

zh: 在生产线上,这些工人同时包装这些小批次。
dbt Labs团队最近发起了一次关于提供处理批量工作负载的标准方法的讨论。这是一项非常出色且非常需要的改进。特别感谢dbt Labs团队,尤其是Grace,带头推动了这一倡议呢!
在本文中,我们将探讨当前需要解决的一些挑战,分享我们在Teads如何应对这些问题的经验,看看dbt Labs的新方法,最后谈谈我对于潜在解决方案的一些想法。
使用dbt的时间序列dbt 已被证明是一个适合各种数据工作负载的多功能工具,在处理参考和事实数据方面表现出色。增量材料化特性允许我们跳过已处理的数据,大幅减少不必要的处理成本。
然而,当在企业环境中处理大规模数据时,处理时间序列数据会变得非常复杂,特别是当尝试:
- 特别是在尝试以下情况。
- 处理上次处理的数据与最近数据之间的差异
- 再次处理过去的特定分区数据或分区集(例如,某个时间段内的)
我们正在为一家电商公司构建分析系统,重点放在与产品销售相关的事件上。
想象我们正在追踪诸如“浏览产品”、“产品加入购物车中”和“产品已卖出”之类的事件,以及相关属性,比如地理位置和环境。为了创建一个简单的每小时指标仪表板,我们通常会按小时对所有事件进行分组和统计。
现在,假设我们要引入一个新的“喜欢产品”的指标,并且需要重新处理我们的数据集市以将过去几小时的数据纳入新指标。这可能会是这样的:
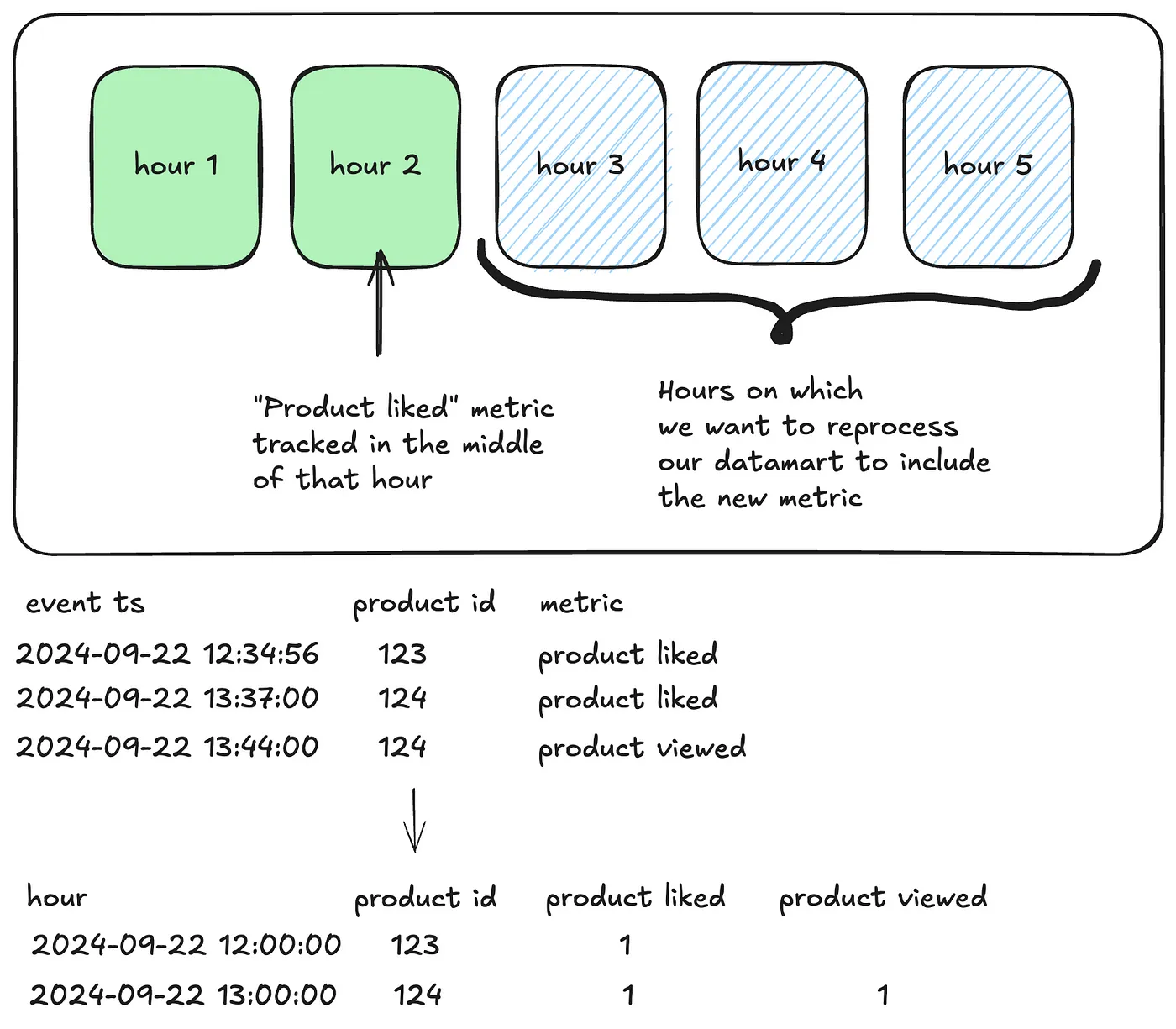
为了重新审视那三个历史时刻,我们可以通过两种方式来实现增量实现,具体如下:
- 触发全面刷新:这将重新处理第1和第2小时的数据,可能浪费计算资源并超出容量限制。此外,如果部署在第2小时的中间进行,那么第2小时的数据可能只包含部分指标。虽然这可能不会对“产品被喜欢”的例子产生重大影响,但它可能导致与现有指标(如“花费金额”)相关的指标出现不一致。
- 删除并重新处理最后三个小时的数据:这种方法会在现有指标中造成短暂缺口,这可能会让用户因延迟而感到沮丧。我们可以更新模型以从第3小时开始设置一个下限,但如果需要重新处理整个数据集市或使用低于该门槛的数据的暂存环境,这将变得不方便。
两种方法都需要妥协。我们该怎么应对这些局限性呢?
Teads是怎么操作的在 Teads,我们开发了一个内部工具,通过分区级别的锁定机制来管理和协调分区状态及并发。该系统被广泛使用,并已与 dbt 集成,尽管 dbt 不是专门为此用例设计的。(我们在之前的博客文章中详细介绍过)
为了填补这个鸿沟,我们创建了这些宏来利用变量,帮助系统间更好地交流。
- 我们的编排器查询分区元数据存储,以获取定义的作业要处理的小时/天/月。
- 然后它启动一个包含 dbt 核心的容器,传递要处理的模型和标签以及一个变量,如
--variables '{"date": "2024092300"}'。 - dbt 模型包含类似
WHERE {{ partition_for_hour('hour') }}的语句,这会变成类似于WHERE hour = '2024-09-23 00:00:00'。
这种方法让我们能够使用不同的宏来处理特定的时间单位(小时、天或月),比如{{parse_hour()}}。我们还有其他的宏可以返回实际的小时,比如{{parse_hour()}}。
