

本地运行LLM的工具
运行大型语言模型(LLM)如ChatGPT和Claude通常涉及将数据发送到由OpenAI和其他AI模型提供商管理的服务器。虽然这些服务是安全的,但一些企业更倾向于将数据完全保持离线状态以获得更大的隐私保护。
本文介绍了开发人员可以用来本地运行和测试LLM的前六种工具,确保他们的数据永远不会离开他们的设备,类似于end-to-end encryption如何保护隐私。
为何使用本地LLM?像 LM Studio 这样的工具在用户使用它来运行本地大语言模型时不会收集用户数据或跟踪用户的操作。它可以让所有聊天数据保留在您的本地机器上,而不会与 AI/ML 服务器共享。
- 隐私:你可以以多轮对话的方式提示本地LLM,而你的提示数据不会离开你的本地主机。
- 自定义选项:本地LLM提供高级配置选项,包括CPU线程、温度、上下文长度、GPU设置等。这与OpenAI的游乐场类似。
- 支持和安全:它们提供了与OpenAI或Claude相似的支持和安全保障。
- 订阅和成本:这些工具免费使用,不需要每月订阅。对于像OpenAI这样的云服务,每次API请求都需要付费。本地LLM帮助节省成本,因为没有每月订阅费用。
- 离线支持:你可以在离线状态下加载和连接大型语言模型。
- 连接性:有时,连接到像OpenAI这样的云服务可能会导致信号和连接质量不佳。
根据您的具体使用场景,您可以选择几种离线大语言模型(LLM)应用程序。其中一些工具完全免费,可用于个人和商业用途。而其他工具可能需要您申请商业用途的许可。有许多本地的大语言模型工具适用于 Mac、Windows 和 Linux。以下是您可以选择的六种最佳工具。
1. LM Studio
LM Studio 可以运行任何格式为 gguf 的模型文件。它支持来自诸如 Llama 3.1、Phi 3、Mistral 和 Gemma 等模型提供商的 gguf 文件。要使用 LM Studio,请访问上述链接并下载适用于您机器的应用程序。启动 LM Studio 后,主页会展示可供下载和测试的顶级 LLM。此外,还有一个搜索栏,可以筛选并下载来自不同 AI 提供商的特定模型。
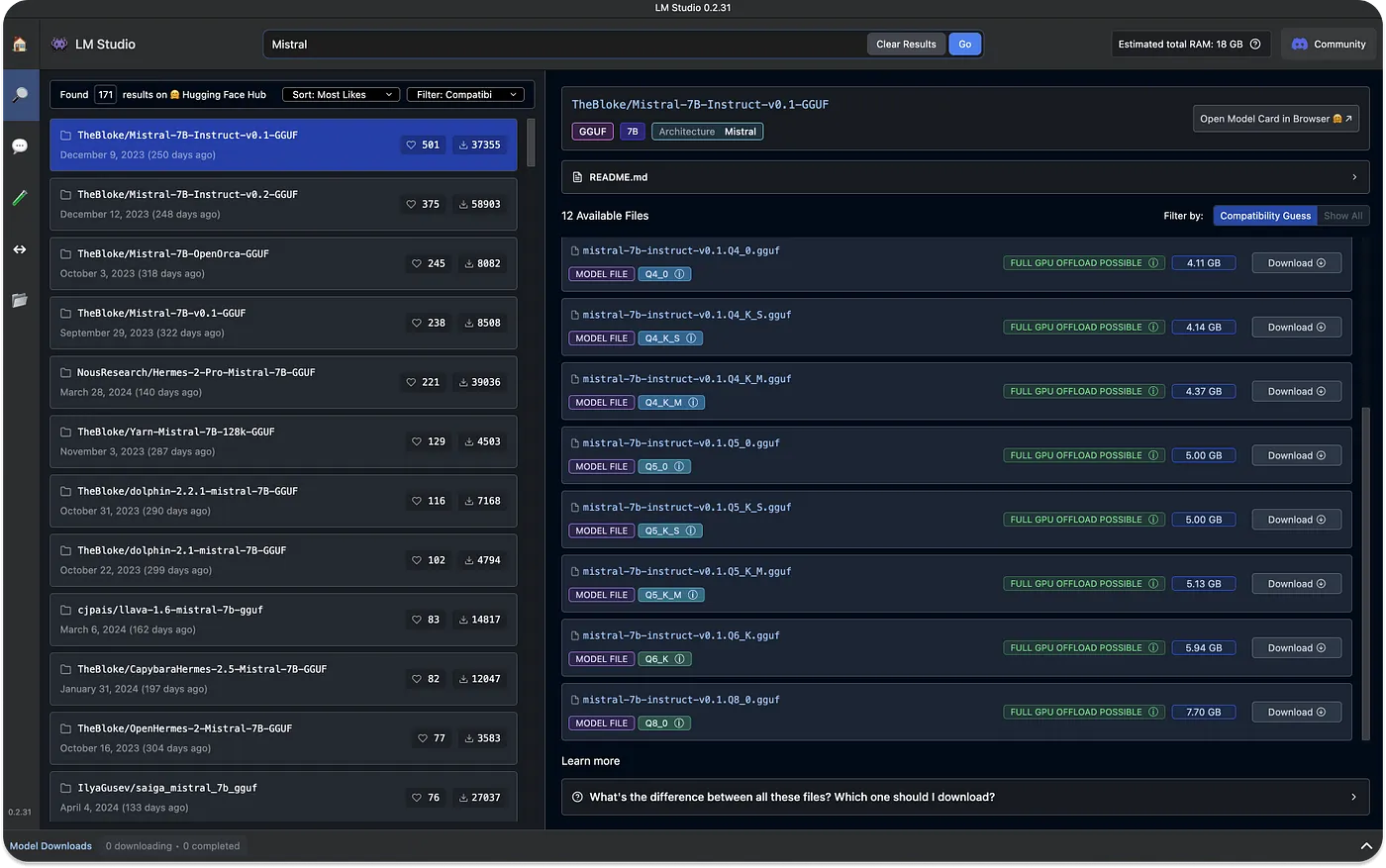
搜索来自特定公司的模型会呈现多个模型,从小到大都有 量化 的选项。根据你的机器配置,LM Studio 会使用兼容性猜测来突出显示可以在该机器或平台上运行的模型。
