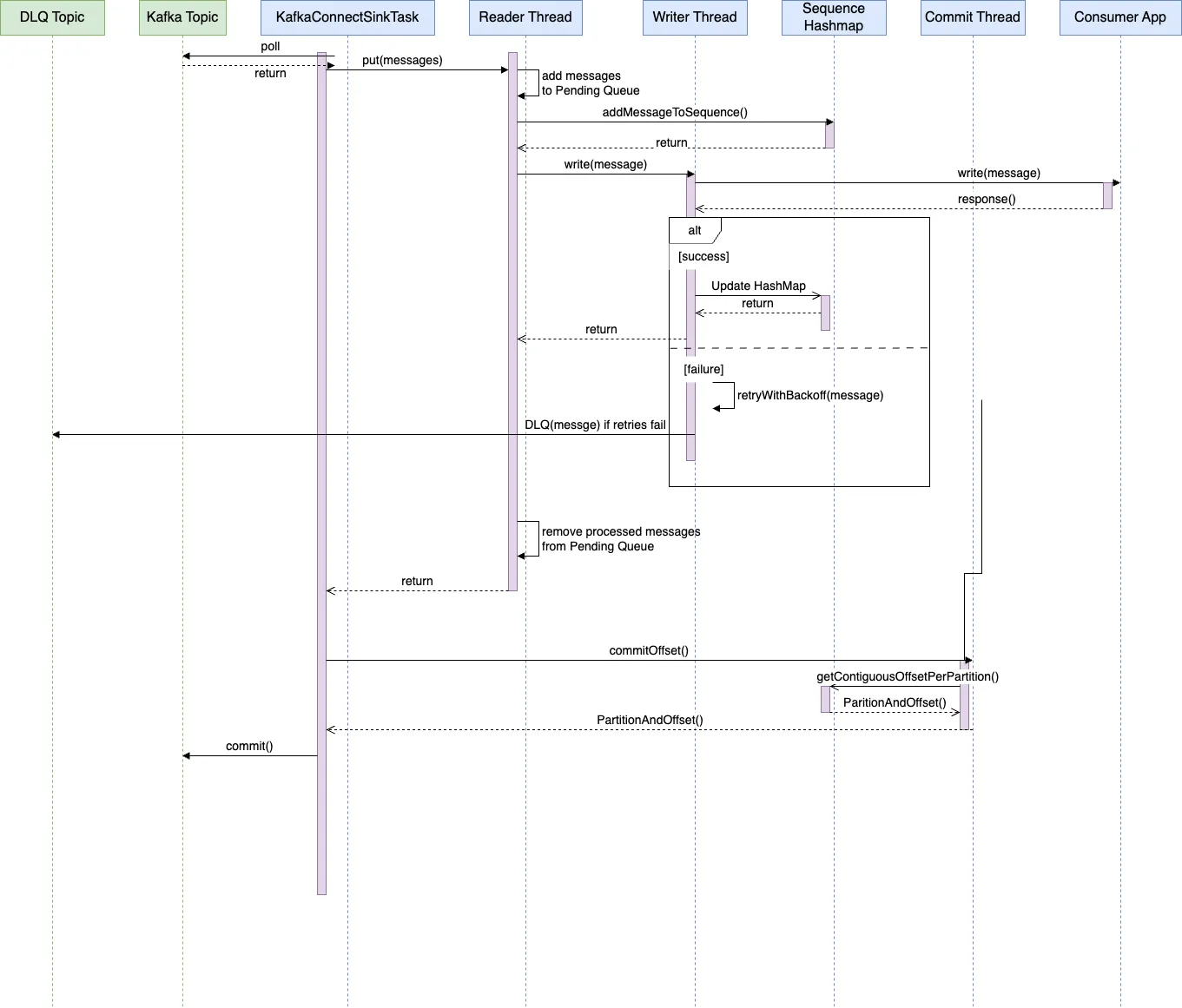
序列图就是用一系列调用来展示组件间如何互动的。
以下架构包含以下关键组件:
读者专区
读取线程的任务是处理传入的主题并向前进,当PendingQueue满时,它会施加反压以防止队列过载。
迭代器
顺序迭代器确保带有键的消息按顺序处理。它遍历_pendingQueue_中的所有消息,并跳过已经有相同键的消息已处于处理中的消息。被跳过的消息将在后续的轮询中处理,一旦较早的消息具有相同的键被处理。通过确保每个键最多只有一个消息处于处理中,MPS确保按键顺序的传递。
作者线程
写入线程(writer线程)是提供更高吞吐量的线程池的一部分。它的任务是可靠地将数据写到REST端点,并在重试用尽或收到不可重试的HTTP响应时将消息放入DLQ(死信队列)。
死信队列(也称为DLQ)
一个DLQ主题可以在每个Kafka集群中创建。消息处理写入线程最初会重试消息,以固定的次数,每次重试之间采用指数退避策略。如果重试失败,消息会被放入DLQ主题。应用程序可以稍后处理这些消息,或者直接丢弃。当消费者服务遇到故障,如超时,或遇到毒丸消息,如500 HTTP响应时,消息会被放入此队列。
客户服务
消费者服务(Consumer Service)是一个无状态的REST服务(无状态服务意味着它不保存任何客户端状态),供应用程序处理消息。此服务包含了原本由Kafka消费者应用程序处理的消息中的业务逻辑。采用这种新模型,Kafka的消费(MPS)可以从消息处理(消费者服务)中分离出来。在下面,您将找到任何消费者服务必须实现的REST API规范。
Kafka 偏移量提交线程(Offset Commit 线程)
Kafka 的偏移量提交作为一个单独的线程(即,offset_commit 线程)来实现。该线程每隔固定时间(例如,1 分钟)被唤醒,并提交最新的连续偏移量,这些偏移量是由 writer 线程成功处理的。
在这张图片中,偏移提交线程分别为了分区 0 和 1 提交偏移量 124 和 150。
API (应用程序接口)
MPS 被实现为 Kafka Connect 中的一个 sink 连接器。Kafka Connect 框架非常适合用于此场景,原因如下:
