
在当今数据驱动的世界中,组织从各种来源收集了大量原始数据。这些数据通常不一致、结构不佳,需要进行大量的预处理才能用于分析和决策。为了应对这些挑战,一个强大的数据标准化过程是必不可少的。
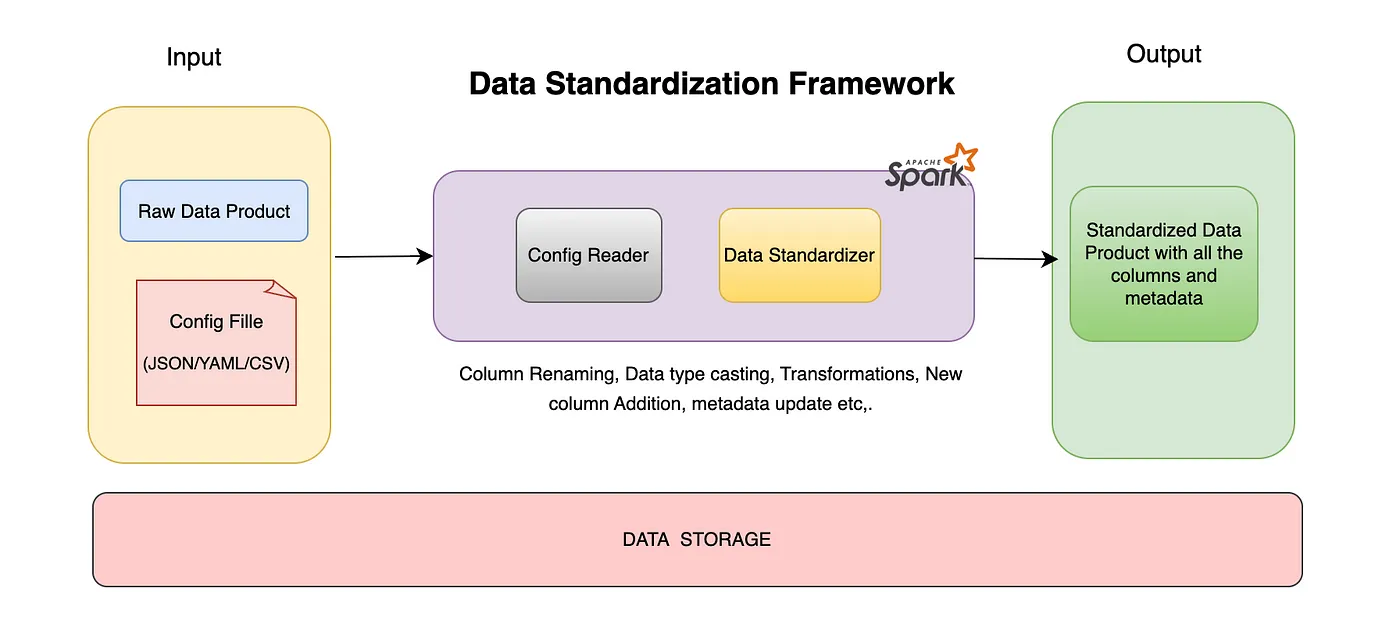
在这篇博客里,首先我们将简要了解数据标准化的重要性,然后介绍配置驱动方法的优点,最后是框架的逐步构建。我们还将看到如何将此框架应用于您的实际情境,并且它是如何有用的。
数据标准化是将来自不同来源的数据转换为统一格式的过程。这包括统一命名约定、数据类型、添加元数据等,以确保数据产品的一致性。
这里有几个原因说明为什么标准化原始数据很重要。
- 数据产品之间的一致性:标准化确保来自不同来源的数据遵循相同的结构,从而使集成和分析变得更加容易。
- 减少错误:通过使用一致的命名约定、正确数据类型和转换,数据处理和分析过程中出现错误的可能性大大降低。
- 增强数据的可用性:标准化的数据更容易用于各种分析和报告目的,从而产生更好的见解和商业决策。
- 可扩展性:随着数据量的增长,标准化的数据产品更容易管理、扩展,并适应新的数据源和字段。
我们的目标是构建一个通用框架,而不是为每个数据产品创建自定义脚本。这种配置驱动的方法使用配置文件来定义规则和映射关系,将标准化逻辑与应用代码解耦开来。这提升了系统的灵活性和可维护性。
本教程中,配置文件格式将是JSON,代码将使用PySpark和Spark SQL。数据产品将以Delta格式生成。
配置驱动方式的主要优点有:
- 灵活:无需改动应用程序代码即可轻松调整标准化规则。
- 可扩展性:使用Spark高效处理大规模数据集。
- 可维护性:将转换逻辑集中到配置文件中,使维护和更新变得更简单。
我们将要开发的功能包括:
- 列名的更新
- 数据转换
- 更新列的数据类型
- 更新列描述的元数据
- 添加新列
在开始之前,我想先提一下,数据标准化不仅仅局限于我们这里讨论的内容,它还可以涵盖更广泛的活动。数据标准化可能包括数据质量验证的添加,加入额外的元数据,数据产品的版本管理和其他增强数据完整性和可用性的其他流程。
开始设置!我们将使用Databricks社区版来编写代码和存储数据。对于数据存储,将使用集成在Databricks平台中的Databricks文件系统(DBFS),它是一个与Databricks平台集成的分布式文件系统。您可以根据需要将文件保存到其他位置,例如S3桶或ADLS,因为框架可以接受各种路径,所以它非常灵活。
这是我们要在这次演示中使用的配置文件结构说明 —
配置文件结构
data_product_name: <标准化后的数据产品名称>
raw_data_product_name: <原始数据产品名称>
schema:
source_columns: 源列(来自原始数据产品的直接列)
—raw_name: <原始数据产品中的列名>
standardized_name: <标准名称>
data_type: <所需的数据类型名称>
sql_transformation: <SQL转换规则(用Spark SQL编写)>
new_columns: 通过与其他数据产品连接获得的新列
—name: <要创建的新列名>
data_type: <所需的数据类型名称>
sql_transformation: <SQL转换规则(用Spark SQL编写)>
metadata: 在所有列添加后分配的元数据
column_descriptions:
<列名称>: <描述>
我们要对原始数据产品——supplier进行标准化。
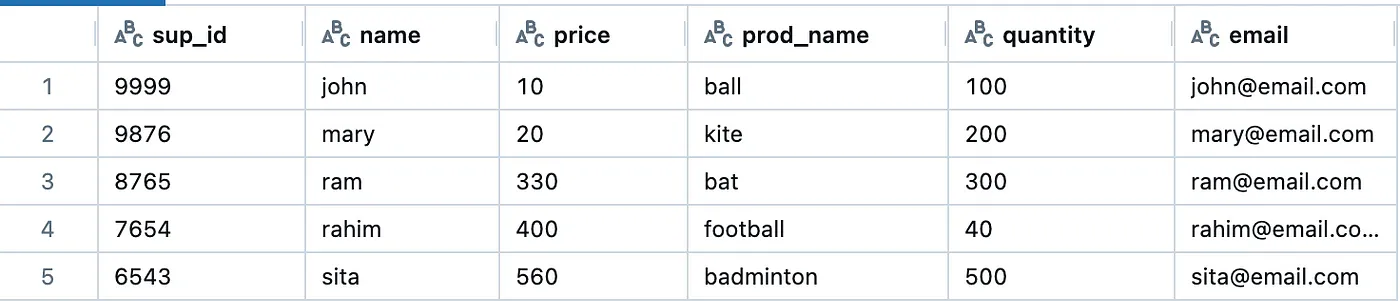
数据提供商(原始数据)
以下是另一个标准化数据产品——Product,我们将使用它来增加新的一列。
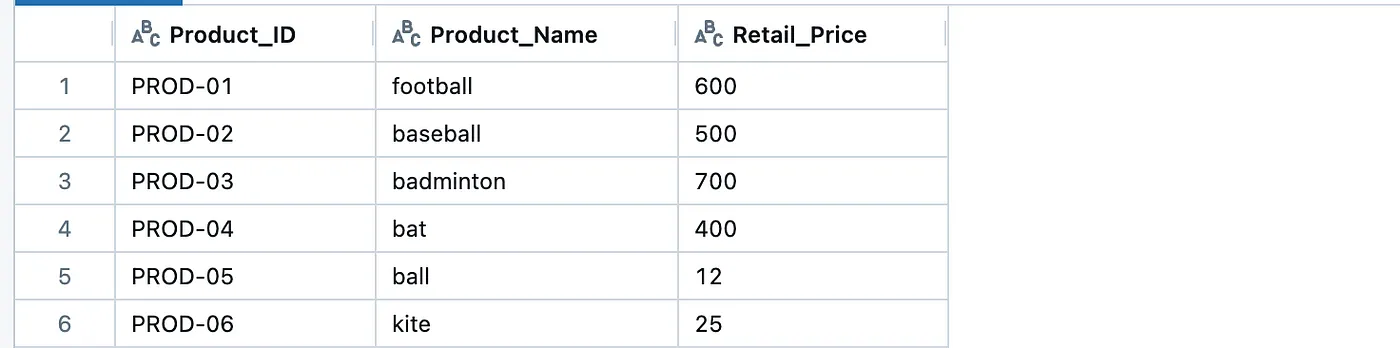
其他标准化的数据产品
供應商 如下所示,基于上述结构的 JSON 配置文件:
{
"data_product_name" : "Product_Supplier",
"raw_data_product_name" : "supplier",
"schema" : {
"source_columns" : [
{
"raw_name" : "sup_id",
"standardized_name" : "Supplier_ID",
"data_type" : "string",
"sql_transformation" : "CONCAT('SUP', '-' , sup_id)"
},
{
"raw_name" : "name",
"standardized_name" : "Supplier_Name",
