
照片由 Susan Holt Simpson 在 Unsplash 提供
编写我们自己的当我决定深入研究Transformer架构时,我经常在网上阅读或观看教程时感到沮丧,因为我感觉它们总是有所遗漏:
- 官方的Tensorflow或Pytorch教程使用了它们自己的API,因此保持了高层次的抽象,迫使我去查看它们的代码库以了解底层的实现。这非常耗时,并且有时阅读成千上万行代码并不容易。
- 我找到的其他使用自定义代码的教程(文章末尾有链接),往往过于简化了用例,并且没有涉及诸如处理变长序列批处理掩码等概念。
因此,我决定自己编写一个Transformer,以确保我理解这些概念,并能够将其用于任何数据集。
在本文中,我们将采取一种系统的方法,分层分块地实现一个Transformer。
显然,已经有许多不同的实现以及来自 Pytorch 或 Tensorflow 的高级 API 可以直接使用,它们——我相信——性能会比我们将要构建的模型更好。
“好的,但是为什么不用TF/Pytorch的实现呢?”
本文的目的在于教育,并没有意图超越 Pytorch 或 Tensorflow 的实现。我相信,关于 transformer 的理论和代码并不是一目了然的,因此我希望通过这一步步的教程,能让你们更好地理解这些概念,并在以后编写自己的代码时感到更加得心应手。
另一个从零开始构建你自己的Transformer的原因是,这将使你完全理解如何使用上述API。如果我们看一下Pytorch实现的Transformer类的forward()方法,你会看到很多晦涩的关键词,如:

来源 : Pytorch 文档
如果你已经熟悉这些关键词,那么你可以跳过这篇文章。
否则,本文将带您详细了解每个关键字及其背后的概念。
一个非常简短的Transformer介绍如果你已经听说过ChatGPT或Gemini,那么你之前就已经遇到过Transformer了。实际上,ChatGPT中的“T”就代表Transformer。
该架构最早由谷歌研究人员在2017年的“Attention is All you need”论文中提出。它非常革命性,因为之前的模型在进行序列到序列的学习(如机器翻译、语音转文本等)时依赖于RNN,而RNN在计算上比较昂贵,因为它们需要逐步骤处理序列,而Transformer只需要一次性查看整个序列,将时间复杂度从O(n)降低到了O(1)。

在自然语言处理领域,Transformer的应用非常广泛,包括语言翻译、问答系统、文档摘要、文本生成等。
变压器的整体架构如下所示:
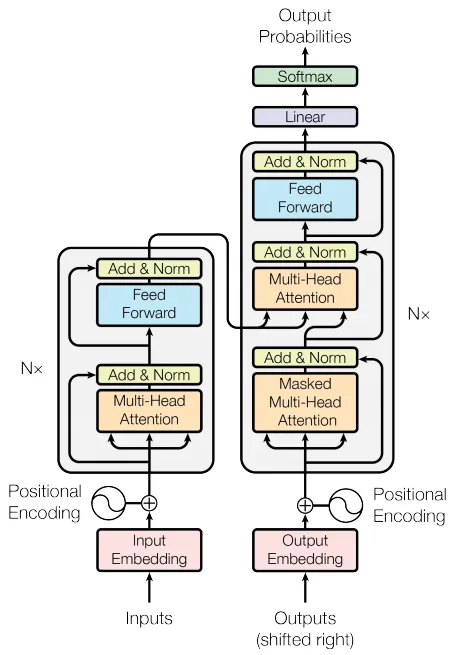
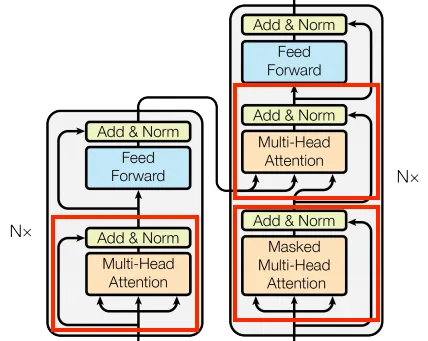
我们将要实现的第一个模块实际上是Transformer中最重要的一部分,称为多头注意力。让我们看看它在整个架构中的位置。
注意力机制实际上并不特定于Transformer,并且已经在RNN序列到序列模型中使用过。
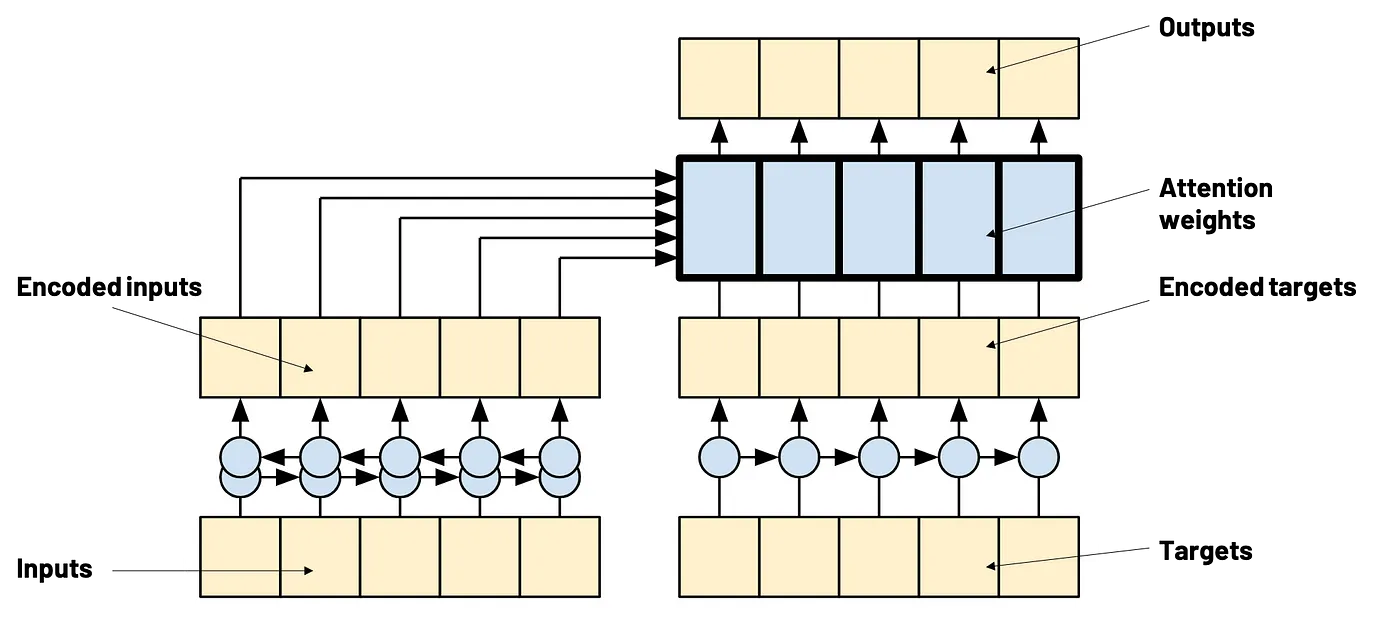
注意力机制在Transformer中的应用(来源:Tensorflow 文档)
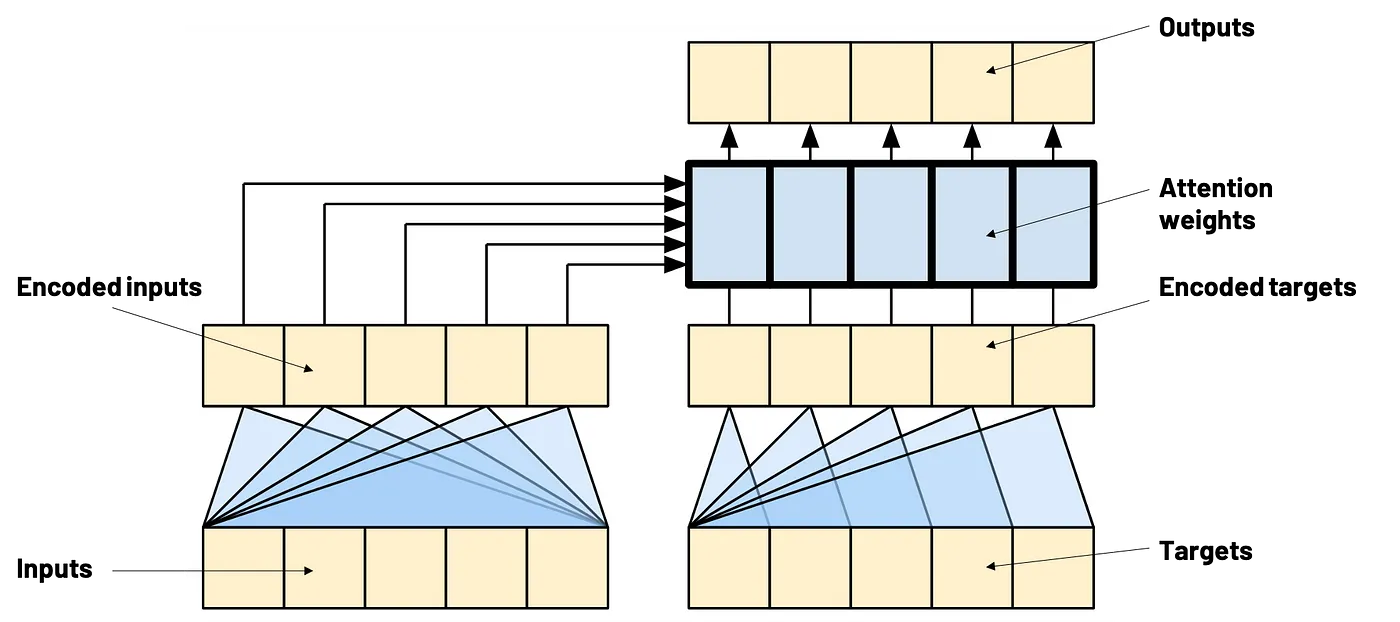
注意力机制在Transformer中的实现(来源:Tensorflow 文档)
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, hidden_dim=256, num_heads=4):
"""
input_dim: 输入的维度。
num_heads: 注意头的数量。
"""
super(MultiHeadAttention, self).__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