LM Studio 的关键特性LM Studio 提供与 ChatGPT 类似的功能和特性。它具有多个功能。以下突出显示了 LM Studio 的关键特性。
- 模型参数自定义 : 这允许你调整温度、最大令牌数、频率惩罚等参数。
- 聊天历史 : 允许你保存提示以备后用。
参数和UI提示:你可以悬停在信息按钮上查看模型参数和术语。 - 跨平台 : LM Studio 可在 Linux、Mac 和 Windows 操作系统上使用。
- 机器规格检查 : LM Studio 检查计算机的规格(如 GPU 和内存),并报告兼容的模型。这可以防止下载可能在特定机器上无法运行的模型。
- AI 聊天和游乐场 : 以多轮对话格式与大型语言模型进行聊天,并通过同时加载多个 LLM 进行实验。
- 开发者的本地推理服务器 : 允许开发者设置一个类似于 OpenAI API 的本地 HTTP 服务器。

本地服务器提供了示例的 Curl 和 Python 客户端请求。此功能有助于使用 LM Studio 构建一个 AI 应用程序以访问特定的 LLM。
# 示例:重用现有的 OpenAI 设置
from openai import OpenAI
# 指向本地服务器
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.chat.completions.create(
model="TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
messages=[
{"role": "system", "content": "总是用押韵来回答。"},
{"role": "user", "content": "介绍一下你自己。"}
],
temperature=0.7,
)
print(completion.choices[0].message)通过上述示例Python代码,你可以重用现有的OpenAI配置,并修改基础url指向你的本地主机。
- 导入OpenAI的Python库:LM Studio允许开发者导入OpenAI的Python库,并将基础URL指向本地服务器(localhost)。
- 多模型会话:使用单个提示并选择多个模型进行评估。
