

Phi3 模型是微软小型语言模型的最新版本。它有四个变体(更多详情请参见此链接 https://azure.microsoft.com/en-us/blog/new-models-added-to-the-phi-3-family-available-on-microsoft-azure/)
- Phi-3-mini. 一个拥有3.8B参数的语言模型,提供两种上下文长度的版本(128K 和 4K)
- Phi-3-small. 一个拥有7B参数的语言模型,提供两种上下文长度的版本(128K 和 8K)
- Phi-3-medium. 一个拥有14B参数的语言模型,提供两种上下文长度的版本(128K 和 4K)
- Phi-3-vision 是一个拥有4.2B参数的多模态模型,具备语言和视觉能力
在这篇文章中,我对多模态视觉语言模型的应用感兴趣。正如官方文档中所述,Phi-3-Vision-128K-Instruct 是一个轻量级、最先进的开源多模态模型,适用于需要视觉和文本输入能力的通用人工智能系统和应用,具体要求包括:
- 内存/计算受限的环境;
- 延迟敏感的场景;
- 通用图像理解;
- OCR;
- 图表和表格理解。
在这篇文章中,我有兴趣检查当模型作为OCR用于个人文档(如身份证、驾驶证和健康保险卡)时的数据提取能力。测试中使用的文档是复印件,它们不是原件,也不属于真实的人。
这个故事的第二部分,我讨论了Phi3模型在处理变形文档中的应用以及用于使这些图像更易读的计算机视觉技术,可以在以下链接找到:
https://medium.com/@enrico.randellini/探索微软Phi3视觉语言模型作为OCR进行文档数据提取(第二部分)-904f6e1b9b2d
你可以在我的 Github 仓库的这个 链接 找到完整的笔记本。
模型实例为了在推理模式下使用模型,我构建了如下的环境
conda create -n llm_images python=3.10
conda activate llm_images
pip install torch==2.3.0 torchvision==0.18.0
pip install packaging
pip install pillow==10.3.0 chardet==5.2.0 flash_attn==2.5.8 accelerate==0.30.1 bitsandbytes==0.43.1 Requests==2.31.0 transformers==4.40.2 albumentations==1.3.1 opencv-contrib-python==4.10.0.84 matplotlib==3.9.0
pip uninstall jupyter
conda install -c anaconda jupyter
conda update jupyter
pip install --upgrade 'nbconvert>=7' 'mistune>=2'
pip install cchardet一旦环境可用,我就从Huggingface仓库下载了模型
# 导入必要的库
from PIL import Image
import requests
from transformers import AutoModelForCausalLM
from transformers import AutoProcessor
from transformers import BitsAndBytesConfig
import torch
from IPython.display import display
import time
# 定义模型ID
model_id = "microsoft/Phi-3-vision-128k-instruct"
# 加载处理器
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# 定义4位量化配置
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
)
# 使用4位量化加载模型并映射到CUDA
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
trust_remote_code=True,
torch_dtype="auto",
quantization_config=nf4_config,
)接下来,我准备了一个 Python 函数,该函数以消息和图片路径作为输入,发送给模型,并输出模型的输出。
def 模型推理(messages, path_image):
开始时间 = time.time()
image = Image.open(path_image)
# 使用图像标记准备提示
prompt = processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
# 处理提示和图像以供模型输入
inputs = processor(prompt, [image], return_tensors="pt").to("cuda:0")
# 使用模型生成文本响应
generate_ids = model.generate(
**inputs,
eos_token_id=processor.tokenizer.eos_token_id,
max_new_tokens=500,
do_sample=False,
)
# 从生成的响应中移除输入标记
generate_ids = generate_ids[:, inputs["input_ids"].shape[1] :]
# 解码生成的ID为文本
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
display(image)
结束时间 = time.time()
print("推理时间: {}".format(结束时间 - 开始时间))
# 打印生成的响应
print(response)以下我将展示如何从每种不同的文档中提取数据。根据文档的正面或背面,我准备了特定的提示,以识别我想提取的数据字段。
身份证OCR 正面对于意大利身份证的正面,我使用了以下提示来提取主要的个人信息,并将这些信息输出为JSON格式。
prompt_cie_front = [{"role": "user", "content": "\nOCR图像中的文本。提取以下字段的文本并以JSON格式输出:\
'Comune Di/ Municipality', 'COGNOME /Surname', 'NOME/NAME', 'LUOGO E DATA DI BATTESIMO/\
地点和出生日期', 'SESSO/SEX', 'STATURA/HEIGHT', 'CITADINANZA/NATIONALITY',\
'EMISSIONE/ ISSUING', 'SCADENZA /EXPIRY'. 读取右上角的代码并将其放入JSON字段 'CODE'"}]
# 从URL下载图像
path_image = "/home/randellini/llm_images/resources/cie_fronte.jpg"
