

我最初从GIDS 2024 的我的演讲中分享了这篇博客。如果你参加了那次演讲,感谢你的到来,希望对你有所帮助!如果没有参加,没关系,你仍然可以通过我提供的资源和链接获得相关信息。我已经把演讲的内容写出来了,这样你可以根据需要通过幻灯片来了解更多的背景信息。
关键信息 演讲摘要版希望 GIDS 的 folks 也会发布视频。一旦视频可用,我会添加链接。
设置上下文我只有30分钟的时间——所以我讲得简短而精炼!
基础模型(FMs)是生成式AI的核心。这些模型在海量数据上进行了预训练。大型语言模型(LLMs)是FMs的一类。例如,Anthropic的Claude系列,Meta的Llama等。
你通常通过专用平台访问这些服务。例如,Amazon Bedrock 是一个完全托管的服务,提供多种可通过 API 访问的模型。这些模型非常强大,可以独立使用来构建生成式 AI 应用。
所以我们为什么需要向量数据库?
为了更好地理解这一点,让我们先退一步,谈谈大型语言模型(LLMs)的局限性。我将突出一些常见的局限性。
大型语言模型的限制- 知识截止:这些模型的知识通常局限于它们预训练或微调时的数据。
- 幻觉:有时,这些模型会提供一个错误的答案,而且非常“自信”。

另一个问题是缺乏对外部数据源的访问。
想想看——你可以创建一个 AWS 账户并开始在 Amazon Bedrock 上使用模型。但是,如果你想构建符合你业务需求的生成式 AI 应用程序,你需要特定领域的或公司特定的私有数据(例如,一个可以访问客户详情、订单信息等的客户服务聊天机器人)。
现在你可以用你的数据来训练或微调这些模型——但这并不简单且成本效益不高。但是有一些方法可以绕过这些限制——RAG(稍后会讨论)就是其中之一,而向量数据库也扮演着关键的角色。
深入了解向量数据库在我们开始之前,让我们先理解一下..
什么是向量?
简单来说 — 向量是文本的数值表示。
- 有一个输入文本(也称为提示)
- 你将其通过一个称为 embedding模型 的东西——可以将其视为一个无状态函数
- 你得到一个输出,即一个浮点数数组
重要的是要理解,向量捕捉的是语义含义。因此,它们可以用于相关性或上下文基于的搜索,而不是简单的文本搜索。

