
在本教程中,我们将构建一个简单的聊天界面,让用户可以上传一个PDF文件,使用OpenAI的API提取其内容,并使用Streamlit以聊天的形式显示回复。我们还将使用@pinata上传和存储PDF文件。
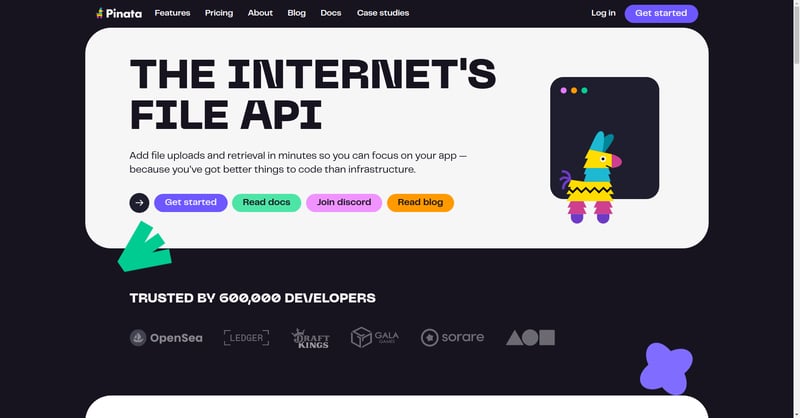
让我们先来看看我们要建的东西,然后再继续前进:
前提条件:
- 基本的Python知识
- Pinata的API密钥(用于上传PDF文件)
- OpenAI的API密钥(用于生成回复)
- 安装了Streamlit(用于构建用户界面)
首先,创建一个新的Python项目目录。
mkdir chat-with-pdf
cd chat-with-pdf
python3 -m venv venv
source venv/bin/activate
pip install streamlit openai requests PyPDF2全屏 退出全屏
现在,在项目根目录下创建一个 .env 文件,并加入以下环境变量:
Pinata_API_KEY=Pinata的API密钥
Pinata_密钥=Pinata的密钥
OpenAI_API_KEY=OpenAI的API密钥点击全屏 退出全屏
你需要自行管理OPENAI_API_KEY,因为它需要付费。但让我们来看看在Pinita中创建API密钥的方法。
那么,继续之前,我们先来了解一下什么是Pinata,我们为什么要用它。
Pinata是一个帮助用户存储和管理文件的平台,基于IPFS(星际文件系统 (IPFS)),一个去中心化且分布式的文件存储系统。
- 去中心化存储:Pinata 帮助你在 IPFS(一个去中心化网络)上存储文件。
- 易于使用: 它提供了用户友好的工具和 API 来管理文件。
- 文件的可用性: Pinata 通过将文件“固定”在 IPFS 上来确保文件的可用性。
- NFT 支持: 它非常适合存储 NFT 以及 Web3 应用的元数据。
- 成本效益: Pinata 可能比传统的云存储更加经济实惠。
让我们在登录时创建所需的token。
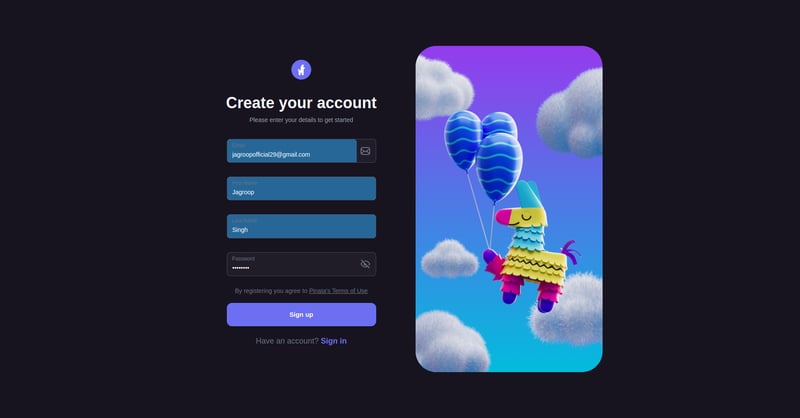
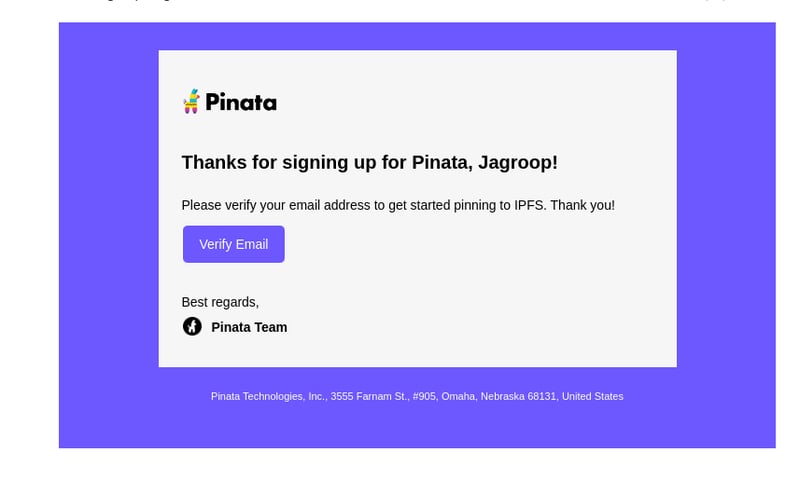
接下来是验证一下你的注册邮箱:
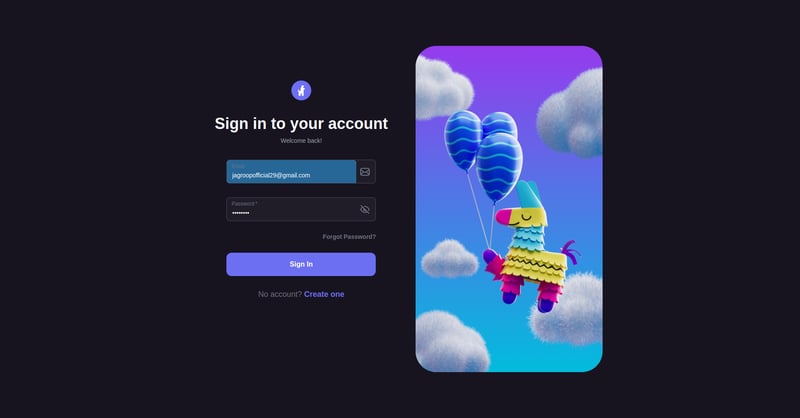
登录验证后,就可以生成API密钥(即访问密钥)了。
 这是一张图片,点击可以查看。
这是一张图片,点击可以查看。
然后去 API 密钥部分生成新的 API 密钥
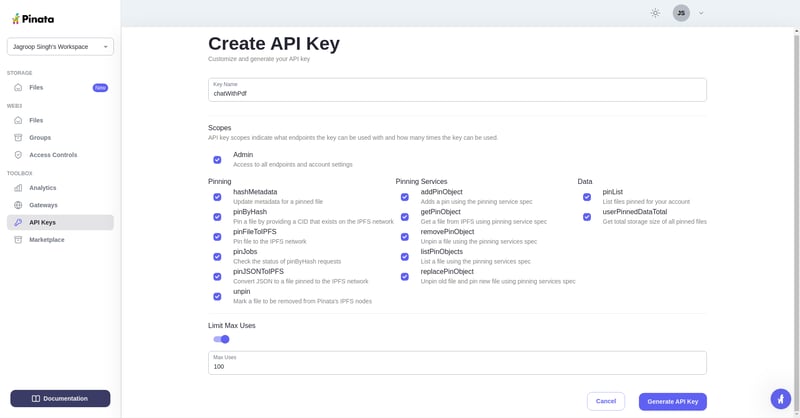 (示例图片)
(示例图片)
最后,密钥已成功生成。请把这些密钥复制,并将它们保存到您的代码编辑器里,不要忘了保存哦。
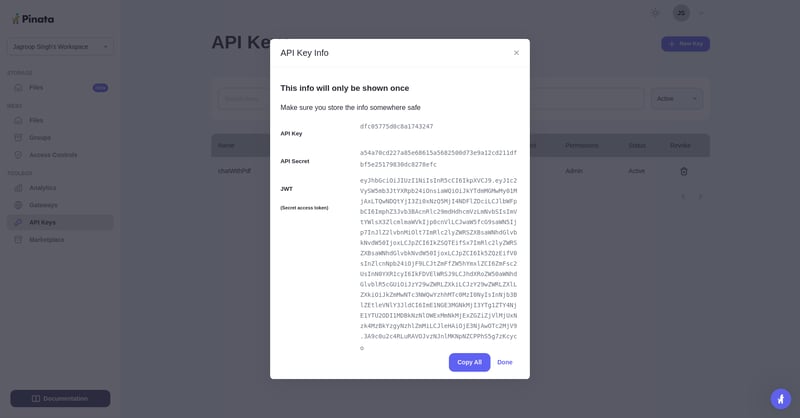
注:此图为token5的相关内容,请点击查看。
OPENAI_API_KEY=<请替换为您的OpenAI API密钥>
PINATA_API_KEY=dfc05775d0c8a1743247
PINATA_SECRET_API_KEY=a54a70cd227a85e68615a5682500d73e9a12cd211dfbf5e25179830dc8278efc全屏,退出全屏
