
将数据集加载到数据仓库表中通常有几种模式:合并变更、仅插入或全表重置。历史上,存储过程通常被设计为参数化,从而工程师可以使用不同的参数多次执行相同的代码。这种方法已被证明是一种高效且可扩展的管理数据导入到分析平台的方式。
随着越来越多的客户将其传统的数据仓库工作负载迁移到Databricks,这种模式仍旧很普遍。工程师们使用笔记本和小工具来加载各种数据集,通过在运行时传递相应的值。假设有这样一个任务,需要使用100种不同的参数集来执行,而工程师们希望将这些任务并行处理,每次运行10个。Databricks需要高效地管理这些参数队列,并在资源池中执行任务。这时,Databricks的“For Each”任务就显得非常有用。
本文是更大系列文章中的一部分,这些文章讨论如何将存储过程转换到Databricks,主要是讲如何把它们迁移至Databricks工作流中的任务中。
例子作为基本示例,考虑一个每小时需要批量加载不同数据源的过程,使用追加模式(append-only模式)。在SQL Server中,这通常需要一个子存储过程,如下所示的脚本:
创建过程 AppendAllDataIntoTable
@source_table NVARCHAR(128),
@target_table NVARCHAR(128)
AS
BEGIN
SET NOCOUNT ON; -- 关闭行计数
DECLARE @insert_sql NVARCHAR(MAX);
-- 构建插入所有列的动态 SQL
SET @insert_sql = N'
INSERT INTO ' + QUOTENAME(@target_table) + N'
SELECT *
FROM ' + QUOTENAME(@source_table) + N';
';
-- 执行动态 SQL 语句
EXEC sp_executesql @insert_sql;
END
GO要执行上述过程,需要有一个父进程来调用存储过程。在这种情况下,这个过程会顺序执行。这个计划每小时运行一次的父过程看起来像这样:
EXEC AppendDataIntoTable 'Table1', 'TargetTableName1'; -- 把表1的数据添加到目标表1
EXEC AppendDataIntoTable 'Table2', 'TargetTableName2'; -- 把表2的数据添加到目标表2
EXEC AppendDataIntoTable 'Table3', 'TargetTableName3'; -- 把表3的数据添加到目标表3
EXEC AppendDataIntoTable 'Table4', 'TargetTableName4'; -- 把表4的数据添加到目标表4
EXEC AppendDataIntoTable 'Table5', 'TargetTableName5'; -- 把表5的数据添加到目标表5
EXEC AppendDataIntoTable 'Table6', 'TargetTableName6'; -- 把表6的数据添加到目标表6