通过用户界面,我们可以将分区的状态更新为需要重新处理,这将由我们的调度程序根据我们的需求和可用资源按顺序或并行安排。虽然这通常要求分区必须是独立的,但是我们添加了定义作业为“滑动窗口计算”的选项,它依赖于前一个小时的数据来计算下一个小时的数据。
我们也尝试过使用这种格式的 --variables '{"start_date": "2024092300", "end_date": "2024092300"}' 参数,但它也有自己的难题。
- 在连接两个时间序列数据集时,效率可能会降低,因为你可能会期望这些通过ID字段连接的事件处于相似的时间窗口。
- 虽然我们可以尝试确保相邻的分区用于连接,但一次运行中处理一个大时间段通常效率不高。启动X个查询通常会更有效。
最近,在 GitHub 上启动了一场关于新功能设计的讨论,概述了设计初期的构思,旨在解决批处理工作负载的问题。提议的解决方案引入了一种新的 incremental_strategy,名为 microbatch,并提供了专门的选项。
event_time:分区用的时间列(例如,名为 "hour" 的列)。batch_size:回溯时间段的粒度(例如,"天" 粒度)。lookback_period:回溯的batch size单位数(例如 7 表示回溯 7 天)。
这里提出的解决方案实际上可能看起来是这样的:
# stg_events.yml
models:
- name: stg_events
config:
event_time: my_time_field
batch_size: 按天-- 该模型文件定义了增量数据处理逻辑
-- my_model.sql
{{
config(
materialized='增量',
incremental_strategy='微批次',
event_time='日期天',
batch_size='天',
lookback_period='3'
)
}}
select * from {{ ref('stg_events') }} # 这个 ref 会被自动过滤这会产生的SQL如下:
select *
from stg_events
where my_time_field > dateadd(-3, day, current_date)结合使用 --event-time-start 和 --event-time-end 参数时,它可以在特定日期范围内运行,每经过 batch_size 个步骤执行一次查询。
虽然提出的解决方案算是一步好棋,但仍有几个方面值得我们考虑。
- 增量策略的分类:将其作为
incremental_strategy的决定似乎有些不合常理。微批处理逻辑可能与现有的策略(如merge或insert_overwrite)合并,而不是创建一个新的策略。 - 配置结构:更直观的做法是创建一个如下的配置对象:
{{
config(
materialized='增量视图',
incremental_strategy='插入覆盖策略',
micro_batch = {
"事件时间": '日期天',
"批处理大小": '天',
"回溯期": '3天'
}
)
}}3. 术语:为了使术语更好地符合特定领域的意义,重新命名并考虑调整。