第二步:使用Pinata上传PDF文件(Pinata,一个文件存储服务)我们将使用Pinata的API上传PDF,并为每个PDF文件获取一个CID(哈希值)。创建一个名为pinata_helper.py的文件来处理PDF的上传。
import os # 导入 os 模块以与操作系统交互
import requests # 导入 requests 库以发送 POST 请求
from dotenv import load_dotenv # 导入 load_dotenv 从 .env 文件中加载环境变量
# 从 .env 文件中加载环境变量
load_dotenv()
# 定义 Pinata API URL,用于将文件上传到 IPFS
PINATA_API_URL = "https://api.pinata.cloud/pinning/pinFileToIPFS"
# 从环境变量中获取 Pinata 的 API 密钥
PINATA_API_KEY = os.getenv("PINATA_API_KEY")
PINATA_SECRET_API_KEY = os.getenv("PINATA_SECRET_API_KEY")
def upload_pdf_to_pinata(file_path):
"""
将 PDF 文件上传到 Pinata 的 IPFS 服务。
参数:
file_path (str): 要上传的 PDF 文件路径。
返回:
str: 如果上传成功,返回文件的 IPFS 哈希值;否则返回 None。
"""
# 准备请求头
headers = {
"pinata_api_key": PINATA_API_KEY,
"pinata_secret_api_key": PINATA_SECRET_API_KEY
}
# 以二进制读模式打开文件
with open(file_path, 'rb') as file:
# 发送 POST 请求以上传文件
response = requests.post(PINATA_API_URL, files={'file': file}, headers=headers)
# 检查请求是否成功(状态码为 200)
if response.status_code == 200:
print("文件上传成功") # 打印成功消息
# 从响应 JSON 中返回 IPFS 哈希值
return response.json()['IpfsHash']
else:
# 如果上传失败,打印错误消息
print(f"错误: {response.text}")
return None # 返回 None 表示失败全屏模式 退出全屏
步骤 3:配置 OpenAI
接下来,我们将创建一个用于与从 PDF 提取的文本交互的函数。我们将使用 OpenAI 的 gpt-4o 或 gpt-4o-mini 模型来生成聊天回复。
创建一个新的文件 openai_helper.py。
import os
from openai import OpenAI
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI client with the API key
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