"data_type" : "string",
"sql_transformation" : ""
},
{
"raw_name" : "price",
"standardized_name" : "Purchase_Price",
"data_type" : "int",
"sql_transformation" : ""
},
{
"raw_name" : "prod_name",
"standardized_name" : "Product_Name",
"data_type" : "string",
"sql_transformation" : ""
},
{
"raw_name" : "quantity",
"standardized_name" : "Purchase_Quantity",
"data_type" : "int",
"sql_transformation" : ""
},
{
"raw_name" : "",
"standardized_name" : "Total_Cost",
"data_type" : "int",
"sql_transformation" : "price * quantity"
}
],
"new_columns" : [
{
"name" : "Product_ID",
"data_type" : "string",
"sql_transformation" : "MERGE INTO delta.`{temp_std_dp_path}` dest USING delta.`dbfs:/FileStore/project/Product` src ON dest.Product_Name = src.Product_Name WHEN MATCHED THEN UPDATE SET dest.Product_ID = src.Product_ID"
}
]
},
"column_sequence_order" : [
"Supplier_ID", "Supplier_Name", "Product_ID", "Product_Name", "Purchase_Price", "Purchase_Quantity", "Total_Cost"
],
"metadata" : {
"column_descriptions" : {
"Supplier_ID" : "产品供应商的唯一标识符",
"Supplier_Name" : "供应商名称",
"Purchase_Price" : "供应商销售产品的价格",
"Product_Name" : "产品名称",
"Purchase_Quantity" : "供应商拥有的产品数量",
"Total_Cost" : "在给定的采购价格下购买特定数量商品的总花费",
"Product_ID" : "产品的唯一标识符"
}
}
}写入 supplier 原始数据点(DP)和 Product 数据点(DP),以增量格式到你选择的位置。并将 JSON 配置文件上传至指定路径。
我们将遵循全量加载流程(截断加载)。因此,所有的步骤都将在临时/阶段区域中执行,然后将数据写入实际的标准DP路径。
开发框架 —首先,我们将定义配置读取器的接口或合约,以便我们根据不同的配置结构可以创建自己的配置读取器类。例如,我们的配置是以 JSON 格式存在的,但如果我们要使用 YAML 格式的配置,我们只需继承以下抽象类即可创建我们的配置读取器——
class ConfigReaderContract(ABC): # 配置读取契约类
@abstractmethod
def read_source_columns_schema(self) -> spark.DataFrame: # 读取源列模式
pass
@abstractmethod
def read_new_columns_schema(self) -> spark.DataFrame: # 读取新列模式
pass
@abstractmethod
def read_column_descriptions_metadata(self) -> dict: # 读取列描述元数据
pass
@abstractmethod
def read_column_sequence_order(self) -> list[str]: # 读取列顺序
pass下面是我们实现的 ConfigReader 类
class ConfigReader(ConfigReaderContract):
def __init__(self, config_path):