此工具免费供个人使用,允许开发人员通过应用程序内的聊天界面和游乐场运行大型语言模型(LLM)。它提供了一个美观且易于使用的界面,带有过滤器,并支持连接到OpenAI的Python库,而无需API密钥。公司和企业可以在请求的情况下使用LM Studio。然而,它需要使用M1/M2/M3 Mac或更高版本,或者使用支持AVX2的Windows PC处理器。Intel和AMD用户仅限于使用v0.2.31版本的Vulkan推理引擎。
2. Jan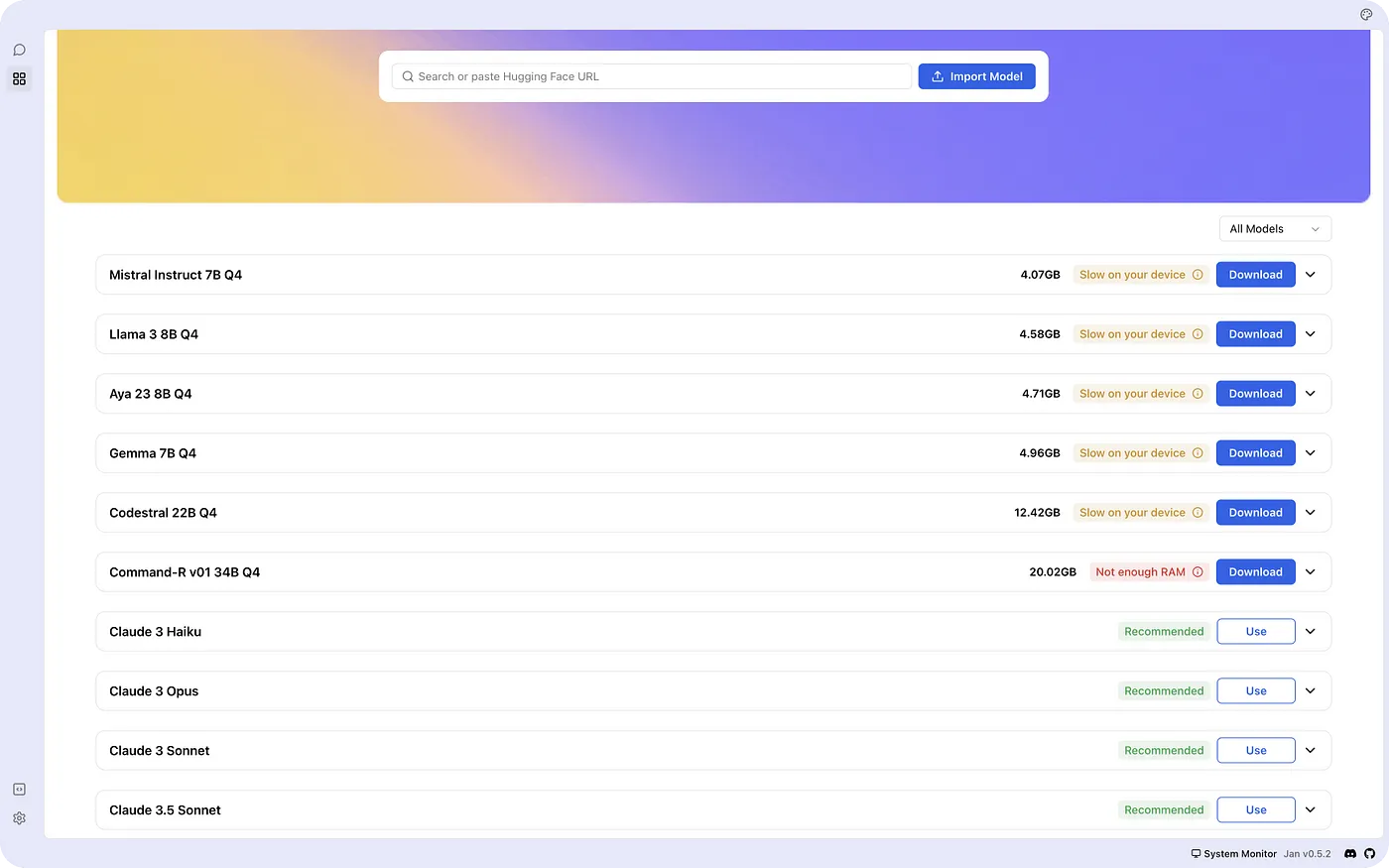
将Jan视为一个离线运行的开源版本的ChatGPT。它是由一群用户基于用户所有制理念构建的。Jan允许你在不连接互联网的情况下,在你的设备上运行流行模型,如Mistral或Llama。使用Jan,你可以访问远程API,如OpenAI和Groq。
Jan 的关键特性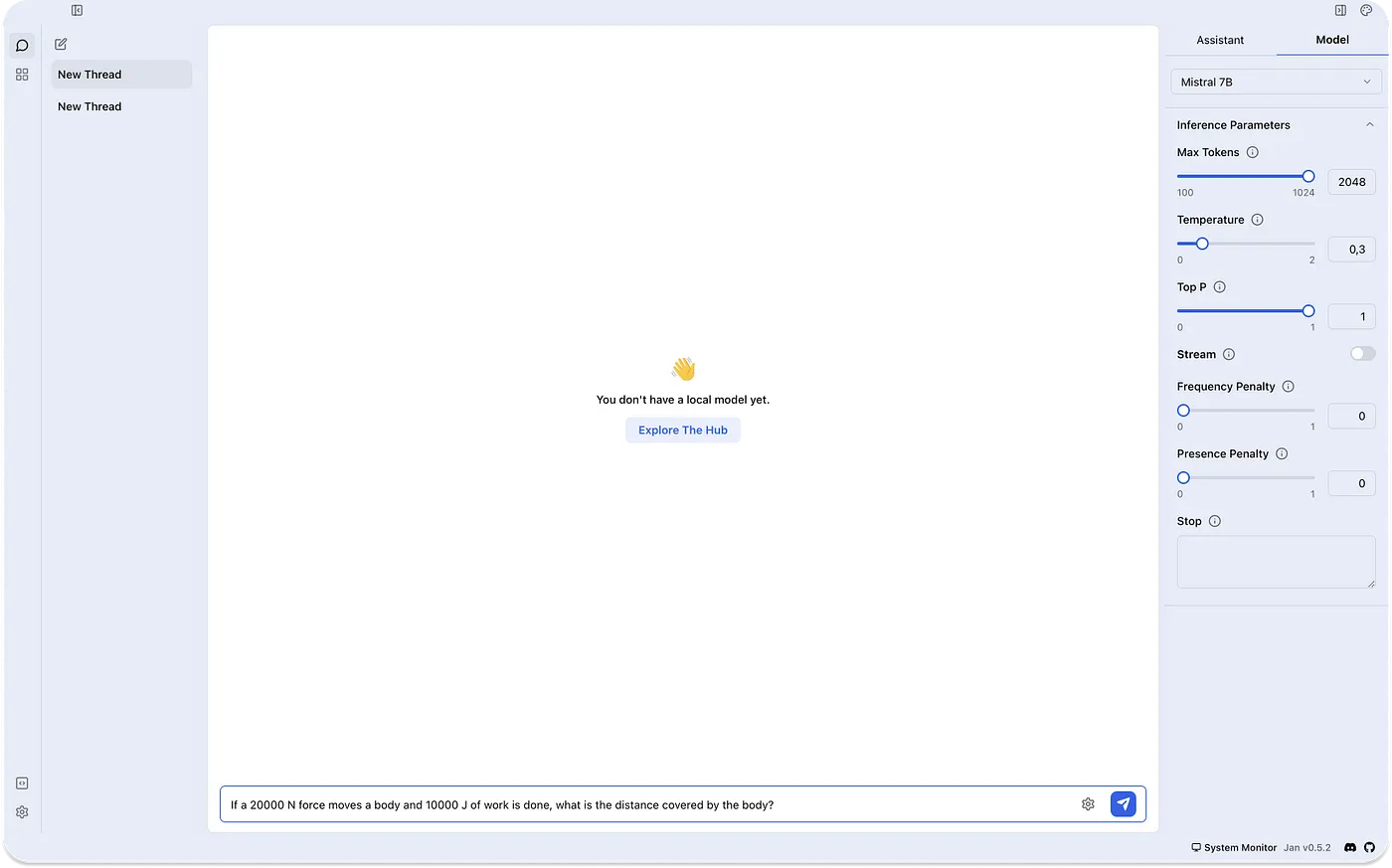
Jan 是一个具有类似 LM Studio 功能的 Electron 应用程序。它通过将消费级机器转变为 AI 计算机,使 AI 对所有人开放和易于访问。由于它是一个开源项目,开发人员可以为其贡献并扩展其功能。以下是对 Jan 的主要功能的概述。
- 本地运行 : 您可以在不连接互联网的情况下,在设备上运行您喜欢的AI模型。
- 即用模型 : 下载Jan后,您会获得一组已安装的模型以开始使用。您还可以搜索特定的模型。
- 模型导入 : 它支持从Hugging Face等来源导入模型。
- 免费、跨平台和开源 : Jan是100%免费、开源的,并且可以在Mac、Windows和Linux上运行。
- 自定义推理参数 : 调整模型参数,如最大令牌数、温度、流、频率惩罚等。所有偏好、模型使用和设置都将保留在您的计算机上。
- 扩展 : Jan支持像TensortRT和Inference Nitro这样的扩展,以定制和增强您的AI模型。
Jan 提供了一个干净简单的界面来与大语言模型交互,并且它将所有数据和处理信息都保存在本地。它已经安装了七十多个大型语言模型供您使用。这些现成的模型使得连接和与远程 API(如 OpenAI 和 Mistral)交互变得容易。Jan 还有一个很棒的 GitHub、Discord 和 Hugging Face 社区可以关注并寻求帮助。然而,就像所有 LLM 工具一样,它在 Apple Silicon Mac 上运行得比在 Intel Mac 上更快。