def get_openai_response(text, pdf_text):
try:
# Create the chat completion request
print("用户输入:", text)
print("PDF内容:", pdf_text) # 可选:用于调试
# Combine the user's input and PDF content for context
messages = [
{"role": "system", "content": "您是一个乐于助人的助手,用于回答有关PDF的问题."},
{"role": "user", "content": pdf_text}, # 提供PDF内容
{"role": "user", "content": text} # 提供用户问题或请求
]
response = client.create_chat_completions(
model="gpt-4", # 使用"gpt-4"或"gpt-4o mini"根据您的访问权限
messages=messages,
max_tokens=100, # 如有必要,请调整
temperature=0.7 # 调整以控制响应的创造性
)
# 提取响应内容
return response.choices[0].message.content # 正确的访问方法
except Exception as e:
return f"错误: {str(e)}"全屏 退出全屏
步骤四:构建Streamlit界面现在我们已经准备好辅助函数了,是时候构建Streamlit应用来上传PDF,上传PDF后,从OpenAI获取响应并显示聊天内容了。
创建一个名为 app.py 的文件:
import streamlit as st
import os
import time
from pinata_helper import upload_pdf_to_pinata
from openai_helper import get_openai_response
from PyPDF2 import PdfReader
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
st.set_page_config(page_title="与PDF聊天", layout="centered")
st.title("使用OpenAI和Pinata与PDF聊天")
uploaded_file = st.file_uploader("上传您的PDF", type="pdf")
# 初始化会话状态的聊天历史和加载状态
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "loading" not in st.session_state:
st.session_state.loading = False
if uploaded_file is not None:
# 将上传的文件保存在临时位置
file_path = os.path.join("temp", uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
# 将PDF上传到Pinata
st.write("正在将PDF上传到Pinata...")