# 推理
model_inference(prompt_cie_front, path_image)
意大利身份证的正面
对于上述图像,我得到了以下输出。可以注意到,唯一的卡号位于卡片的右上角,没有关联的字段。为了提取其值,我在提示中指定模型需要读取卡片右上角的代码,并将其放入名为“CODE”的JSON字段中。唯一的错误是唯一的代码中的第一个零被替换成了大写的字母O。
推理时间:9.793543815612793
{
"Comune Di/ Municipality": "SERENELLA MARITTIMA",
"COGNOME /Surname": "ROSSI",
"NOME/NAME": "BIANCA",
"LUOGO E DATA DI NASCITA": "PINO SULLA SPONDA DEL LAGO MAGGIORE (VA) 30.12.1964",
"SESSO/SEX": "F",
"STATURA/HEIGHT": "180",
"CITADINANZA/NATIONALITY": "ITA",
"EMISSIONE/ ISSUING": "30.05.2022",
"SCADENZA /EXPIRY": "30.12.2031",
"CODE": "CAO000AA"
}为了提取背面的数据,我使用了以下提示
prompt_cie_back = [{"role": "user", "content": "\n识别图像中的文本。提取以下字段的文本内容并以JSON格式输出:\
'CODICE FISCALE/FISCAL CODE', 'ESTREMI ATTO DI NASCITA', 'INDIRIZZO DI RESIDENZA/RESIDENCE'"}]
# 从URL下载图像
path_image = "/home/randellini/llm_images/resources/cie_retro.jpg"
# 推理
model_inference(prompt_cie_back, path_image)
意大利身份证的背面
我得到了以下结果。只有一个错误,即财政代码中缺失第三个大写的S字符。
推理时间:4.082342147827148
{
"codice_fiscale": "RSBNC64T70G677R",
"estremi_atto_di_nascita": "00000.0A00",
"indirizzo_di_residenza": "Via Salaria, 712"
}对于意大利驾驶执照的正面,我使用了以下提示
prompt_ld_front = [{"role": "user", "content": "\nOCR图像中的文本。提取以下字段的文本,并以JSON格式呈现:\
'1.', '2.', '3.', '4a.', '4b.', '4c.', '5.','9.'"}]
# 从URL下载图像
path_image = "/home/randellini/llm_images/resources/patente_fronte.png"
# 推理
model_inference(prompt_ld_front, path_image)
意大利驾驶许可证的正面
获得的结果为
推理时间:5.2030909061431885
{
"1": "ROSSI",
"2": "MARIA",
"3": "01/01/65",
"4a": "01/03/2014",
"4b": "01/01/2025",
"4c": "MIT-UCO",
"5": "A0A000000A",
"9": "B"
}对于意大利驾照的背面,目前我还没有找到合适的提示来读取表格中带有“9.”、“10.”、“11.”和“12.”列的值。此外,“12.”出现了两次。第一次作为表格中的一列名称,第二次作为卡片左下角的一个字段。
这个字段很重要,因为它警告驾驶者有特别的义务。例如,代码01表示驾驶时必须佩戴眼镜或隐形眼镜。
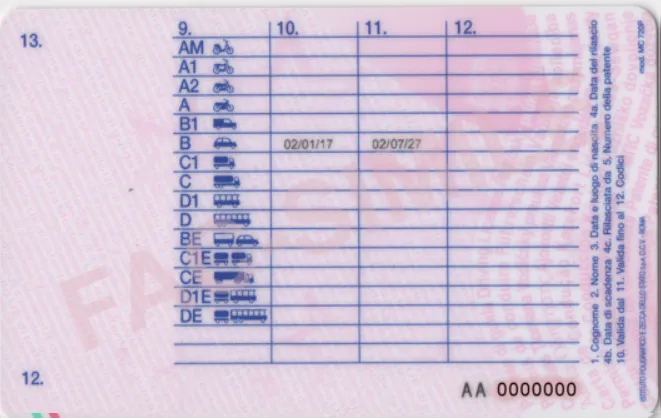
意大利驾驶执照卡片的背面
健康保险卡 OCR 正面为了读取意大利健康保险卡正面的值,我使用了提示
prompt_hic_front = [{"role": "user", "content": "\nOCR图像中的文本。提取以下字段的文本,并以JSON格式输出:\
'Codice Fiscale', 'Sesso', 'Cognome', 'Nome', 'Luogo di nascita', 'Provincia', 'Data di nascita', 'Data di scadenza'"}]
# 从URL下载图像
path_image = "/home/randellini/llm_images/resources/tessera_sanitaria_fronte.jpg"
# 推理
model_inference(prompt_hic_front, path_image)
意大利健康保险卡的正面
我获得了以下结果
推理时间:7.003508806228638
```json
{
"Codice Fiscale": "RSSMRO62B25E205Y",
"Sesso": "M",
"Cognome": "ROSSI",
"Nome": "MARIO",
"Luogo di nascita": "CASSINA DE' PECCHI",
"Provincia": "MI",
"Data di nascita": "25/02/1962",
"Data di scadenza": "10/10/2019"
}
## 后面
为了读取卡片的背面,我使用了以下提示
```python
prompt_hic_back = [{"role": "user", "content": "\nOCR图像中的文本。提取以下字段的文本,并以JSON格式输出:\
'3 Cognome', '4 Nome', '5 Data di nascita', '6 Numero identificativo personale', '7 Numero identificazione dell'istituzione', 'Numero di identificazione della tessera', '9 Scadenza'"}]
# 从URL下载图像
path_image = "/home/randellini/llm_images/resources/tessera_sanitaria_retro.jpg"
# 推理
model_inference(prompt_hic_back, path_image)
意大利健康保险卡的背面
获取
推理时间:7.403932809829712
{
"3 姓氏": "ROSSI",
"4 名字": "MARIO",
"5 出生日期": "25/02/1962",
"6 个人识别号": "RSSMRO62B25E205Y",
"7 机构识别号": "0030 - LOMBARDIA",
"证件编号": "80380800301234567890",
"9 有效期": "01/01/2006"
}如果你喜欢这篇帖子并且认为它很有趣,给它点个掌声吧!