self.config_df = spark.read.option("multiLine", True).json(config_path)
def read_source_columns_schema(self):
exploded_df = self.config_df.select(explode(self.config_df["schema"].source_columns).alias("source_columns"))
source_columns_schema_df = exploded_df.selectExpr(
"source_columns.raw_name as raw_name",
"source_columns.standardized_name as standardized_name",
"source_columns.data_type as data_type",
"source_columns.sql_transformation as sql_transformation"
)
return source_columns_schema_df
def read_new_columns_schema(self):
exploded_df = self.config_df.select(explode(self.config_df["schema"].new_columns).alias("new_columns"))
new_columns_schema_df = exploded_df.selectExpr(
"new_columns.name as name",
"new_columns.data_type as data_type",
"new_columns.sql_transformation as sql_transformation"
)
return new_columns_schema_df
def read_column_descriptions_metadata(self):
metadata_df = self.config_df.select("metadata.column_descriptions").alias("列描述")
descriptions_row_obj = metadata_df.first()["列描述"]
return descriptions_row_obj.asDict()
def read_column_sequence_order(self):
return list(self.config_df.first()["column_sequence_order"])现在终于到了,我们来看看我们DataStandardizer类的实现部分。然后我们将一步步了解每个方法。
class 数据标准化类:
def __init__(self, raw_dp_path, temp_std_dp_path, std_dp_path):
self.raw_dp_path = raw_dp_path
self.temp_std_dp_path = temp_std_dp_path
self.std_dp_path = std_dp_path
def 根据源列创建临时标准化数据集(self, source_columns_schema_df):
source_columns_schema_df.createOrReplaceTempView("source_columns_config_table")
select_query_sql = f"""
SELECT
concat(
"SELECT ",
array_join(collect_list(select_expression), ", "),
" FROM delta.`{self.raw_dp_path}`"
) as select_query
FROM (
SELECT
CASE
WHEN sql_transformation = "" THEN concat("CAST(", concat("`", raw_name, "`"), " AS ", data_type, ") AS ", standardized_name)
ELSE concat("CAST(", sql_transformation, " AS ", data_type, ") AS ", standardized_name)
END as select_expression
FROM source_columns_config_table
)
"""
df = spark.sql(select_query_sql)
select_query = df.first()["select_query"]