EXEC AppendDataIntoTable 'Table7', 'TargetTableName7'; -- 把表7的数据添加到目标表7
EXEC AppendDataIntoTable 'Table8', 'TargetTableName8'; -- 把表8的数据添加到目标表8
EXEC AppendDataIntoTable 'Table9', 'TargetTableName9'; -- 把表9的数据添加到目标表9
EXEC AppendDataIntoTable 'Table10', 'TargetTableName10'; -- 把表10的数据添加到目标表10为了在Databricks上实现此过程,工程师会使用一个“ForEach”任务,将源表和目标表的名称作为参数传递给子任务。子任务将负责将数据插入到相应的目标表中,而ForEach任务将管理参数队列的处理。
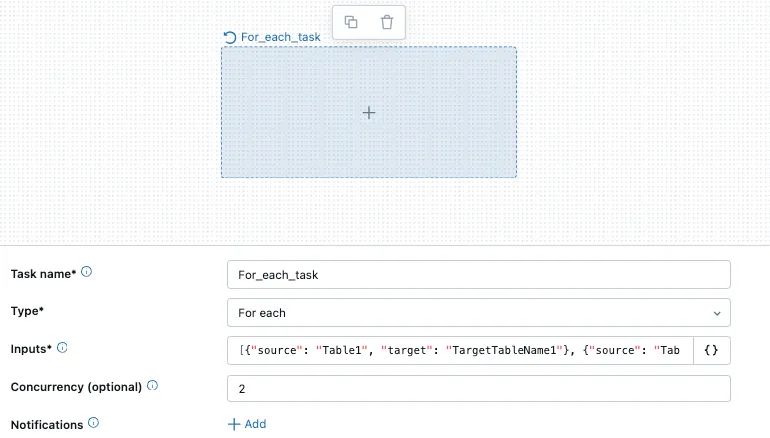
Databricks 每个任务的界面 表
一旦选择了“每个”任务,用户可以选择要运行的任务并传递参数给任务。在这种情况下,循环将执行一个单一的笔记本任务。
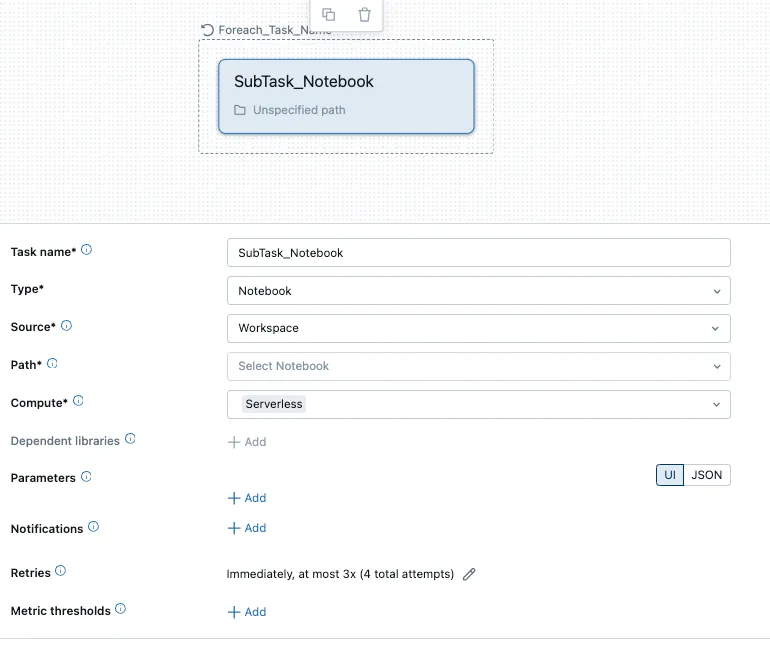
笔记本子任务UI表
笔记本中的代码会被转换为以下的PySpark代码,不过,用户也可以使用[execute immediate]来实现纯SQL。
# 定义源表和目标表的名字
dbutils.widgets.text("source_table_name", "")
dbutils.widgets.text("target_table_name", "")
source_table = dbutils.widgets.get("source_table_name")
target_table = dbutils.widgets.get("target_table_name")
# 将源表的数据追加到目标表中的 SQL 语句
append_sql = f"""
INSERT INTO {target_table}
SELECT * FROM {source_table}
"""
# 在 Databricks 中运行 SQL 语句
spark.sql(append_sql)如果需要处理更复杂的工作流,用户可以选择“运行作业”任务,这将在循环中运行一个作业任务。这将允许工程师在一个循环中执行多个彼此依赖的任务。
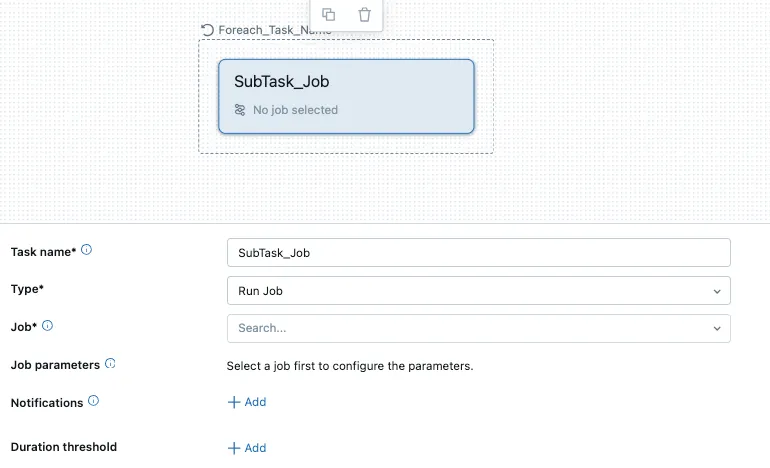
工作子任务UI
最后从像SQL Server这样的传统数据库迁移存储过程到Databricks可能看起来很令人生畏,但借助诸如“foreach”任务之类的工具,该过程变得更顺畅和可扩展。通过将这些工作流分解成可以并行运行的任务,工程师可以高效地处理批量数据加载,并充分利用Databricks的分布式计算资源。这种方法不仅使数据管道更现代化,还增强了灵活性和性能。
声明:以下是我的个人观点,不代表我所在公司的立场。