assert hidden_dim % num_heads == 0, "隐藏维度必须能被头的数量整除"
self.Wv = nn.Linear(hidden_dim, hidden_dim, bias=False) # 值部分
self.Wk = nn.Linear(hidden_dim, hidden_dim, bias=False) # 键部分
self.Wq = nn.Linear(hidden_dim, hidden_dim, bias=False) # 查询部分
self.Wo = nn.Linear(hidden_dim, hidden_dim, bias=False) # 输出层
def check_sdpa_inputs(self, x):
assert x.size(1) == self.num_heads, f"期望x的大小为({-1, self.num_heads, -1, self.hidden_dim // self.num_heads}), 得到{x.size()}"
assert x.size(3) == self.hidden_dim // self.num_heads
def scaled_dot_product_attention(
self,
query,
key,
value,
attention_mask=None,
key_padding_mask=None):
"""
query : 形状为 (batch_size, num_heads, query_sequence_length, hidden_dim//num_heads) 的张量
key : 形状为 (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads) 的张量
value : 形状为 (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads) 的张量
attention_mask : 形状为 (query_sequence_length, key_sequence_length) 的张量
key_padding_mask : 形状为 (sequence_length, key_sequence_length) 的张量
"""
self.check_sdpa_inputs(query)
self.check_sdpa_inputs(key)
self.check_sdpa_inputs(value)
d_k = query.size(-1)
tgt_len, src_len = query.size(-2), key.size(-2)
# logits = (B, H, tgt_len, E) * (B, H, E, src_len) = (B, H, tgt_len, src_len)
logits = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 注意力掩码
if attention_mask is not None:
if attention_mask.dim() == 2:
assert attention_mask.size() == (tgt_len, src_len)
attention_mask = attention_mask.unsqueeze(0)
logits = logits + attention_mask
else:
raise ValueError(f"注意力掩码大小 {attention_mask.size()}")
# 键掩码
if key_padding_mask is not None:
key_padding_mask = key_padding_mask.unsqueeze(1).unsqueeze(2) # 广播到批量大小,头数