create_sql_query = f"CREATE OR REPLACE TABLE delta.`{self.temp_std_dp_path}` as ( " + select_query + ")"
spark.sql(create_sql_query)
def 在临时数据集中添加新列(self, new_columns_schema_df):
new_columns_schema_df_rows = new_columns_schema_df.collect()
for row in new_columns_schema_df_rows:
add_new_columns_sql = f"ALTER TABLE delta.`{self.temp_std_dp_path}` ADD COLUMN {row['name']} {row['data_type']}"
sql_transformation = row["sql_transformation"].replace("{temp_std_dp_path}", self.temp_std_dp_path)
spark.sql(add_new_columns_sql)
spark.sql(sql_transformation)
def 更新列描述(self, column_descriptions_dict):
for column_name, description in column_descriptions_dict.items():
column_description_update_sql = f"ALTER TABLE delta.`{self.temp_std_dp_path}` CHANGE COLUMN {column_name} COMMENT '{description}';"
spark.sql(column_description_update_sql)
def 将数据移至标准数据集依据列顺序(self, column_sequence_order):
temp_std_df = spark.read.format("delta").load(self.temp_std_dp_path)
temp_std_df = temp_std_df.select(column_sequence_order)
temp_std_df.write.option("mergeSchema", "true").format("delta").mode("overwrite").save(self.std_dp_path)
def 执行(self, config_reader):
print("原始数据框:")
raw_df = spark.read.format("delta").load(self.raw_dp_path)
display(raw_df)
source_columns_schema_df = config_reader.read_source_columns_schema()
self.根据源列创建临时标准化数据集(source_columns_schema_df)
new_columns_schema_df = config_reader.read_new_columns_schema()
self.在临时数据集中添加新列(new_columns_schema_df)
column_descriptions_dict = config_reader.read_column_descriptions_metadata()
self.更新列描述(column_descriptions_dict)
column_sequence_order = config_reader.read_column_sequence_order()
self.将数据移至标准数据集依据列顺序(column_sequence_order)
print("标准化数据框:")
std_df = spark.read.format("delta").load(self.std_dp_path)
display(std_df)
print("标准化数据框的模式信息:")
std_df.printSchema()
display(spark.sql(f"DESCRIBE TABLE delta.`{self.std_dp_path}`"))DataStandardizer 类包含 3 个属性,分别是 raw_dp_path(原始数据产品路径),temp_std_dp_path(用于标准化暂存的路径)和 std_dp_path(用于保存标准化数据产品的路径)。具体方法如下——
运行代码来得到标准化的DP —1.