pdf_cid = upload_pdf_to_pinata(file_path)
if pdf_cid:
st.write(f"文件上传到IPFS,CID为:{pdf_cid}")
# 提取PDF内容
reader = PdfReader(file_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
if pdf_text:
st.text_area("PDF内容", pdf_text, height=200)
# 允许用户向PDF提问
user_input = st.text_input("有关PDF的问题:", disabled=st.session_state.loading)
if st.button("发送", disabled=st.session_state.loading):
if user_input:
# 设置加载状态为True
st.session_state.loading = True
# 显示加载指示器
with st.spinner("AI正在思考..."):
# 仿真加载(请注意,这行代码在实际生产环境中需要移除)
time.sleep(1) # 仿真网络延迟
# 获取AI响应
response = get_openai_response(user_input, pdf_text)
# 更新聊天历史
st.session_state.chat_history.append({"user": user_input, "ai": response})
# 清空输入框
st.session_state.input_text = ""
# 重置加载状态
st.session_state.loading = False
# 显示聊天历史
if st.session_state.chat_history:
for chat in st.session_state.chat_history:
st.write(f"**您:** {chat['user']}")
st.write(f"**AI:** {chat['ai']}")
# 自动滚动到聊天界面的底部
st.write("<style>div.stChat {overflow-y: auto;}</style>", unsafe_allow_html=True)
# 添加三个点作为加载指示器,如果还在等待响应
if st.session_state.loading:
st.write("**AI正在输入** ...")
else:
st.error("无法从PDF中提取任何文本。")
else:
st.error("未能将PDF上传至Pinata。")
进入全屏;退出全屏
第五步:启动应用程序要在本地运行该应用,请运行以下命令。
你可以通过输入streamlit run app.py来运行你的Streamlit应用程序。
进入全屏,退出全屏
我们的文件已成功上传到Pinata:
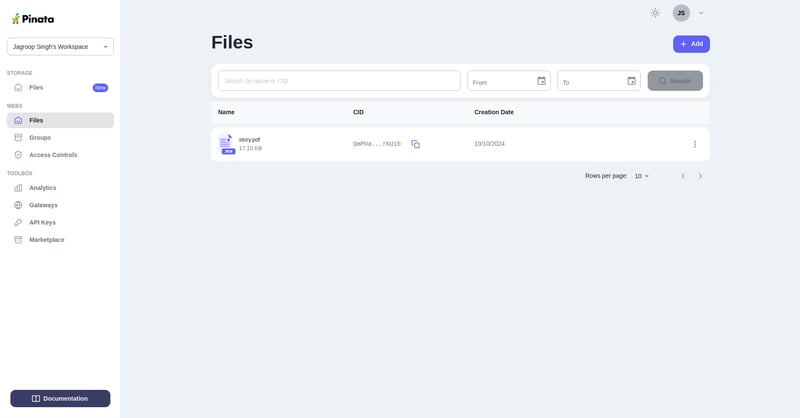 .
.
潘娜塔(Pinata)上传
- 用户上传一个 PDF 文件,该文件会被暂时保存在本地,并通过调用
upload_pdf_to_pinata函数上传到 Pinata。Pinata 会返回一个哈希(CID),该哈希(CID)代表存放在 IPFS 上的文件。
从PDF中提取内容
上传文件后,我们就会用PyPDF2提取PDF里的内容并展示在文本框中。
开放AI互动体验
- 用户可以通过文本输入来提问PDF中的内容。get_openai_response函数将用户的查询和PDF内容一起发送给OpenAI,然后返回一个相关的回答。
最终代码在这里:https://github.com/Jagroop2001/chat-with-pdf,点击链接查看。
这篇博客到这就结束了!敬请关注更多更新,继续开发更多精彩的应用程序!💻✨
编程快乐!