logits = logits + key_padding_mask
attention = torch.softmax(logits, dim=-1)
output = torch.matmul(attention, value) # (batch_size, num_heads, sequence_length, hidden_dim)
return output, attention
def split_into_heads(self, x, num_heads):
batch_size, seq_length, hidden_dim = x.size()
x = x.view(batch_size, seq_length, num_heads, hidden_dim // num_heads)
return x.transpose(1, 2) # 最终维度为 (batch_size, num_heads, seq_length, , hidden_dim // num_heads)
def combine_heads(self, x):
batch_size, num_heads, seq_length, head_hidden_dim = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, num_heads * head_hidden_dim)
def forward(
self,
q,
k,
v,
attention_mask=None,
key_padding_mask=None):
"""
q : 形状为 (batch_size, query_sequence_length, hidden_dim) 的张量
k : 形状为 (batch_size, key_sequence_length, hidden_dim) 的张量
v : 形状为 (batch_size, key_sequence_length, hidden_dim) 的张量
attention_mask : 形状为 (query_sequence_length, key_sequence_length) 的张量
key_padding_mask : 形状为 (sequence_length, key_sequence_length) 的张量
"""
q = self.Wq(q)
k = self.Wk(k)
v = self.Wv(v)
q = self.split_into_heads(q, self.num_heads)
k = self.split_into_heads(k, self.num_heads)
v = self.split_into_heads(v, self.num_heads)
# attn_values, attn_weights = self.multihead_attn(q, k, v, attn_mask=attention_mask)
attn_values, attn_weights = self.scaled_dot_product_attention(
query=q,
key=k,
value=v,
attention_mask=attention_mask,
key_padding_mask=key_padding_mask,
)
grouped = self.combine_heads(attn_values)
output = self.Wo(grouped)
self.attention_weigths = attn_weights
return output我们需要在这里解释一些概念。
1) 查询、键和值。query 是你试图匹配的信息,
key 和 values 是存储的信息。