create_temp_std_dp_with_source_columns—此方法创建带有直接来自源数据产品的列(即源列)的标准化数据产品的初始版本。
2.add_new_columns_in_temp_std_dp—将临时标准化数据产品更新为包含与其他数据产品连接后获得的新列。
3.update_column_descriptions_metadata—此方法更新每个已创建列的描述。
4.move_data_to_std_dp—这是最终步骤,将临时或暂存区域中的delta表复制到标准化数据产品的路径中。
5.run—此方法协调上述所有步骤的执行。它接收一个config_reader实例,该实例是使用ConfigReaderContract类实现的。
以下为运行框架在supplier数据产品上的代码,如下所示。
# 按照您的用例定义所有路径
raw_dp_path = "dbfs:/FileStore/project/supplier"
std_dp_path = "dbfs:/FileStore/project/Product_Supplier"
temp_std_dp_path = "dbfs:/FileStore/project/Product_Supplier_temp"
config_path = "dbfs:/FileStore/project/supplier_config.json"
# 初始化配置读取器和数据标准化器
config_reader = ConfigReader(config_path)
data_standardizer = DataStandardizer(
raw_dp_path=raw_dp_path,
temp_std_dp_path=temp_std_dp_path,
std_dp_path=std_dp_path
)
# 运行 DataStandardizer 类
data_standardizer.run(config_reader)输出如下——
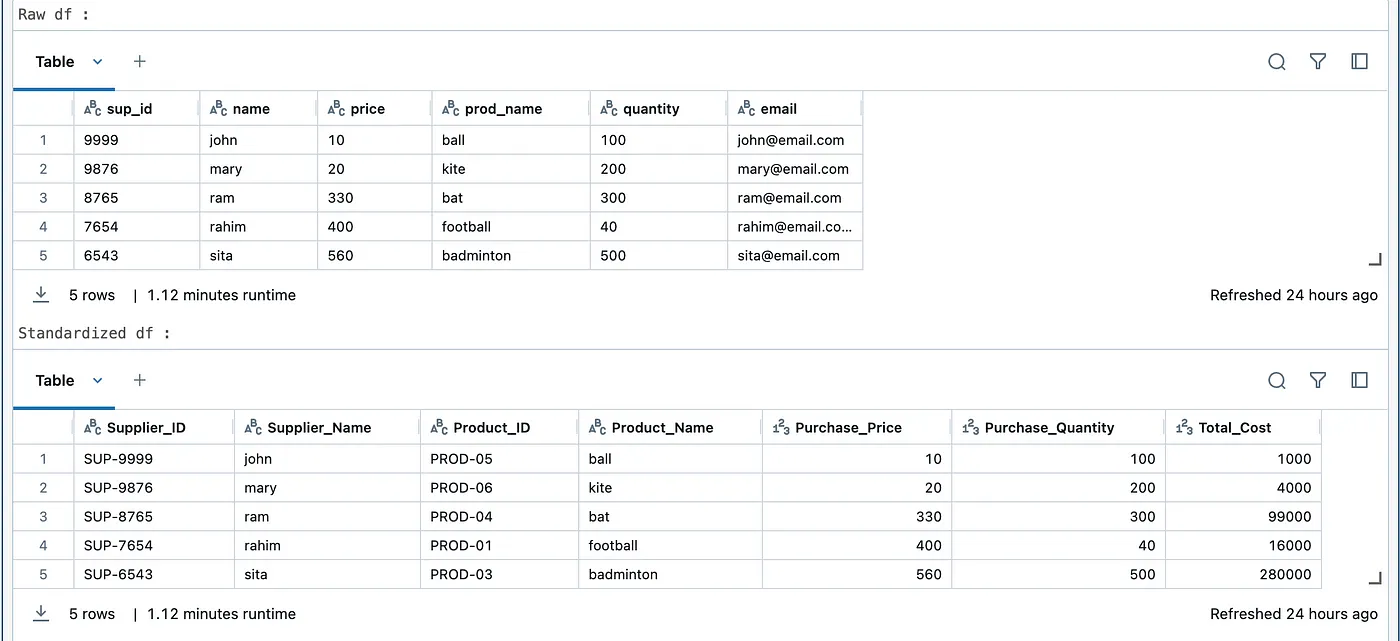

在上面的图片中,我们可以看到Standardized DP包含配置文件中提到的所有列,并且每列都有描述。
比如说,_sup_id 列名在原始数据产品中重命名为 _Supplier_ID,并在每个值前加上所需的前缀(SUP),比如每个值都会变成 SUP123。描述元数据——_Unique Identifier of the supplier of a product 也相应地更新了。
还通过将 _price 和 _quantity 从原始数据产品相乘,添加了 _Total_Cost 列。通过与另一个名为 _Product 的数据产品进行连接,添加了一个新列 _Product_ID。
本文中使用的代码可以在以下Github仓库中查看。
总之,
基于Spark的配置驱动数据标准化框架提供了一种将原始数据转化为高质量且标准化的数据产品的强大且可扩展的方法。通过使用配置文件来规定标准化规则,该框架提供了灵活性、一致性和易于维护的优点,允许在不修改核心代码的情况下进行动态调整。其可扩展性使得它能够轻松适应数据质量验证、数据产品版本控制以及其他元数据增强等新增功能,进一步扩大其应用范围。
希望你喜欢这篇博客。欢迎在评论区提问并分享你的想法,这会帮助我做得更好。




