

这周在奥斯汀圆满结束的 Current 2024 — Kafka 和数据流领域的顶级会议 — 是我第三次参加,一如既往,会场挤满了来自全球的数据流专家。但今年感觉有些不同 — 关于Kafka的未来,有一种明显的不确定性笼罩着整个大会。这个项目接下来会往哪个方向发展呢?随着AI领域快速发展,生态系统又会怎样演变,Kafka又将扮演什么样的角色呢? 在这样一个更加复杂的新环境中,这些问题始终萦绕在我的心头。
卡夫卡作品如今已不再和十年前一样了创建于LinkedIn大约13年前,Kafka 最初被定位为一个分布式、持久化、高吞吐量的消息系统,旨在以低延迟收集和传递大量数据流。它在2011年开源,并随后捐赠给了Apache基金会,发展成为现代软件领域中最成功的项目之一。2014年,它的创建者离开了LinkedIn,成立了Confluent,该公司于2021年上市,并且已跻身数据流领域的领导者行列。然而,自从Kafka早期以来,世界已经发生了巨大的变化,而如今Kafka本身正面临一个更为复杂的生态系统。

Kafka 最初被设计为一个分布式的、高吞吐的消息传递系统。
在2011年,Kafka主要干了三件事。
- 收集日志数据
- 将日志数据输入在线应用程序
- 在实际运行环境中部署处理过的日志数据
Kafka 的日志结构设计在这个背景下非常合理。但尽管其核心用例今天仍然相似,周围的基础设施、应用程序和数据栈已迅速发展和演变。这种演变给 Kafka 带来了现代数据架构的新需求,从而带来了新的挑战和机遇。

不同应用对延迟的要求也不同。
几个关键变化- 多样化的延迟要求:现代系统对于延迟的期望变得更为极化。虽然金融服务需要微秒级的延迟来进行股票交易,其他用例——如日志记录或在操作数据库和分析系统之间同步数据——则可以接受秒级的延迟。单一解决方案已经不再能满足所有需求。一家使用Kafka进行简单日志记录的公司为什么要支付与构建关键任务低延迟应用程序的公司相同的成本?
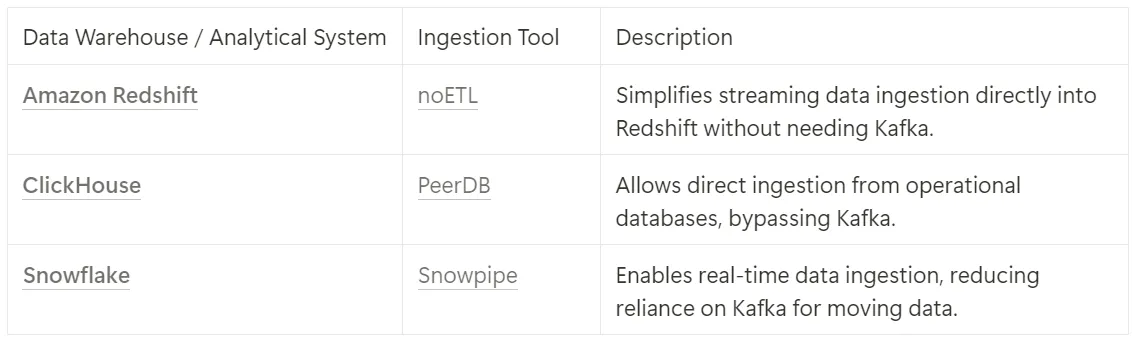
- 批处理系统正在构建自己的摄取工具:像Snowflake的Snowpipe,Amazon Redshift的noETL工具和ClickHouse,后者最近收购了PeerDB,现在都提供内置的流数据摄取功能。这些发展减少了Kafka作为首选跨环境数据传输系统的必要性。Kafka不再是向分析系统传输数据的唯一选项,这导致了其传统应用案例的自然分化。
- 云基础设施已经使得存储成本更低:像Amazon S3这样的对象存储解决方案比计算实例(如EC2)要便宜得多。这使得使用更昂贵的存储选项变得越来越难以证明其合理性,尤其是在一个公司不断优化云成本的世界里。因此,Kafka需要拥抱利用更便宜的存储选项的架构,否则它可能会成为数据管道中一个过于昂贵的部分。
鉴于这些变化,Kafka 已经不能依靠原来的架构了。它需要进化并适应现代数据生态系统中的需求,以保持其在日益云化的世界中的相关性。
卡夫卡肯定会变得更便宜,便宜十倍都不止在 Current 2024 大会上,最令人兴奋的公告之一是收购了 WarpStream(https://www.warpstream.com/),这是一个与 Kafka 兼容的系统,将运行 Kafka 的成本降低了惊人的 10 倍。这个概念简单而优雅:WarpStream 使用 S3 作为主要存储(https://www.warpstream.com/blog/kafka-is-dead-long-live-kafka),消除了对本地磁盘的依赖,并大大降低了网络传输费用。通过将存储层移到更便宜的云端对象存储,WarpStream 使 Kafka 更加经济。
收购WarpStream的战略目标很明确——在正在崛起的竞争对手扰乱市场秩序并迫使所有人利润率下降之前将其吸收。通过将WarpStream成本效益高的架构整合到更广泛的Kafka生态系统中,Confluent可以保持其市场领先地位,而不被更便宜的竞争产品所超越。
然而,除了WarpStream,还有其他公司也在让Kafka变得更便宜。下面来看看其他公司如何降低Kafka的成本。