想想这就像使用字典一样:每当使用Python字典时,如果查询不匹配字典的键,你将不会得到任何返回。但如果我们希望字典能够返回一些非常接近的信息怎么办?比如我们有这样的字典:
d = {"panther": 1, "bear": 10, "dog": 3}
d["wolf"] = 0.2*d["panther"] + 0.7*d["dog"] + 0.1*d["bear"]这基本上就是注意力机制的原理:查看数据的不同部分,并将它们融合以获得对查询的回答的综合结果。
相关代码部分如下,这里我们计算查询和键之间的注意力权重
logits = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # 我们计算注意力的权重并且在这里,我们将归一化的权重应用到值上:
attention = torch.softmax(logits, dim=-1)
output = torch.matmul(attention, value) # (batch_size, num_heads, sequence_length, hidden_dim)在处理序列输入的部分时,我们不希望包含无用或被禁止的信息。
无用的信息例如填充:填充符号用于将一批中的所有序列对齐到相同的序列长度,我们的模型应该忽略这些填充符号。我们将在最后一节再回到这个话题。
禁止信息稍微复杂一些。在训练过程中,模型学习将输入序列编码,并将目标与输入对齐。然而,在推理过程中,模型需要查看之前发出的标记来预测下一个标记(想想在ChatGPT中的文本生成),因此在训练过程中也需要应用相同的规则。
这就是为什么我们要应用一个因果掩码,以确保在每个时间步中,目标只能看到来自过去的信息。下面是应用掩码的相关代码段(计算掩码的过程在后面介绍)
if attention_mask is not None:
if attention_mask.dim() == 2:
assert attention_mask.size() == (tgt_len, src_len)
attention_mask = attention_mask.unsqueeze(0)
logits = logits + attention_mask它对应于Transformer的以下部分:
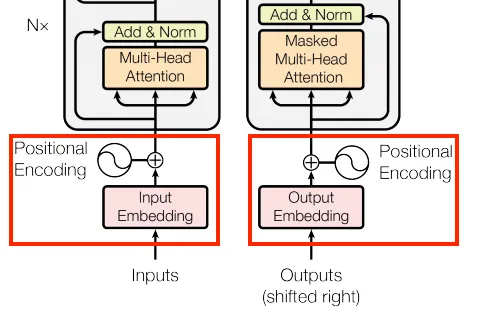
当接收和处理输入时,Transformer 并没有顺序感,因为它将整个序列视为一个整体来处理,这与 RNN 的处理方式相反。因此,我们需要添加一些时间顺序的提示,以便 Transformer 能够学习依赖关系。
位置编码的具体工作原理超出了本文的讨论范围,但您可以阅读原始论文来了解。
# Taken from https://pytorch.org/tutorials/beginner/transformer_tutorial.html#define-the-model
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
"""
参数:
x: Tensor, 形状为 ``[batch_size, seq_len, embedding_dim]``
"""
x = x + self.pe[:, :x.size(1), :]
return x我们快要有一个完整的编码器了!编码器是Transformer的左半部分。

我们将代码中添加一个小部分,即前向传播部分:
class 位置-wise 前向传播(nn.Module):
def __init__(self, d_model: int, d_ff: int):
super(位置-wise 前向传播, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))将这些部分组合起来,我们就得到了一个 Encoder 模块!