3. LlamafileLlamafile 得到了 Mozilla 的支持,其目标是通过使用快速的 CPU 推理(无需网络访问)使开源 AI 对每个人开放。它将大语言模型(LLMs)转换为多平台的 可执行链接格式(ELF)。它为将 AI 整合到应用程序中提供了最佳选择之一,允许您仅通过一个可执行文件运行 LLMs。
Llamafile 是如何工作的它旨在将权重转换为多个可执行程序,这些程序无需安装即可在Windows、MacOS、Linux、Intel、ARM、FreeBSD等架构上运行。在底层,Llamafile使用tinyBLAST在像Windows这样的操作系统上运行,而无需安装SDK。
Llamafile 的关键特性- 可执行文件 : 与其它LLM工具(如LM Studio和Jan)不同,Llamafile只需要一个可执行文件即可运行LLM。
- 使用现有模型 : Llamafile支持使用现有的模型工具,例如Ollama和LM Studio。
- 访问或创建模型 : 您可以访问来自OpenAI、Mistral、Groq等的流行LLM。它还提供了从零开始创建模型的支持。
- 模型文件转换 : 您可以将许多流行LLM的文件格式转换为另一种格式,例如,使用单个命令将
.gguf转换为.llamafile。
llamafile-convert mistral-7b.gguf

要安装 Llamafile,请访问 Huggingface 网站,从导航中选择 Models,然后搜索 Llamafile。您也可以从以下 URL 安装您喜欢的 量化 版本。
<https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/tree/main>
注意:量化数越大,响应越好。如上图所示,本文使用了 Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile,其中 Q6 表示量化数。
步骤 1:下载 Llamafile
从上面的链接中,点击任意的下载按钮来获取你所需的版本。如果你的机器上安装了wget 工具,你可以使用以下命令下载 Llamafile。
