

原图来源:由Sven Mieke在Unsplash / 变换图片:Flux.1,提示:“老虎的照片”
这篇文章教你如何根据现有图像和文本提示生成新的图像。这项技术在一篇名为SDEdit: 基于随机微分方程的引导图像合成与编辑的论文中介绍,并在此应用于FLUX.1。
首先,我们先来简单介绍一下潜在扩散模型的工作原理。然后,我们将看到SDEdit如何修改反向扩散过程,以根据文本提示编辑图像。最后,我们将提供运行整个流程的代码。
背景:潜在扩散潜扩散是在较低维度的潜在空间中进行扩散过程。我们来定义一下潜在空间:
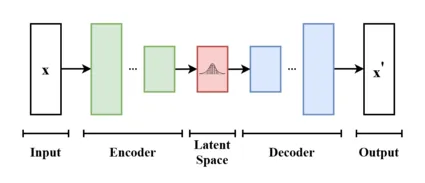
来源:维基百科(https://en.wikipedia.org/wiki/Variational_autoencoder)
一种变分自编码器(VAE)将图像从人类能理解的RGB颜色、高度和宽度的像素空间投影到一个更小的潜在空间。这种压缩保留了足够的信息,以便以后可以重建图像。扩散过程是在这个潜在空间中进行的,因为这样计算成本更低,而且对像素空间中的无关细节不太敏感。
现在我们来解释一下潜在扩散模型:
参考来源:https://en.wikipedia.org/wiki/Diffusion_model
扩散过程可以分为两个步骤。
- 前向扩散:一个计划的、非学习性的过程,它在多步中将自然图像转化为纯噪音。
- 逆向扩散:一个学习性的过程,它从纯噪音中重构出自然图像的样子。
注意噪声是添加到潜在空间中的,并且遵循从弱到强的特定流程,在正向过程中,从弱到强逐渐增强。
噪声会按照特定的进度表添加到潜在空间中,从在前向扩散过程中逐渐增强的弱噪声到强噪声。这种多步骤的方法简化了网络的任务,相比GAN等一次性生成方法更容易处理。反向过程通过最大化似然性来学习,这使得优化过程比对抗损失更容易。
文本预处理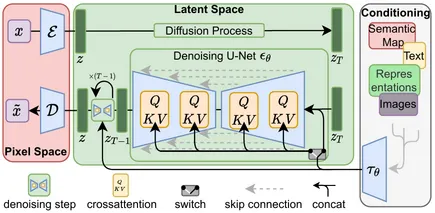
来源链接: https://github.com/CompVis/latent-diffusion
生成还会受到额外信息(比如文本提示词)的影响,这可以是你提供给稳定扩散模型(如Stable Diffusion)或Flux.1模型的提示。这段文本作为“提示”在扩散模型学习反向过程时被包含进去。文本通过类似CLIP或T5的模型进行编码,然后输入到UNet或Transformer中,以指导模型回到被噪音干扰的原始图像。
SDEdit (SD编辑)SDEdit的理念很简单:在反向过程中,它不是像上图中的“步骤1”那样从全随机噪声开始,而是从输入图像加上一个缩放后的随机噪声开始,然后执行常规的反向扩散过程。整个过程如下:
- 加载输入图像,并对输入图像进行预处理,使其适合 VAE。
- 将其通过 VAE 并采样一个输出(VAE 返回一个分布,所以我们需要采样以获得该分布的一个实例)。
- 选择反向扩散过程的起始步数 t_i。
- 根据 t_i 采样一些噪声并将其添加到潜在图像表示中。
- 使用带有噪声的潜在图像表示和提示词从 t_i 开始反向扩散过程。
- 将结果通过 VAE 投影回像素空间。
- 搞定!
这里是使用diffusers运行此工作流。
首先,你需要安装依赖库 ▶️
pip install git+https://github.com/huggingface/diffusers.git optimum-quanto从git仓库安装特定包
注释:从git仓库安装特定包,命令格式为pip install git+<git仓库链接> <包名>。
目前,你需要从源代码安装diffusers,因为pypi上目前还无法安装此功能。
接下来,加载 FluxImg2Img 管道 ▶️
import os
from diffusers import FluxImg2ImgPipeline
from optimum.quanto import qint8, qint4, quantize, freeze
import torch
from typing import Callable, List, Optional, Union, Dict, Any
from PIL import Image
import requests
import io
MODEL_PATH = os.getenv("MODEL_PATH", "black-forest-labs/FLUX.1-dev")
pipeline = FluxImg2ImgPipeline.from_pretrained(MODEL_PATH, torch_dtype=torch.bfloat16)
quantize(pipeline.text_encoder, weights=qint4, exclude="proj_out")
freeze(pipeline.text_encoder)
quantize(pipeline.text_encoder_2, weights=qint4, exclude="proj_out")
freeze(pipeline.text_encoder_2)
quantize(pipeline.transformer, weights=qint8, exclude="proj_out")
freeze(pipeline.transformer)
pipeline = pipeline.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(100)此代码加载了管道模型,并对管道的某些部分进行量化,从而使它能够适应Colab中可用的L4 GPU。