class EncoderBlock(nn.Module):
def __init__(self, n_dim: int, dropout: float, n_heads: int):
super(EncoderBlock, self).__init__()
self.mha = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm1 = nn.LayerNorm(n_dim)
self.ff = PositionWiseFeedForward(n_dim, n_dim)
self.norm2 = nn.LayerNorm(n_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, src_padding_mask=None):
assert x.ndim==3, "Expected input to be 3-dim, got {}".format(x.ndim)
att_output = self.mha(x, x, x, key_padding_mask=src_padding_mask)
x = x + self.dropout(self.norm1(att_output))
ff_output = self.ff(x)
output = x + self.norm2(ff_output)
return output如图所示,Encoder 实际上包含 N 个 Encoder 块或层,以及一个用于输入的 Embedding 层。因此,让我们通过添加 Embedding、Positional Encoding 和 Encoder 块来创建一个 Encoder:
class Encoder(nn.Module):
def __init__(
self,
vocab_size: int,
n_dim: int,
dropout: float,
n_encoder_blocks: int,
n_heads: int):
super(Encoder, self).__init__()
self.n_dim = n_dim
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=n_dim
)
self.positional_encoding = PositionalEncoding(
d_model=n_dim,
dropout=dropout
)
self.encoder_blocks = nn.ModuleList([
EncoderBlock(n_dim, dropout, n_heads) for _ in range(n_encoder_blocks)
])
def forward(self, x, padding_mask=None):
x = self.embedding(x) * math.sqrt(self.n_dim)
x = self.positional_encoding(x)
for block in self.encoder_blocks:
x = block(x=x, src_padding_mask=padding_mask)
return x解码器部分是左边的部分,需要稍微多做一些调整。
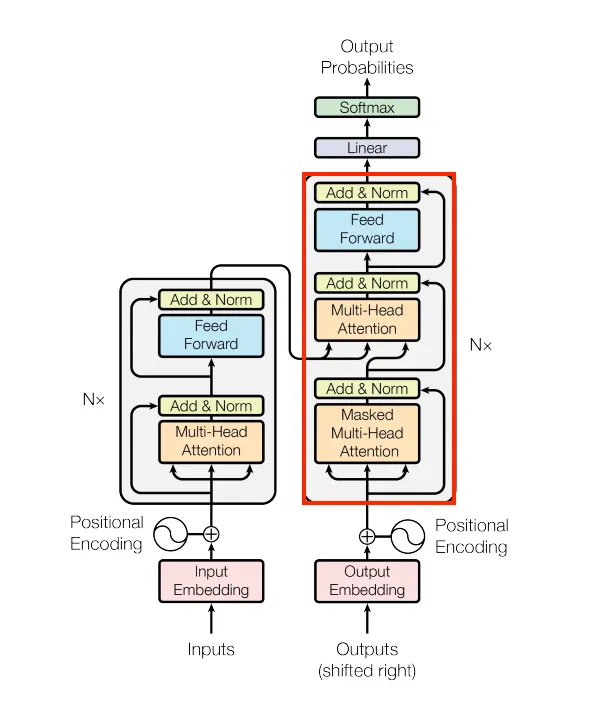
有一个叫做 Masked Multi-Head Attention 的东西。还记得我们之前提到的 causal mask 吗?这里就是用到它的地方。我们将使用 Multi-head attention 模块的 attention_mask 参数来表示这一点(关于如何计算掩码的更多细节将在后面说明):
# 一些前置代码
self.self_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
masked_att_output = self.self_attention(