wget <https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/blob/main/Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile>
你应该用你喜欢的版本替换该URL。
步骤2:使Llamafile可执行
下载特定版本的Llamafile后,你应该通过导航到文件位置并使用以下命令使其具有可执行权限。
chmod +x Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile步骤 3: 运行 Llamafile
在文件名前添加一个点和正斜线 ./ 以启动 Llamafile。
./Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
Llamafile 应用现在可以在 http://127.0.0.1:8080 运行你的各种大语言模型。

Llamafile 通过使 LLM 在普通 CPU 上易于访问,帮助实现 AI 和 ML 的普及化。与其它本地 LLM 应用程序(如 Llama.cpp)相比,Llamafile 能提供更快的提示处理体验,并且在游戏电脑上表现更佳。由于其性能更快,它是总结长文本和大型文档的绝佳选择。Llamafile 完全离线且私密运行,因此用户无需将数据分享给任何 AI 服务器或 API。机器学习社区如 Hugging Face 支持 Llamafile 格式,使得查找与 Llamafile 相关的模型变得容易。它还拥有一个强大的开源社区,不断对其进行开发和扩展。
4. GPT4ALL
GPT4ALL 建立在隐私、安全和无需互联网连接的原则之上。用户可以安装它在 Mac、Windows 和 Ubuntu 系统上。与 Jan 或 LM Studio 相比,GPT4ALL 拥有更多每月下载量、GitHub Stars 和活跃用户。
GPT4ALL 的关键特性GPT4All 可以在主流消费级硬件上运行大型语言模型,例如 Mac M 系列芯片、AMD 和 NVIDIA GPU。以下是其主要功能。
- 隐私优先:将私人和敏感的聊天信息和提示仅保留在您的机器上。
- 无需互联网:它完全离线运行。
- 模型探索:此功能允许开发人员浏览和下载不同类型的LLM进行实验。您可以从流行的选项(如LLama、Mistral等)中选择大约1000个开源语言模型。
- 本地文档:您可以让本地LLM访问您的敏感数据,例如