运行 Kafka 会不可避免地变得更便宜十倍,尤其是对于那些仅需使用 Kafka 进行日志或满足系统解耦需求的用户来说。对于这些用户而言,采用 S3 作为主要存储层的架构显然是更好的选择,通过消除对昂贵本地磁盘的需求从而降低成本。
卡夫卡(Kafka)必须进入批处理的世界。Kafka 一直是实时流处理领域的首选工具,但今天很明显,Kafka 不仅限于批处理。机会巨大,但也面临着威胁——越来越多的数据仓库和分析数据库开始自行构建数据摄入工具,这意味着用户可能不再需要 Kafka 来移动数据。
如果 Kafka 不加入批处理功能,它在数据生态系统中的地位可能会逐渐减弱。
随着数据架构转向在S3上存储冷数据以节省成本,Kafka必须准备好处理实时和历史数据。这时,Apache Iceberg 就可以发挥作用了。Iceberg 是一种设计用于处理大规模数据集的格式,作为现代数据湖中的关键部分,它正迅速变得流行。通过采用Iceberg,Kafka可以为用户提供一种无缝的方式来,在流处理和批处理模式下存储和查询数据的方式。
与其仅仅依赖 Kafka 来进行短期数据存储,并使用单独的数据仓库或湖仓来存储历史数据,Kafka 可以作为所有数据(包括流式和批量数据)的中心仓库。通过支持长期存储而无需设定保留策略,Kafka 可以发展成为真正的数据湖。Iceberg 在这一转变中扮演着关键角色,为用户提供模式演进、分区和优化查询性能等好处。随着 Iceberg 的采用增加,组织可以利用它来查询 Kafka 中的开放格式的数据,从而为流处理和批量处理工作负载解锁新的应用场景。
如果不拥抱批处理功能并集成了像 Iceberg 这样的格式,Kafka 可能会被边缘化,因为这些系统能够同时支持批处理和流处理,并以统一且经济高效的方式运作。Iceberg 连接这个缺口的能力是因此变得越来越受欢迎的原因之一。
这个卡夫卡得换个新的查询引擎了?为了最大限度地发挥Kafka在流处理和批处理领域的潜力,它需要一个将流数据作为第一类公民对待的查询引擎。虽然像Trino这样的以批处理为主的查询引擎在对大型数据集运行即席查询方面表现出色,但在持续查询方面却有局限——这对Kafka用户来说是一个关键要求。这种差距为专门针对Kafka需求设计的流优先查询引擎的出现提供了机会。
几个引擎已经挺身而出,填补了这一空白。RisingWave 和 Flink 是流处理为主的平台中的佼佼者,它们擅长处理实时更新的数据。RisingWave 特别适合在事件流上执行 SQL 查询,使用户能够实时获得见解,而无需应对传统流处理的复杂性。同样,Flink 的分布式流处理能力使其成为低延迟、高吞吐量应用的理想选择。
与此同时,ksqlDB 是 Kafka 的一个扩展,提供了一个简单且基于 SQL 的接口,用于实时查询和处理 Kafka 数据流。它与 Kafka 的深度集成使得其成为已经在 Kafka 生态系统中投入的人的一个有吸引力的选择。

这些以流处理为中心的引擎对于使Kafka数据即时查询至关重要——不论数据是新近生成的还是几天前生成的。通过解锁对实时和历史数据集的无缝查询,RisingWave、Flink和ksqlDB正在为Kafka铺平道路,使其在流处理和批处理界限逐渐模糊的情况下依然保持相关性。
结论是:卡夫卡未来的路Kafka 正站在一个十字路口。随着数据环境的变化,包括云原生架构、更便宜的对象存储,如 S3 以及新的批量数据摄入工具,Kafka 必须进化以跟上变化。更高效解决方案的出现,比如 Warpstream,预示着向更便宜的 Kafka 部署转变。此外,扩展到批处理领域并支持实时和历史数据的查询将是其未来至关重要的因素。
在这一演变中至关重要的是像 RisingWave、Flink 和 ksqlDB 这样的流处理优先的查询引擎。这些技术正在引领连续查询和实时洞察成为现实,这是 Kafka 需要全心全意拥抱的部分。
通过适应这些趋势——减少成本,整合批处理,采用新一代查询引擎——Kafka 将在未来多年仍将处于现代数据架构的核心位置。