q=tgt,
k=tgt,
v=tgt,
attention_mask=tgt_mask, <-- 这里就是因果掩码
key_padding_mask=tgt_padding_mask)
# 一些后置代码第二种注意力称为 交叉注意力。它将使用解码器的查询与编码器的键和值进行匹配!注意:在训练过程中,它们的长度可能不同,因此通常最好明确地定义输入的预期形状,如下所示:
def scaled_dot_product_attention(
self,
query,
key,
value,
attention_mask=None,
key_padding_mask=None):
"""
query : 形状为 (batch_size, num_heads, query_sequence_length, hidden_dim//num_heads) 的张量
key : 形状为 (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads) 的张量
value : 形状为 (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads) 的张量
attention_mask : 形状为 (query_sequence_length, key_sequence_length) 的张量
key_padding_mask : 形状为 (sequence_length, key_sequence_length) 的张量
"""在这里,我们使用编码器的输出,称为 memory ,与解码器的输入一起:
# 前置内容
self.cross_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
cross_att_output = self.cross_attention(
q=x1,
k=memory,
v=memory,
attention_mask=None, <-- 这里没有使用因果掩码
key_padding_mask=memory_padding_mask) <-- 我们需要使用源端的填充掩码
# 后置内容将这些部分组合起来,我们得到了解码器的结构如下:
class DecoderBlock(nn.Module):
def __init__(self, n_dim: int, dropout: float, n_heads: int):
super(DecoderBlock, self).__init__()
# 第一个Multi-Head Attention使用掩码来避免查看未来的信息
self.self_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm1 = nn.LayerNorm(n_dim)
# 第二个Multi-Head Attention将从编码器中获取键/值输入
self.cross_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm2 = nn.LayerNorm(n_dim)
self.ff = PositionWiseFeedForward(n_dim, n_dim)
self.norm3 = nn.LayerNorm(n_dim)
# self.dropout = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, tgt_padding_mask=None, memory_padding_mask=None):
masked_att_output = self.self_attention(
q=tgt, k=tgt, v=tgt, attention_mask=tgt_mask, key_padding_mask=tgt_padding_mask)
x1 = tgt + self.norm1(masked_att_output)