.pdf和.txt等本地文档,而不会将数据从设备中移出或通过网络传输。 - 自定义选项:它提供了多个聊天机器人调整选项,例如温度、批处理大小、上下文长度等。
- 企业版:GPT4ALL提供了一个企业包,包括安全、支持和每设备许可证,以将本地AI带给企业。
要开始使用GPT4All在本地运行LLM,下载适合您操作系统的所需版本。
使用GPT4ALL的好处除了 Ollama 之外,GPT4ALL 拥有最多的 GitHub 贡献者数量,大约有 250000 个每月活跃用户(根据 https://www.nomic.ai/gpt4all),与其他竞争对手相比。该应用程序收集有关使用分析和聊天分享的匿名用户数据,但是用户可以选择加入或退出。使用 GPT4ALL,开发人员可以受益于其庞大的用户群体、GitHub 社区和 Discord 社区。
5. Ollama
使用 Ollama,你可以轻松地创建本地聊天机器人,而无需连接像 OpenAI 这样的 API。由于所有内容都在本地运行,你无需支付任何订阅或 API 调用费用。
Ollama 的关键特性- 模型自定义 : Ollama 允许你将
.gguf模型文件转换并使用ollama run modelname运行它们。 - 模型库 : Ollama 提供了一个庞大的模型库,你可以在 ollama.com/library 上尝试。
- 导入模型 : Ollama 支持从 PyTorch 导入模型。
- 社区集成 : Ollama 可以无缝集成到网络和桌面应用程序中,如 Ollama-SwiftUI,HTML UI,Dify.ai,以及 更多。
- 数据库连接 : Ollama 支持多个 数据平台。
- 移动集成 : 一个像 Enchanted 这样的 SwiftUI 应用程序将 Ollama 带到了 iOS、macOS 和 visionOS 上。Maid 也是一个跨平台的 Flutter 应用程序,可以与本地的
.gguf模型文件进行交互。
要首次使用 Ollama,请访问 https://ollama.com 并下载适合您机器的版本。您可以在 Mac、Linux 或 Windows 上安装它。安装完成后,您可以在终端中使用以下命令查看其详细信息。
ollama
要运行特定的大语言模型(LLM),你应该使用以下命令下载它:
ollama pull 模型名称,其中 模型名称 是你想要安装的模型的名称。你可以访问 GitHub 查看一些可以下载的示例模型。pull 命令也可以用于更新模型。一旦使用,只会获取更新的部分。
例如,在下载了 llama3.1 之后,在命令行中运行 ollama run llama3.1 即可启动模型。
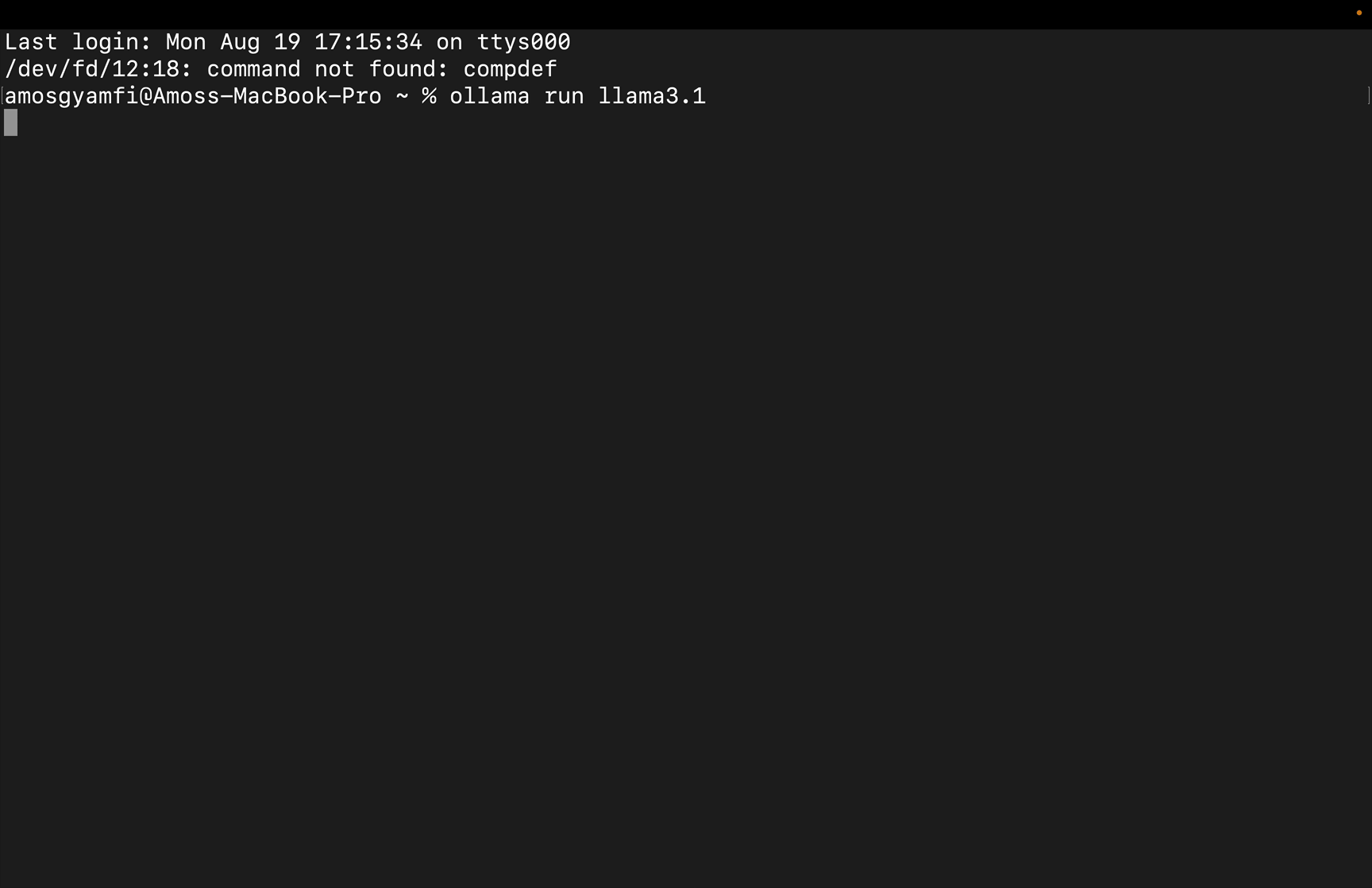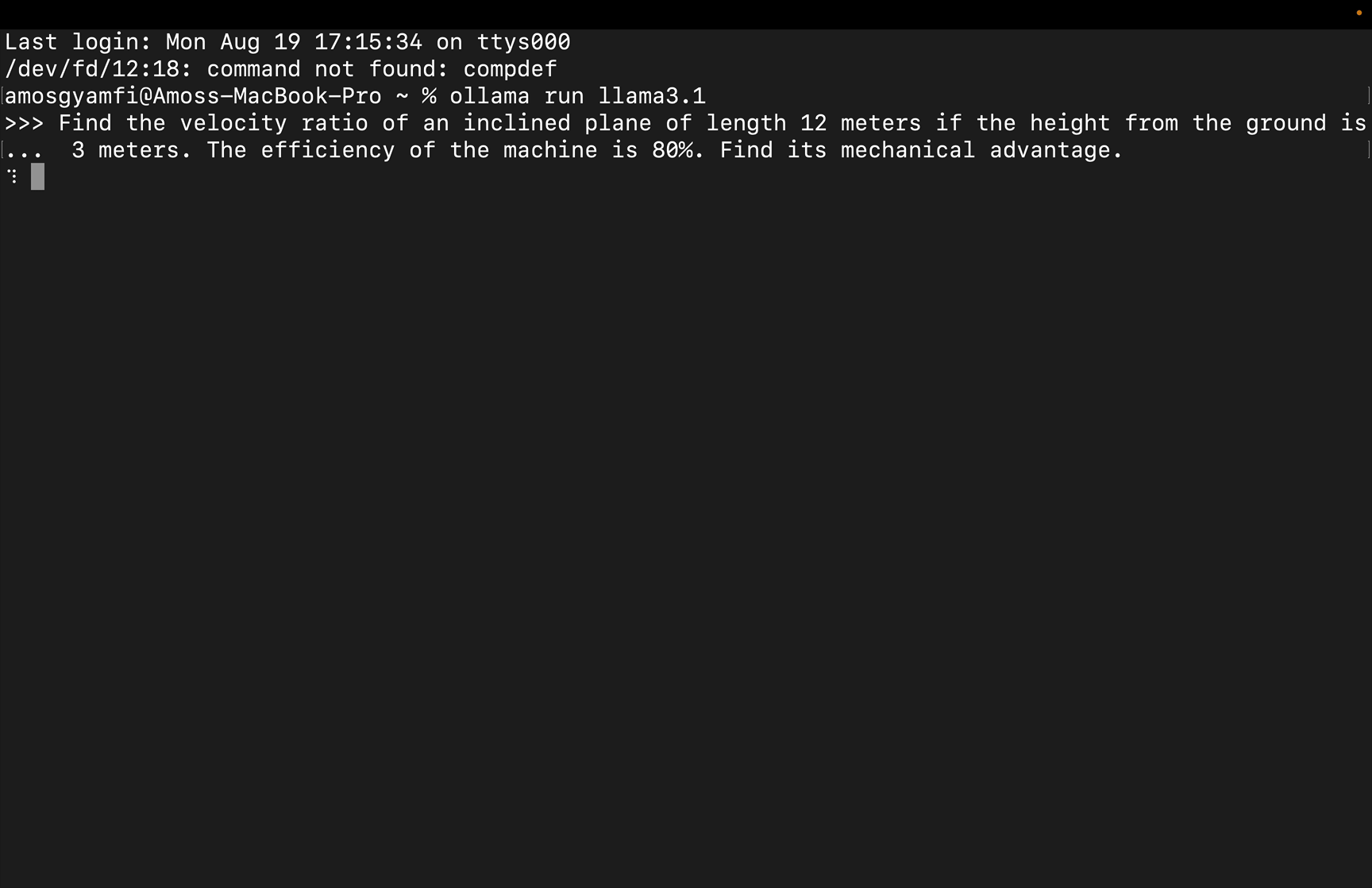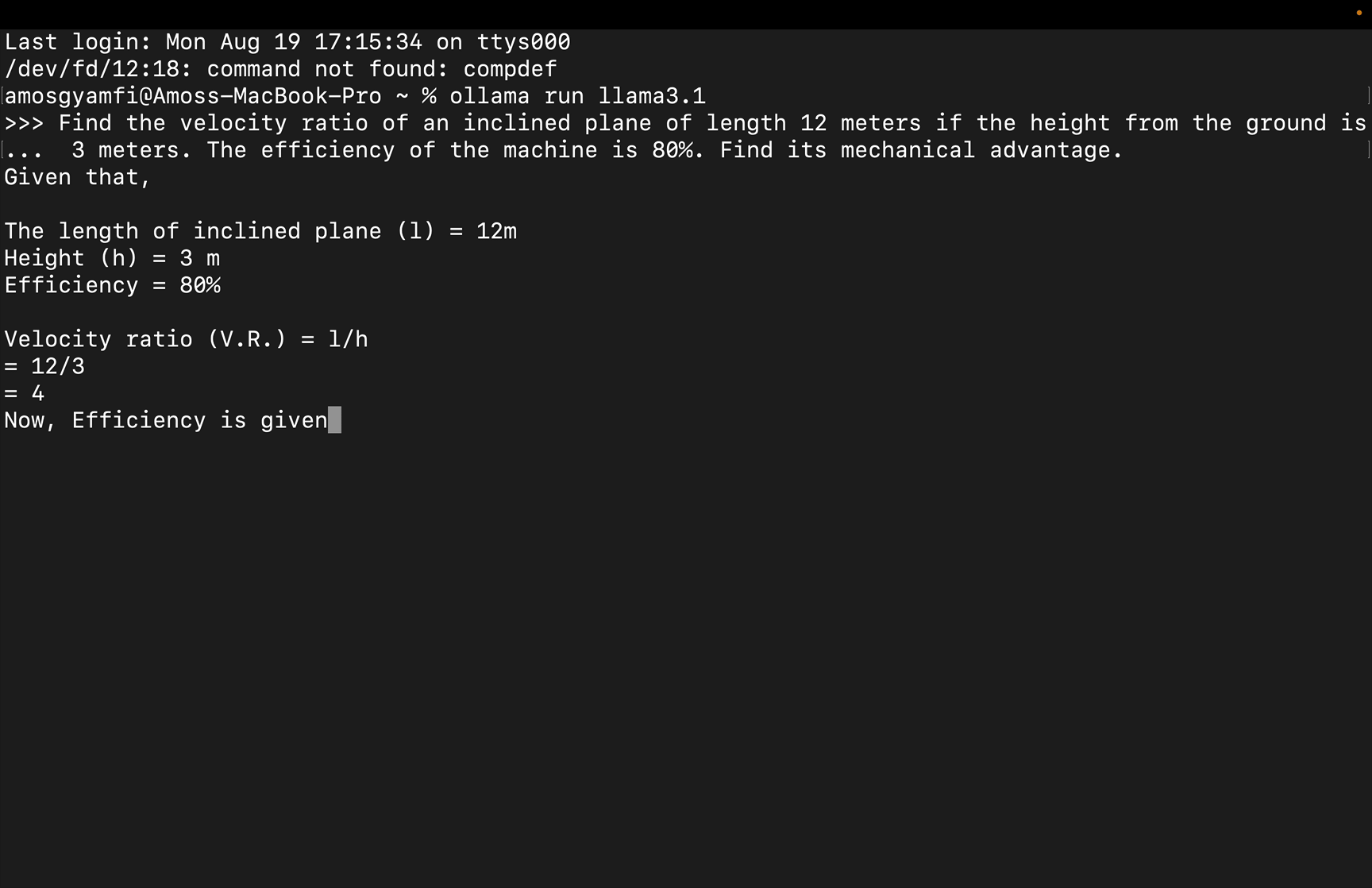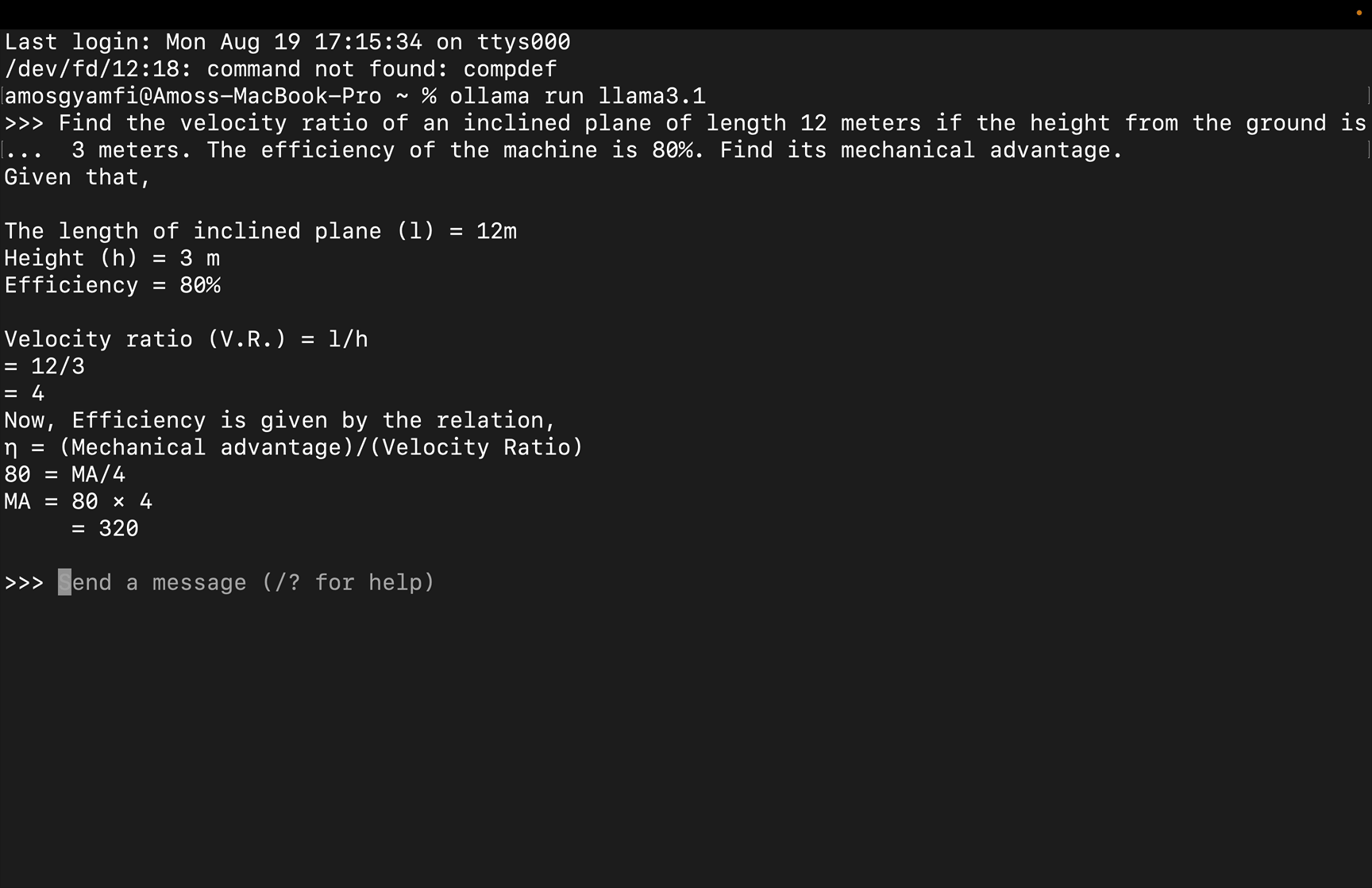
Ollama
在上面的例子中,我们提示 llama3.1 模型解决一个物理工作和能量问题。

Ollama 在 GitHub 上有超过 200 名活跃贡献者,并且它拥有最多的贡献者数量,在上述讨论的其他开源 LLM 工具中,它的可扩展性也更强。
6. LLaMa.cpp
LLaMa.cpp 是支撑本地 LLM 工具(如 Ollama 及许多其他工具)的底层后端技术(推理引擎)。LLaMa.cpp 可以在各种硬件上进行大规模语言模型的推理,并且只需少量配置就能实现出色的本地性能。它也可以在云端运行。
LLaMa.cpp 的关键特性- 安装 : 它的安装非常简单,只需一条命令即可完成。
- 性能 : 它在本地和云端的各种硬件上表现优异。
- 支持的模型 : 它支持流行和重要的大型语言模型,如Mistral 7B,Mixtral MoE,DBRX,Falcon,以及许多其他模型。
- 前端AI工具 : LLaMa.cpp 支持开源的LLM UI工具,如MindWorkAI/AI-Studio(FSL-1.1-MIT),iohub/collama等。
要使用 llama.cpp 运行您的第一个本地大型语言模型,您应该使用以下命令进行安装:
brew install llama.cpp
接下来,从Hugging Face或其他任何来源下载你想要运行的模型。例如,从Hugging Face下载下面的模型并将其保存到你计算机上的某个位置。
<https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.3-GGUF/resolve/main/Mistral-7B-Instruct-v0.3.Q4_K_M.gguf>
