

确保开发环境和生产环境保持一致是开发人员必须遵守的重要原则之一。
在 Databricks 中做到这一点很不容易,因为找不到完美的解决办法。但是我们可以尽量找到妥协最少的那个。
在这篇文章里,我会探讨几种选择。
- Databricks 笔记本文件
- VS Code + Databricks 扩展 + 虚拟环境
- VS Code + 使用自定义 Docker 镜像(devcontainers)
你可能到处都会看到,更常见(也是最具争议性)的方法是使用Databricks笔记本界面。我们来看看如何最好地做到这一点。
第一步:使用 Git
首先,不要直接在工作空间创建一个笔记本。相反,首先创建一个由该项目所在 Git 仓库初始化的 Git 目录。你可以通过将你的 Git 账户连接到 Databricks 来完成身份验证。
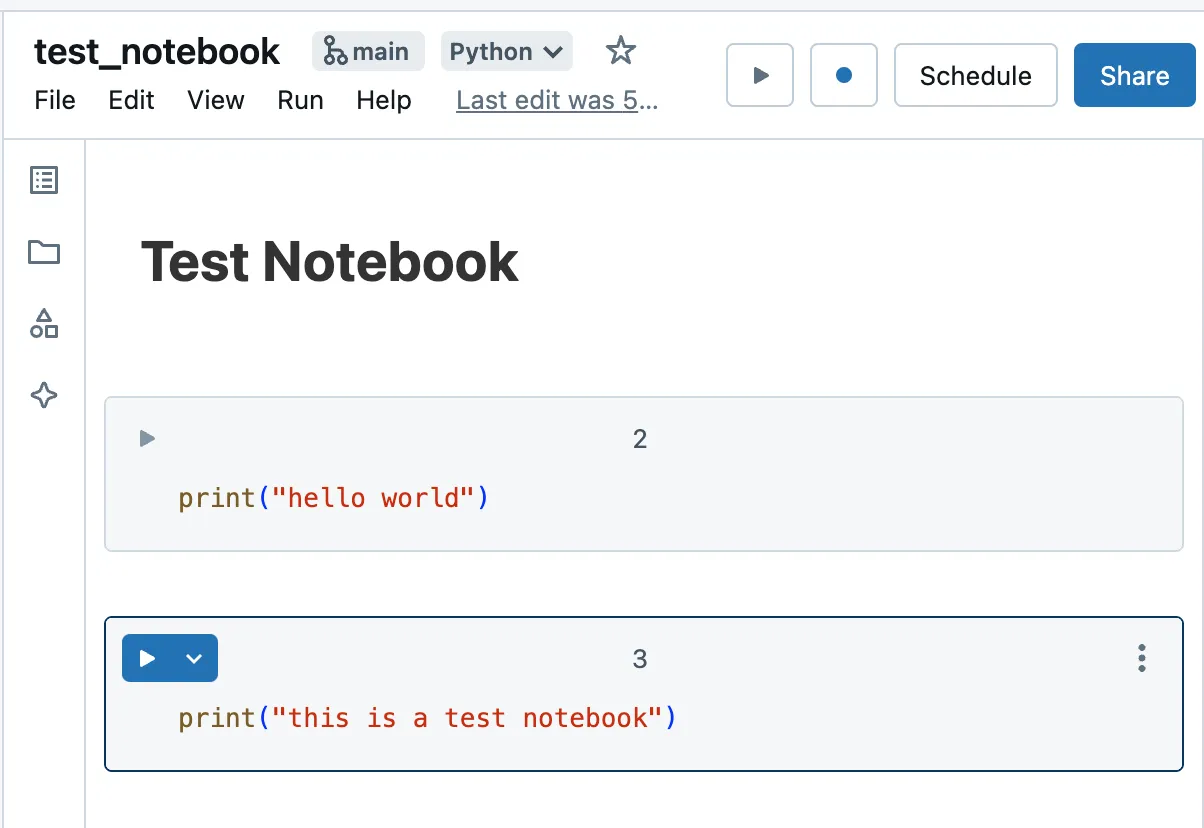
创建文件夹之后,您可以创建一个笔记本。请注意,Databricks 笔记本默认保存为一个 Python 文件。该文件的第一行会是“# Databricks notebook source”——这就是它被认作 Databricks 笔记本的原因。单元格之间通过包含“# COMMAND — — — — —”的行进行分隔。
例子 Databricks 笔记本:
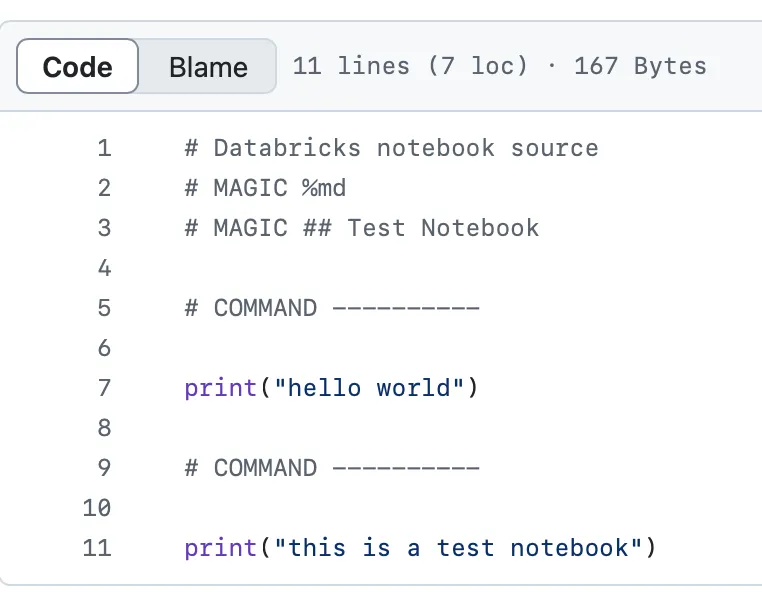
这就是它在代码库中保存的方式:
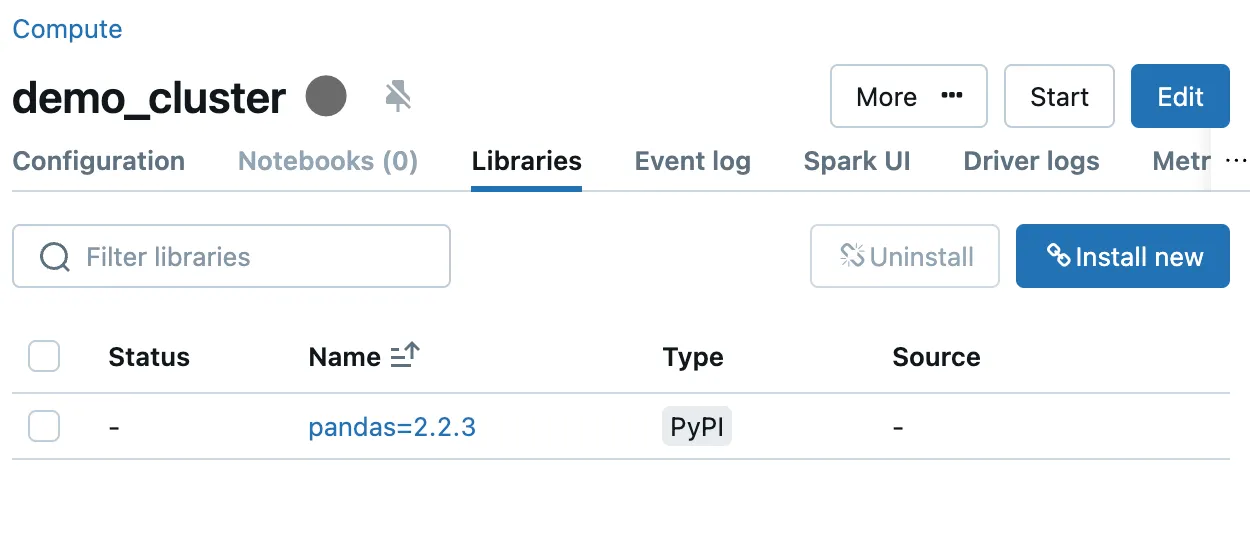
第二步:个性化环境
运行一个 Databricks 笔记本,您需要选择一个集群。我们假设使用经典计算并选择运行时 15.4 LTS。该运行时自带一些预安装的库:更多详情请参阅此链接。这些预安装的库可能不完全符合您的项目需求。
笔记本自带的环境并不干净。如果你需要特定版本的某些库(例如,比运行时提供的pandas版本更新),你得在现有的环境中安装这些库。
要在Databricks笔记本中安装特定库,请使用%pip命令。例如:这使您可以从PyPi或从工作区或卷中的wheel进行安装。更多详细步骤请参考官方文档:https://docs.databricks.com/en/libraries/notebooks-python-libraries.html