- 多租户:_ 可以在单个 Kafka Connect 集群上部署多个连接器
- DLQ处理:_ Kafka Connect 已经提供了基本的 DLQ 处理框架
- 提交操作:_ Kafka Connect 提供了方便的提交方法
- 内置的非功能特性 (NFR):_ Kafka Connect 提供了许多非功能特性(比如,可扩展性、可靠性)
MPS 已消除了因下游系统缓慢导致的重新平衡。它确保读取线程在 max.poll.interval.ms 指定的 5 分钟内将所有轮询列表中的消息放入 pendingQueue 中。我们看到的唯一重新平衡是由于 Kubernetes POD 重启或极为罕见的 Kafka 集群与 MPS 之间的网络迟缓。但对于小型消费者组来说,这些周期的持续时间几乎可以忽略不计,并不会超出处理 SLA(服务级别协议)。MPS 服务和 Kafka 集群应托管在同一云和区域中,以减少它们之间的网络相关问题。
合作处理毒丸,应用检测到它们并通过返回代码600和700通知MPS,按计划正常运作。
此解决方案的成本效益优势在两个领域得以实现。首先,在Kubernetes环境中,无状态消费者服务可以快速扩展,无需提前为假期或特定活动扩容。其次,Kafka集群大小不再受限于分区大小,可以真正根据吞吐量需求扩展,每个分区大约在5到10MB之间。
在每年为假期扩容Kafka集群后,Kafka管道中与重新均衡相关的问题和操作请求方面已经取得了显著进步。
突然增加的流量不再需要扩展Kafka分区,因为无状态消费者服务可以在Kubernetes环境中轻松自动扩展以应对消息峰值。Kafka(开源分布式流处理平台)。
感谢如果没有许多人的不懈帮助,这项工作是不可能成功的。其中一些人列于下:
(阿迪亚·阿塔莱,阿努杰·加格,查德拉普拉巴·拉朱普特,迪利普·贾斯瓦尔,古尔皮纳尔·辛格,赫曼特·塔马坎卡尔,卡梅什·桑加尼,马拉维卡·加达姆,迈亚库马尔·文纳纳拉南,彼得·纽康姆,拉朱·巴达姆,罗希特·查特尔,桑迪普·莫霍德,斯里卡南特·巴蒂普鲁,斯里拉姆·乌普普利里,提鲁瓦卢万·M·G.)