使用您喜欢的命令行工具(如终端),cd 切换到刚刚下载的 .gguf 模型文件所在位置,并运行以下命令。
llama-cli --color \
-m Mistral-7B-Instruct-v0.3.Q4_K_M.ggufb \
-p "写一个关于SwiftUI的简短介绍"总之,你首先调用 LLaMa 命令行工具并设置颜色和其他标志。-m 标志指定你想要使用的模型的路径。-p 标志指定你希望用来指示模型的提示。
运行上述命令后,你将在以下预览中看到结果。

LLaMa.cpp
本地LLM用例本地运行大语言模型(LLMs)可以帮助希望深入了解其性能和工作原理的开发人员。本地的大语言模型可以查询私人文档和技术论文,这样关于这些文档的信息就不会离开用于查询它们的设备,也不会传输到任何云端AI API。在没有互联网的地方或网络信号不佳的地方,本地的大语言模型也非常有用。
在远程医疗环境中,本地LLM可以对患者文件进行排序,而无需因隐私问题将文件上传到任何AI API提供商。
基于本地运行评估大语言模型性能在本地使用大型语言模型之前了解其性能对于获得所需响应至关重要。有几种方法可以确定特定大型语言模型(LLM)的性能。这里有一些方法。
- 训练:模型是用什么数据集训练的?
- 微调:模型可以定制到什么程度来执行专门的任务,或者它可以被微调到特定领域吗?
- 学术研究:LLM 是否有一篇学术研究论文?
为了回答上述问题,你可以查阅一些优秀的资源,如Hugging Face和Arxiv.org。此外,OpenLLMLeaderboard和LMSYS Chatbot Arena提供了各种LLM的详细信息和基准测试。
本地LLM工具总结如本文所述,选择和使用本地大型语言模型存在多种动机。如果您不希望将数据集通过互联网发送给AI API提供商,可以在远程医疗应用中对模型进行微调以执行特定任务。许多开源图形用户界面(基于GUI)的本地LLM工具,如LM Studio和Jan,提供了直观的前端UI,用于配置和实验LLM,而无需像OpenAI或Claude这样的基于订阅的服务。您还发现了各种强大的命令行LLM应用程序,如Ollama和LLaMa.cpp,这些应用程序可以帮助您在没有互联网连接的情况下本地运行和测试模型。请查看Stream的AI聊天机器人解决方案,以将AI聊天集成到您的应用中,并访问所有相关链接以了解更多信息。