您也可以通过修改集群配置来安装库。完成之后,这些库将在任何使用该集群的笔记本中可用。可以使用相对路径导入项目模块。无法以可编辑形式安装包。
步骤3:保存更改
当你修改一个项目时,确保提交更改并将其推送到你正在操作的 Git 分支。这可以确保你的工作受到版本控制。
缺点:- 这并不是一个集成开发环境(IDE)。虽然现在可以在Databricks笔记本中使用调试器,但你不能享受到IDE的所有优势,比如使用代码检查工具和格式化工具,更别提在这种环境中打包和单元测试代码会很艰难了。
- 合并冲突。解决Git文件夹中的合并冲突可能会很困难,并且也无法使用预提交钩子。
- 代码质量风险。如果团队选择这种方法在Databricks上进行开发,最终代码质量可能会受到影响。
- 环境一致性保障。这是确保在Databricks上开发并在生产中作为工作流安排的笔记本运行代码时保持环境一致性的唯一方法。
- 高内存需求。如果你的代码对驱动节点有高内存需求,且无法对数据进行采样(例如,将pySpark DataFrame加载到pandas中以训练scikit-learn模型),这是唯一的开发途径。
因此,由于我不太喜欢用笔记本,我探索了在Databricks上开发的其他所有方式。
让我们转而使用安装了Databricks插件的VS Code。
2. VS Code + Databricks 扩展插件 + 虚拟环境(Virtual Environment)许多开发者更喜欢使用像VS Code这样的Python IDE来编写代码。首先,你需要创建一个虚拟环境。在定义用于工作流中运行代码的集群时,必须指定Databricks运行时。如前所述,Databricks运行时自带特定版本的Python以及预装的一些库。
问题就来了:你如何创建一个虚拟环境,让开发和生产环境保持一致?答案是:你无法做到完全同步,但你可以创建一个近似环境。通过加入集成测试,你可以确保在生产环境中一切都能按预期工作。
第一步:搭建虚拟环境(venv)
你可能会想:尝试在一个与运行时Python版本相匹配的虚拟环境中安装所有运行时Python依赖。这很可能会失败,因为无法解析依赖关系。这取决于你使用的是什么操作系统。因此,只需从一个普通的虚拟环境中开始,并仅指定你需要的包的具体版本。
让我们从下面这个假设开始,我们的项目首先有一个非常简洁的 pyproject.toml 文件,其中指定了这些依赖:
[项目配置]
name = "demo"