我倾向于将向量数据库分为两种类型:
- 在现有数据库(如 PostgreSQL、Redis、OpenSearch、MongoDB、Cassandra 等)中支持向量数据类型。
- 另一类是专门的向量数据库,如 Pinecone、Weaviate、Milvus、Qdrant、ChromaDB 等。
这个领域发展也非常快,我相信在不久的将来我们会看到更多新事物!
现在你可以在AWS上运行这些专门的向量存储,通过他们专门的云服务。但我想要快速地向你展示一下我之前提到的第一类中的选择。
它们作为原生的 AWS 数据库受到支持
这包括:
- Amazon OpenSearch 服务
- 兼容 PostgreSQL 的 Amazon Aurora
- 兼容 MongoDB 的 Amazon DocumentDB
- 当前正在预览中的支持向量搜索的 Amazon MemoryDB for Redis (撰写时)
以下是向量数据库在生成式AI解决方案中的简化位置示意图
- 你将特定领域的数据进行分割/切片
- 将它们通过嵌入模型处理——这会给你一些向量或嵌入
- 将这些嵌入存储在向量数据库中
- 然后有一些应用程序执行语义搜索查询,并以各种方式将它们组合起来(RAG就是其中之一)
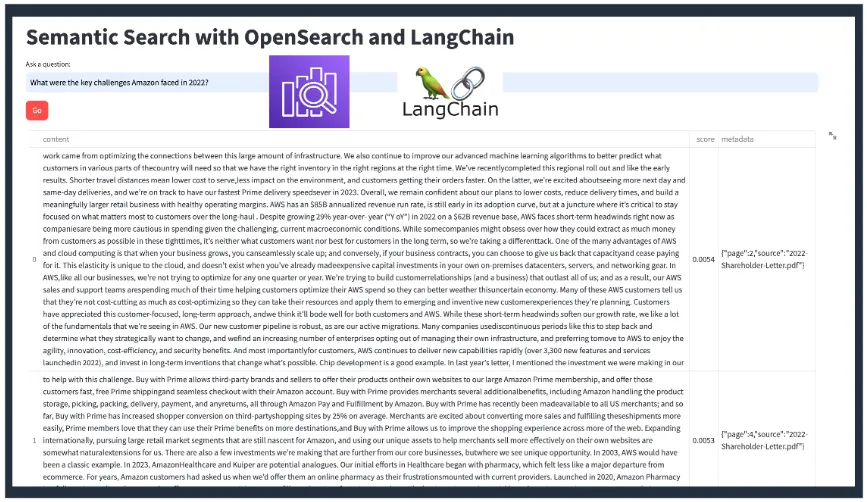
详情请参见此处 — https://github.com/abhirockzz/langchain-opensearch-rag
RAG — 增强检索的生成技术我们讨论了大型语言模型(LLM)的限制,包括知识截止、幻觉、无法访问内部数据等。当然,有多种方法可以克服这些问题。
- 提示工程技巧:零样本、少量样本等。确实这很经济实惠,但如何应用于特定领域的数据呢?
- 微调:使用特定数据集对现有的大语言模型进行训练。但涉及的基础设施和成本如何解决?你希望成为一家模型开发公司还是专注于你的核心业务?
这些只是几个例子。
RAG技术采用了一种折中的方法。
RAG 工作流包含两个关键部分:
第一部分: 数据摄入是指你将原始数据(如 pdf、文本、图片等)进行拆分,通过嵌入模型处理后存储到向量数据库中。
第二部分: 这部分涉及最终用户的应用程序(例如聊天机器人)。用户发送查询——该输入通过与处理原始数据相同的嵌入模型转换为向量嵌入,然后我们执行语义或相似性搜索以获取最接近的前 N 个结果。
那还不止。
第三部分: 这些结果,也称为“上下文”,然后与用户输入和一个专门的提示结合。最后将这些内容发送到一个大语言模型(LLM)——请注意,这不是嵌入模型,而是一个大型语言模型。提示中添加的上下文有助于模型更准确和相关地回答用户的查询。
示例 2(共 3 个)—— 使用 OpenSearch 和 LangChain 实现 RAG
详情请参见此处 — https://github.com/abhirockzz/langchain-opensearch-rag
完全托管的RAG体验 — Amazon Bedrock知识库另一种方法是使用托管解决方案来处理繁重的工作。例如,如果你使用Amazon Bedrock,那么知识库可以使RAG变得更简单和易于管理。它支持整个RAG工作流,从摄取、检索到提示增强。
它支持多种向量存储来存储向量嵌入数据。


详情请参见这里 — https://github.com/abhirockzz/langchain-opensearch-rag
现在我们如何使用这个来构建RAG应用程序呢?
对于应用集成,这是通过API暴露的:
-
RetrieveAndGenerate: 调用 API,获取响应 — 就这么简单。所有操作(查询嵌入、语义搜索、提示工程、LLM编排)都由系统处理!
- Retrieve: 用于自定义 RAG 工作流,只需提取前 N 个响应(如语义搜索),其余部分根据需要进行集成。
- 文档是一个很好的起点!特别是关于 知识库
- Amazon Bedrock 代码示例
- 在 生成式 AI 社区空间 上有很多内容和实用解决方案!
- 最终,没有比动手学习更好的方法了。前往 Amazon Bedrock 开始构建吧!
就这样。正如我所说,我只有30分钟,所以尽量简明扼要!这个领域发展得非常快。这包括向量数据库、LLMs(几乎每周都有一个新的——感觉就像JavaScript框架时代一样!)、框架(比如LangChain等)。跟上这些变化很难,但请记住,基础原理是一样的。关键是要掌握它们——希望这能帮助到你。
祝你构建愉快!




