
这次利用scrapy抓取了深圳所有在链家网的租住房信息,一直对房租价格比较感兴趣,这次终于能利用自己的技能分析一下了,至于为什么现在链家网,时候觉得这里数据比较齐全。
这是网址

Paste_Image.png
下面是scrapy框架图
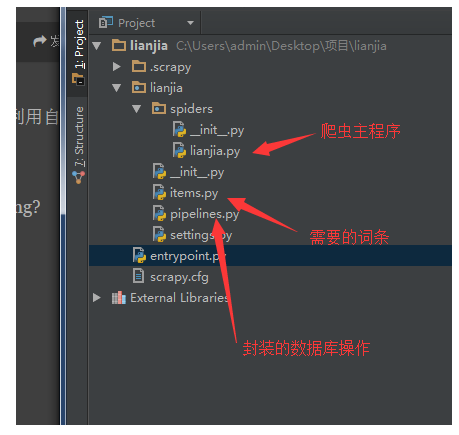
Paste_Image.png
先看items代码,看看我们需要什么数据

Paste_Image.png
提取这些数据都是为了分析与价格的关系
这是setting里面链接MySql的一些设定,包括密码,用户,以及端口,在pipelines里面要用

Paste_Image.png
下面看pipelines代码,主要是对于抓取到的数据进行操作,存进Mysql数据库,这里不得不吐槽一下,mogodb数据库在爬虫里面感觉比MySql方便多了,因为在插进数据之前,自己必须现在数据库里面创建好表。
import mysql.connector
from lianjia import settings# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.htmlMYSQL_HOSTS = settings.MYSQL_HOSTS
MYSQL_USER = settings.MYSQL_USER
MYSQL_PASSWORD = settings.MYSQL_PASSWORD
MYSQL_PORT = settings.MYSQL_PORT
MYSQL_DB = settings.MYSQL_DB#这几条是链接MySql数据库的,端口密码,都在setting文件里面设定好了cnx = mysql.connector.connect(user = MYSQL_USER,password= MYSQL_PASSWORD,host =MYSQL_HOSTS,database=MYSQL_DB)#创建链接cur = cnx.cursor(buffered=True)class Sql:#这里的sql语句为下面数据插入以及去重做准备
@classmethod def insert_tenement_message(cls,title,rental,distance,area,room_number,floor,direction,year_build):
sql = 'INSERT INTO tenement_message(`title`,`rental`,`distance`,`area`,`room_number`,`floor`,`direction`,
`year_build`)
VALUES
(%(title)s,%(rental)s,%(distance)s,%(area)s,%(room_number)s,%(floor)s,%(direction)s,%(year_build)s)'
value = { 'title':title, 'rental':rental, 'distance':distance, 'area':area, 'room_number':room_number, 'floor':floor, 'direction':direction, 'year_build':year_build,
}
cur.execute(sql,value)#执行语句,插进数数据库
cnx.commit()
@classmethod def select_title(cls,title):#这个是利用标题去重的,虽然按照区域划分应该不会重复,只是预防万一
sql= 'SELECT EXISTS (SELECT 1 FROM tenement_message WHERE title = %(title)s)'
value = { 'title':title
}
cur.execute(sql,value) return cur.fetchall()[0]class LianjiaPipeline(object):
def process_item(self, item, spider):
title = item['title']
ret = Sql.select_title(title) if ret[0] ==1:
print('房子已经存在') else:
rental = item['rental']
distance = item['distance']
area = item['area']
room_number = item['room_number']
floor = item['floor']
direction = item ['direction']
year_build = item['year_build']
Sql.insert_tenement_message(title,rental,distance,area,room_number,floor,direction,year_build)
print('开始存租房信息')下面是链家lianjia主爬虫程序脚本
import scrapyfrom bs4 import BeautifulSoupfrom scrapy.http import Requestfrom lianjia.items import LianjiaItemimport requestsimport reclass myspider(scrapy.Spider):
name = 'lianjia'
allowed_domains =['sz.lianjia.com'] def start_requests(self):
theme_url = 'http://sz.lianjia.com/zufang/luohuqu/pg1/'#爬虫开始的页面
html = requests.get(theme_url)
content = BeautifulSoup(html.text, 'lxml')
urls = []
links = content.find('div', class_='option-list').find_all('a')#找出所有区域的链接
for link in links:
i = re.findall(r'g/(.*)/', link['href']) if i:
urls.extend(i)#提取每个区域的链接
all_url = ['http://sz.lianjia.com/zufang/{}/pg1/'.format(i) for i in urls]#构造出每一个区域的链接
for url in all_url:
print(url) yield Request(url,self.parse)#对每个链接调用parse函数
def parse(self, response):
page = BeautifulSoup(response.text, 'lxml').find('div', class_='page-box house-lst-page-box')#找
出每个区域最大的页数,
然后遍历
max_page = re.findall('Page":(\d+)."cur', str(page))[0]
bashurl = str(response.url)[:-2] for num in range(1,int(max_page)+1):
url = bashurl+str(num)+'/'
#print(url)
yield Request(url,callback=self.get_message) def get_message(self,response):
item = LianjiaItem()
content = BeautifulSoup(response.text, 'lxml')
house_list = content.find_all('div', {'class': 'info-panel'})#找到所以租房信息所在的标签里
for li in house_list: try:
data = li.find('span', class_='fang-subway-ex').find('span').get_text()
item['distance'] = re.findall(r'(\d+)', data)[1] # 将离地铁站的距离多少米提取出来,切片选
取第二个数字是因为第一个是地铁线号,要提出 except:
item['distance'] = "没有附近地铁数据"
# 取出楼层,因为里面用/分割了多段文字,所以用split提取
try:
item['year_build'] = re.findall(r'(\d+)', li.find('div', class_='con').get_text().split('/')[-1])[0] # 把房
屋的建造年份提取出来 except:
item['year_build'] = '没有建造年份'
item['title'] = li.find('h2').find('a').attrs['title']
item['rental'] = li.find('div', class_='price').find('span').get_text()
item['area'] = re.findall(r'(\d+)', li.find('span', class_='meters').get_text().replace(' ', ''))[ 0] # 将面积数据提取出来
item['room_number'] = li.find('span', class_='zone').find('span').get_text().replace('\xa0','')
item['floor'] = li.find('div', class_='con').get_text().split('/')[1] # 取出楼层,因为里面用/分割了多段文字,
所以用split提取
item['direction'] = li.find('div', class_='where').find_all('span')[-1].get_text() # 提取房屋朝向,
先找到这个标签在提取文字 yield item来看看运行结果吧

Paste_Image.png
一共差不多7000间房出租,第一次看到惊呆了,这也太少了吧比我想得,哈哈
绘制了一下价格跟地铁距离关系的图,以后再补上,顺便一提,如果遍历深圳链家租房主页,是只有100个页面的,爬的数据是不全的,只有5000套左右
作者:蜗牛仔
链接:https://www.jianshu.com/p/ecf3a88d9ae1