version = "0.0.1"
description = "演示项目描述"
requires-python = ">=3.11"
dependencies = ["mlflow==2.16.0",
"numpy==1.26.4",
"pandas==2.2.2"]
[可选依赖]
开发 = ["databricks-connect>=15.4.1, <16",
"databricks-sdk>=0.32.0, <0.33",
"ipykernel>=6.29.5, <7",
"pip>=24.2"]步骤2:安装并固定依赖项
让我们使用UV来创建一个虚拟环境,并安装所有需求及其可选依赖项。我们会发现安装的包比我们指定的要多——这些是中间依赖。我们使用_uv lock_命令将其锁定,并将平台无关的锁定文件提交到代码库,这样所有开发人员就可以使用相同版本的包了。
uv venv -p 3.11.0 .venv
source venv/bin/activate
uv pip install -r pyproject.toml - 安装所有额外的依赖
uv lock这些命令用于设置Python环境并安装必要的依赖项。
第三步:本地运行代码,并在Databricks上运行:
如果我们想运行一个包含Spark代码的Python脚本。简单来说,我们可以使用Databricks Connect(这是一种可选的依赖方式)来运行该脚本。Spark相关的代码会在集群上运行,而其他代码则会在本地运行。更多详情请参阅文档:https://docs.databricks.com/en/dev-tools/databricks-connect/index.html (这里)。
所以,我们可以在本地运行代码。但怎样才能在Databricks的工作流程中执行它呢?我们不能在集群上安装所有本地需求。在本地虚拟环境中安装运行时依赖也会遇到同样的问题。
这意味着我们只能再次安装高阶需求——我们可以将它们指定为任务所需的条件。我们必须记住,我们不是在空环境中安装它们,并且运行时所需的中间包不会随时间改变(除了偶尔进行的错误修复和安全更新)。因此,只指定高阶需求即可确保环境的稳定性。
为了确保本地开发的代码在工作流中以同样的方式运行,我们需要在一部分数据上进行集成测试,在Databricks上运行代码。
缺点:- 只能大致创建环境可以在本地创建。
