
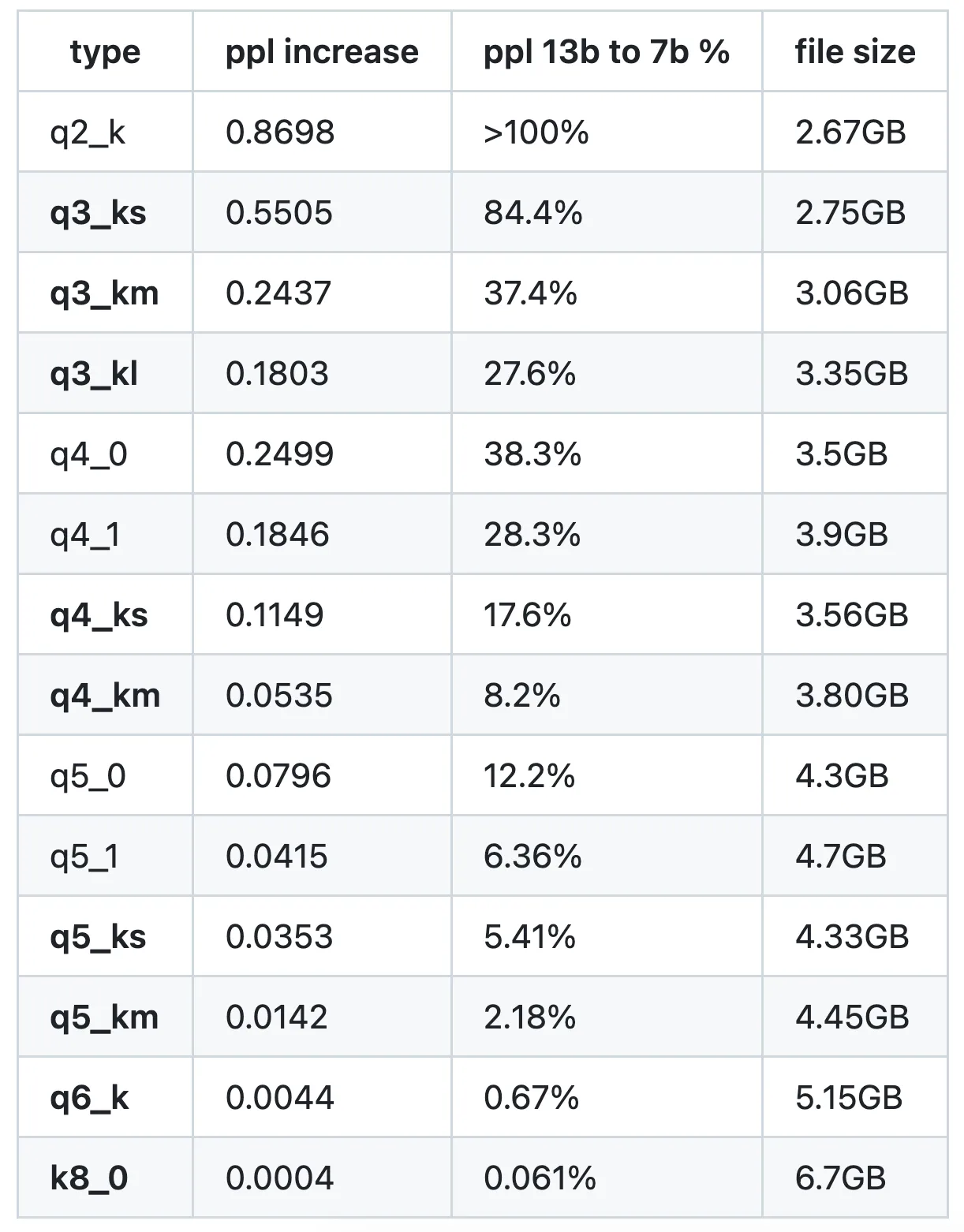
如果你正在处理一个巨大的语言模型,量化是你优化性能和速度的好朋友。有许多不同的量化方法,例如 Q3_K_S、Q4_K_M、Q4_0、Q8_0,哪一个是最好的?
通常,K_M 模型在大小和困惑度之间具有最佳平衡。在我的 PC 上,我最喜欢 Q4_K_M。这里有一些来自 llama.cpp 的测试数据:
参见 https://github.com/ggerganov/llama.cpp/pull/1684
llama.cpp 支持两种量化类型:"type-0" (Q4_0, Q5_0) 和 "type-1" (Q4_1, Q5_1)。
在 "type-0" 中,权重 w 通过 w = d * q 从量化值 q 获取,其中 d 是块缩放值。
在 "type-1" 中,权重由 w = d * q + m 给出,其中 m 是块的最小值。
例如:
GGML_TYPE_Q3_K - "type-0" 3位量化在包含16个块的超块中,每个块包含16个权重。缩放因子用6位量化。这最终使用了 3.4375 位/权重。
GGML_TYPE_Q4_K - "type-1" 4位量化在包含8个块的超块中,每个块包含32个权重。缩放值和最小值使用6位量化。这最终使用了 4.5 位每权重。
GGML_TYPE_Q6_K - "type-0" 6位量化。超级块包含16个块,每个块有16个权重。缩放因子使用8位量化。最终每个权重使用 6.5625 位。
LLAMA_FTYPE_MOSTLY_Q4_K_S- 使用GGML_TYPE_Q4_K对所有张量LLAMA_FTYPE_MOSTLY_Q4_K_M- 使用GGML_TYPE_Q6_K对attention.wv和feed_forward.w2张量的一半,其余使用GGML_TYPE_Q4_K