现在,我们来定义一个实用函数来以正确的尺寸加载图片而不变形
def resize_image_center_crop(image_path_or_url, target_width, target_height):
"""
根据中心裁剪调整图像大小以保持宽高比。处理本地文件路径和网址。
参数:
image_path_or_url: 图片文件的路径或网址。
target_width: 输出图像的期望宽度。
target_height: 输出图像的期望高度。
返回:
返回一个包含调整大小后的图像的PIL图像对象,或者如果出错则返回None。
"""
try:
if image_path_or_url.startswith(('http://', 'https://')): # 检查是否为网址
response = requests.get(image_path_or_url, stream=True)
response.raise_for_status() # 对于错误的响应(4xx或5xx)抛出HTTPError
img = Image.open(io.BytesIO(response.content))
else: # 假定为本地文件路径
img = Image.open(image_path_or_url)
img_width, img_height = img.size
# 计算宽高比例
aspect_ratio_img = img_width / img_height
aspect_ratio_target = target_width / target_height
# 确定裁剪框
if aspect_ratio_img > aspect_ratio_target: # 图片比目标更宽
new_width = int(img_height * aspect_ratio_target)
left = (img_width - new_width) // 2
right = left + new_width
top = 0
bottom = img_height
else: # 图片比目标更高或者相等
new_height = int(img_width / aspect_ratio_target)
left = 0
right = img_width
top = (img_height - new_height) // 2
bottom = top + new_height
# 裁剪图像
cropped_img = img.crop((left, top, right, bottom))
# 调整到目标尺寸
resized_img = cropped_img.resize((target_width, target_height), Image.LANCZOS)
return resized_img
except (FileNotFoundError, requests.exceptions.RequestException, IOError) as e:
print(f"错误:无法打开或处理来自 '{image_path_or_url}' 的图片。 错误信息:{e}")
return None
except Exception as e: # 捕获图像处理期间的其他潜在异常。
print(f"发生未知错误:{e}")
return None最后,咱们加载这张图片并运行处理流程。▶️
url = "https://images.unsplash.com/photo-1609665558965-8e4c789cd7c5?ixlib=rb-4.0.3&q=85&fm=jpg&crop=entropy&cs=srgb&dl=sven-mieke-G-8B32scqMc-unsplash.jpg"
image = resize_image_center_crop(image_path_or_url=url, target_width=1024, target_height=1024) # 以中心裁剪的方式调整图片大小,使目标宽度和高度分别为1024像素
prompt = "一张老虎的照片"
image2 = pipeline(prompt, image=image, guidance_scale=3.5, generator=generator, height=1024, width=1024, num_inference_steps=28, strength=0.9).images[0]这会转换下面这张图:

照片由Sven Mieke提供,出自Unsplash。
对此:

根据提示生成的:一只猫趴在一个鲜艳的红色地毯上
你可能会发现这只猫的姿态形状与原图中的猫相似,但地毯的颜色不同。这说明模型按照原图的模式,同时也做了一些调整,使结果更符合描述。
这里有两个关键的参数。
- 推理步骤数(num_inference_steps):这是去噪过程中反向扩散步骤的数量,步骤数越多意味着质量越好,但生成时间也会越长
- 强度(strength):它控制了你希望引入多少噪声或在扩散过程中你想从多远的地方开始。数值越小,变化越小;数值越大,变化越显著。
现在你知道了Image-to-Image隐式扩散模型是如何工作的,以及如何用Python运行它。在我的测试中,使用这种方法的结果仍然可能参差不齐,我通常需要调整步数、强度和提示以更好地遵循提示。下一步是寻找一种既能更好地遵循提示又能保留输入图像关键元素的方法。
完整代码链接: https://colab.research.google.com/drive/1GJ7gYjvp6LbmYwqcbu-ftsA6YHs8BnvO