cross_att_output = self.cross_attention(
q=x1, k=memory, v=memory, attention_mask=None, key_padding_mask=memory_padding_mask)
x2 = x1 + self.norm2(cross_att_output)
ff_output = self.ff(x2)
output = x2 + self.norm3(ff_output)
return output
class Decoder(nn.Module):
def __init__(
self,
vocab_size: int,
n_dim: int,
dropout: float,
n_decoder_blocks: int,
n_heads: int):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=n_dim,
padding_idx=0
)
self.positional_encoding = PositionalEncoding(
d_model=n_dim,
dropout=dropout
)
self.decoder_blocks = nn.ModuleList([
DecoderBlock(n_dim, dropout, n_heads) for _ in range(n_decoder_blocks)
])
def forward(self, tgt, memory, tgt_mask=None, tgt_padding_mask=None, memory_padding_mask=None):
x = self.embedding(tgt)
x = self.positional_encoding(x)
for block in self.decoder_blocks:
x = block(
x,
memory,
tgt_mask=tgt_mask,
tgt_padding_mask=tgt_padding_mask,
memory_padding_mask=memory_padding_mask)
return x记得我们在多头注意力部分提到,在进行注意力操作时会排除输入的某些部分。
在训练过程中,我们考虑输入和目标的批量处理,其中每个实例可能具有不同的长度。以下是一个例子,我们将4个单词:香蕉、西瓜、梨、蓝莓进行批量处理。为了将它们作为一个批量处理,我们需要将所有单词对齐到最长单词(西瓜)的长度。因此,我们将为每个单词添加一个额外的填充标记PAD,使它们的长度都与西瓜相同。
在下面的图片中,上表表示原始数据,下表表示编码版本:
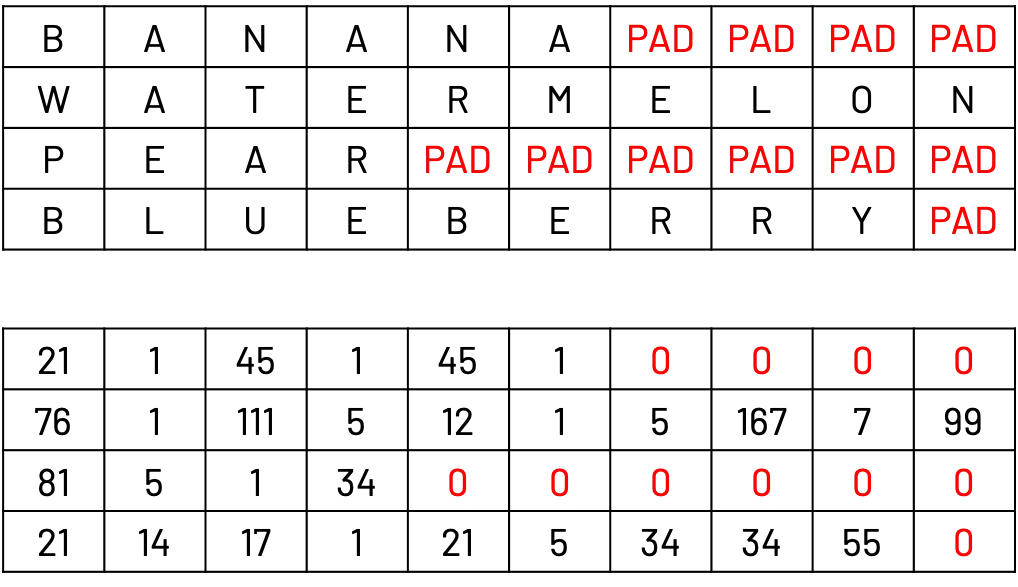
(作者供图)
在我们的情况下,我们希望从计算的注意力权重中排除填充索引。因此,我们可以为源数据和目标数据计算一个掩码,如下所示:
padding_mask = (x == PAD_IDX)现在来说说因果掩码吧?如果我们在每个时间步上希望模型只能关注过去的时间步,这意味着对于每个时间步 T,模型只能关注从 1 到 T 的每个时间步 t。这是一个双重循环,因此我们可以使用一个矩阵来计算这一点:
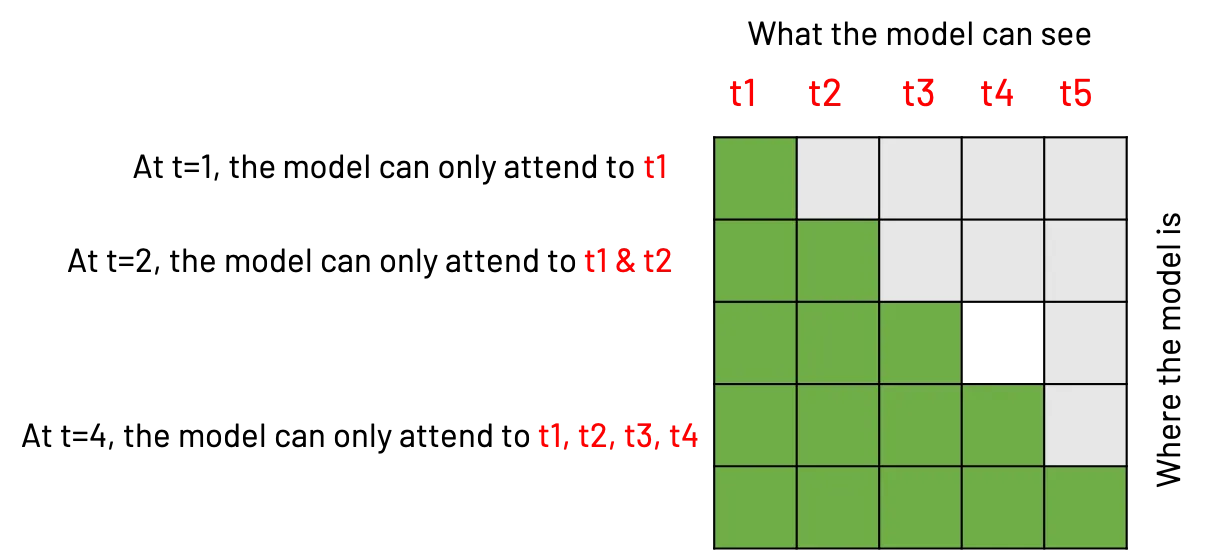
(图片由作者提供)
def generate_square_subsequent_mask(size: int):
"""生成一个三角形(size, size)的掩码。来自 PyTorch 文档。"""
mask = (1 - torch.triu(torch.ones(size, size), diagonal=1)).bool()
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask现在让我们通过将各个部分组合起来构建我们的Transformer!