- 兼容性问题。 某些命令在使用dbconnect时可能无法正常运行(例如,包含table_changes的SQL语句),我在使用feature-engineering包时也遇到了一些问题,该包在笔记本环境中运行正常。
- 高内存需求。 如果您的代码在本地运行需要占用大量内存,此选项可能无法工作。
- 您将享受到IDE的所有好处。
- 最佳实践。在团队中更易于推广最佳编码实践。
还有一个选项尽量减少妥协,但这可能是最难处理的选择。
第一步:创建一个 Dockerfile
一个 Databricks 集群可以通过一个 Docker 镜像来启动。如下所示的 Docker 文件可以用于生成这个镜像:
FROM databricksruntime/python:15.4-LTS
ARG PROJECT_DIR=/project
RUN pip install uv==0.4.20
WORKDIR ${PROJECT_DIR}
COPY pyproject.toml ${PROJECT_DIR}/
RUN uv pip install --python /databricks/python3 -r pyproject.toml有几点需要注意:
- 基础镜像是
databricksruntime/python:15.4-LTS,这与我们选择的运行时相匹配。 - 项目依赖需安装在
/databricks/python3文件夹中,这是一个已预装某些库的现有Python环境。我们在此基础上安装所需的库。
步骤2:配置devcontainer
因为我们修改了现有的环境,直接复现就不是那么直接了。而是使用这个 Dockerfile 来创建一个 devcontainer,然后在 devcontainer 里开发。
这是我们早期关于dev容器的一篇文章:这篇文章。在dev容器中设置Databricks扩展非常重要,因为我们将像之前讨论的一样在此基础上进行开发。我们将在dev容器中像之前一样开发Databricks项目。
在设置好开发容器并配置好扩展之后,你需要创建一个虚拟环境。为此,请指向特定于 Databricks 的 Python 安装,而不仅仅是通用的 Python 3.11 版本。
uv venv -p /databricks/python3 .venv如果需要对此命令进行解释或注释,可以这样写:此命令用于在指定路径下创建一个Python 3虚拟环境。
步骤3:在使用它来启动一个集群之前,先创建一个镜像