batch_size到granularity。lookback_period到lookback_window(回溯窗口)。event_time到字段(以匹配分区定义术语)。
4. 时间限制:添加可选的开始和结束时间可以增加更多灵活性和选择。
{{
config(
materialized='增量视图',
incremental_strategy='追加覆盖策略',
微批处理 = {
"字段名": 'date_day',
"粒度级别": '天',
"回溯周期": '3',
"开始日期": '2024-09-01'
}
)
}}5. 参考语法:提议的 ref('upstream_model').render() 感觉有点别扭。一个更干净的方法可能是让 ref 接受一个可选参数,例如 ref('upstream_model', micro_batch=False)。
6. 命令行选项 :将 --event-time-start 和 --event-time-end 简化为 --period-start 和 --period-end 可以让操作更简单。此外,在指定时间执行单个微任务批次时增加一个 --period 选项也很有用。
虽然这些建议可能看起来像吹毛求疵,仔细考虑配置命名非常关键,因为这些决定往往会成为长期的标准。
应对未来考虑及解决特殊情况这种方法带来了几个问题和潜在的挑战。
- 粒度差异:系统将如何处理粒度差异的问题,比如小时模型依赖于每日模型,反之亦然?
- 分区配置:能否利用现有的分区配置,而不是增加更多的配置选项?这样做可以简化系统,同时仍然满足大多数(如果不是全部)的使用场景。
- 并行处理:处理大时间范围可能会导致许多微批次并行运行。如何调整这些微批次以与其他查询保持平衡?虽然线程数设置可能已经足够,但我们可能还需要额外的控制。
- 自引用作业:当前设计似乎不支持自引用作业,这些作业类似于滑动窗口。为这些情况支持微批次的顺序执行将很有价值。
- 无状态执行:由于dbt是“无状态”的,执行相同的作业两次意味着重复工作。虽然计划中的重试命令将有所帮助,但实现适当的模型执行跟踪将会是一个重要的改进。
- 版本切换:从模型v1切换到v2时,微批次是否会像常规的增量全刷新一样进行原子切换?虽然这可能不是关键障碍(因为dbt-bigquery的
copy_partitions已经不是原子操作),但这对用户来说是一个重要的考虑因素。
其中一些想法在SQLMesh等替代方案中得到了实现,并且可以经过调整来适应dbt。
所以,这是结尾引入微批次功能是解决许多大规模运营中的公司面临的问题的一个有前景的解决方案。随着功能的逐步实现(感谢 Michelle Ark 的积极开发 🚀),在它进入稳定版本之前,我们可以期待更多的改进和优化。
虽然这个功能令人兴奋,但也值得注意的是,使用 INFORMATION_SCHEMA 获取分区信息的功能虽然可能仍然相关,但 添加使用 INFORMATION_SCHEMA 获取分区信息的选项 可能仍然相关。我怀疑 Amy 可能提到的是否是那个微批处理功能。
关于批处理工作负载的这些讨论体现了社区致力于解决实际数据挑战的承诺。我期待着该功能的发布……也许在2025年吧?