你现在可以像往常一样编程,开发完成后可以构建并推送该镜像到Docker仓库。
运行以下Docker命令来构建和推送marvelousmlops/databricks_docker:latest镜像到Docker仓库:
docker build -t marvelousmlops/databricks_docker:latest . 其中,-t 选项用于设置镜像的标签。
docker push marvelousmlops/databricks_docker:latest此命令用于将构建好的镜像推送至Docker仓库中。
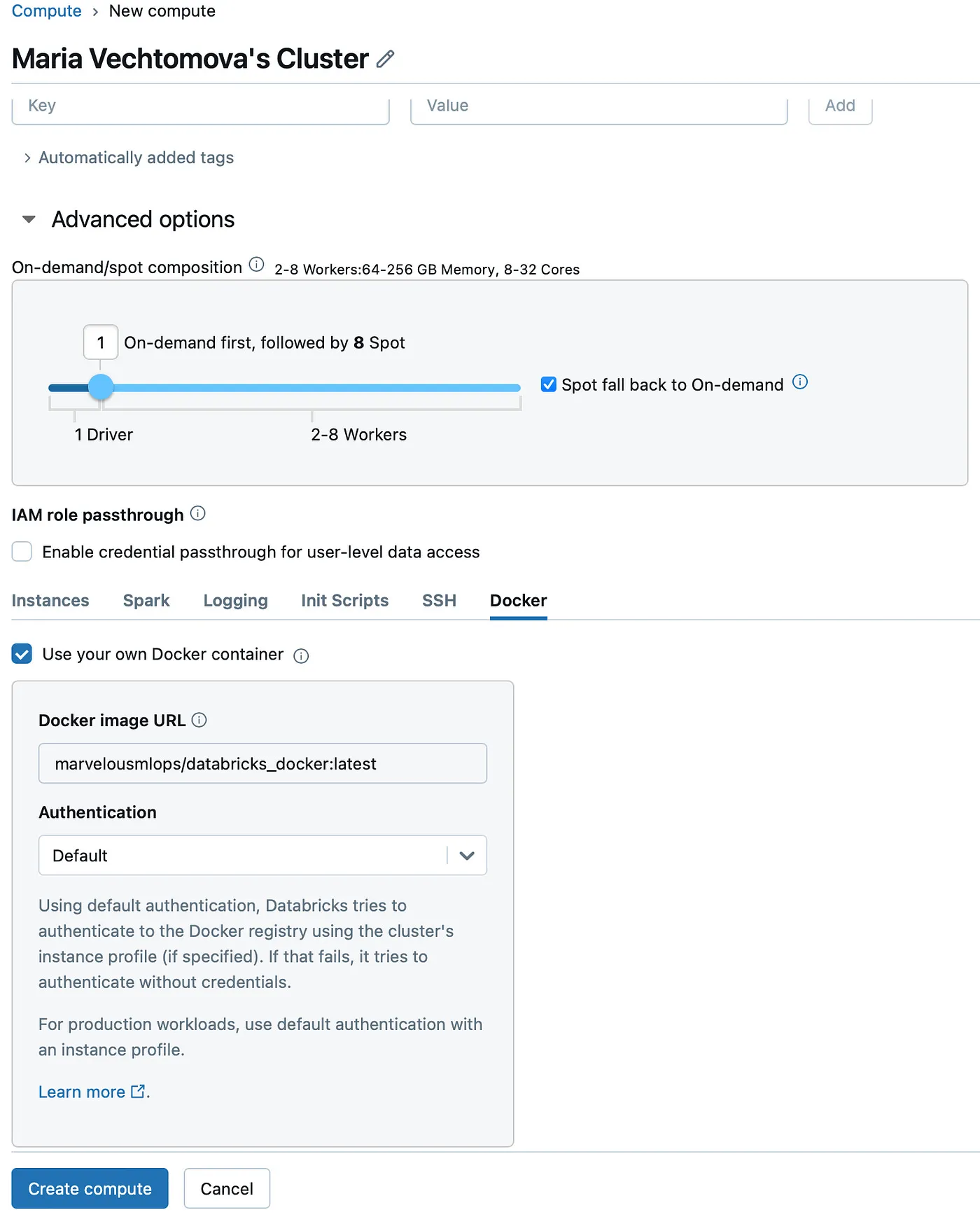
然后用这张图片初始化集群,这里有一个通过UI初始化的一个例子(当然,你也可以在Databricks作业中使用它,并且可以通过编程方式来设置)。如果Docker选项卡没有显示,工作空间管理员可以通过运行CLI命令来开启它:
databricks workspace-conf set-status --json '{"enableDcs": "true"}'设置工作区配置的状态为启用Dcs,使用命令 databricks workspace-conf set-status --json '{"enableDcs": "true"}'
享受啦!
不足之处:- 可能会比较慢。 这个选项需要一台配置较高的机器。
- 可能存在兼容性问题,Databricks扩展有时可能无法正常工作。
- 相当复杂。
- 可能在本地正常运行,但在Databricks上会出问题——因为Databricks有自己的特殊设置。调试起来非常困难。
每种在 Databricks 上开发的方法都有其优势和劣势。Databricks 笔记本提供了一致的生产环境体验,但缺少 IDE 的所有功能。使用 VS Code 和虚拟环境可以提供更高级的编码特性,但只能大致模拟生产环境。使用 Docker 提供更多控制,但会增加一些复杂性。
通过了解每种方法的利弊,您可以为团队和项目需求选择最适合的发展策略。
uv: 用 Rust 编写的 Python 包管理工具,uv 是一个极其快速的 Python 包安装器和管理器,旨在作为 pip 和 pip-tools 的直接替代品。 GitHub - astral-sh/uv: 一个极快的 Python 包和项目管理器,用 Rust 编写 - astral-sh/uv