在我们的用例中,我们将使用一个非常简单的数据集来展示Transformer实际上是如何学习的。
“但是为什么要用Transformer来反转单词呢?我已经知道可以用Python中的word[::-1]来做到这一点!”
这里的目的是看看Transformer的注意力机制是否有效。我们期望看到的是,在给定输入序列时,注意力权重会从右向左移动。如果是这样的话,这意味着我们的Transformer已经学会了非常简单的从右向左读取的语法,并且在进行实际的语言翻译时,可以推广到更复杂的语法。
让我们首先从自定义的Transformer类开始:
import torch
import torch.nn as nn
import math
from .encoder import Encoder
from .decoder import Decoder
class Transformer(nn.Module):
def __init__(self, **kwargs):
super(Transformer, self).__init__()
for k, v in kwargs.items():
print(f" * {k}={v}")
self.vocab_size = kwargs.get('vocab_size')
self.model_dim = kwargs.get('model_dim')
self.dropout = kwargs.get('dropout')
self.n_encoder_layers = kwargs.get('n_encoder_layers')
self.n_decoder_layers = kwargs.get('n_decoder_layers')
self.n_heads = kwargs.get('n_heads')
self.batch_size = kwargs.get('batch_size')
self.PAD_IDX = kwargs.get('pad_idx', 0)
self.encoder = Encoder(
self.vocab_size, self.model_dim, self.dropout, self.n_encoder_layers, self.n_heads)
self.decoder = Decoder(
self.vocab_size, self.model_dim, self.dropout, self.n_decoder_layers, self.n_heads)
self.fc = nn.Linear(self.model_dim, self.vocab_size)
@staticmethod
def generate_square_subsequent_mask(size: int):
"""生成一个三角形(size, size)掩码。来自PyTorch文档。"""
mask = (1 - torch.triu(torch.ones(size, size), diagonal=1)).bool()
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def encode(
self,
x: torch.Tensor,
) -> torch.Tensor:
"""
输入
x: (B, S) 其中元素在 (0, C) 范围内,C 是类别数
输出
(B, S, E) 嵌入
"""
mask = (x == self.PAD_IDX).float()
encoder_padding_mask = mask.masked_fill(mask == 1, float('-inf'))
# (B, S, E)
encoder_output = self.encoder(
x,
padding_mask=encoder_padding_mask
)
return encoder_output, encoder_padding_mask
def decode(
self,
tgt: torch.Tensor,
memory: torch.Tensor,
memory_padding_mask=None
) -> torch.Tensor:
"""
B = 批量大小
S = 源序列长度
L = 目标序列长度
E = 模型维度
输入
encoded_x: (B, S, E)
y: (B, L) 其中元素在 (0, C) 范围内,C 是类别数
输出
(B, L, C) 对数
"""
mask = (tgt == self.PAD_IDX).float()
tgt_padding_mask = mask.masked_fill(mask == 1, float('-inf'))
decoder_output = self.decoder(
tgt=tgt,
memory=memory,
tgt_mask=self.generate_square_subsequent_mask(tgt.size(1)),
tgt_padding_mask=tgt_padding_mask,
memory_padding_mask=memory_padding_mask,
)
output = self.fc(decoder_output) # 形状 (B, L, C)
return output
def forward(
self,
x: torch.Tensor,
y: torch.Tensor,
) -> torch.Tensor:
"""
输入
x: (B, Sx) 其中元素在 (0, C) 范围内,C 是类别数
y: (B, Sy) 其中元素在 (0, C) 范围内,C 是类别数
输出
(B, L, C) 对数
"""
# 编码器输出形状 (B, S, E)
encoder_output, encoder_padding_mask = self.encode(x)
# 解码器输出形状 (B, L, C)
decoder_output = self.decode(
tgt=y,
memory=encoder_output,
memory_padding_mask=encoder_padding_mask
)
return decoder_output我们需要添加一个方法,该方法将作为著名的 model.predict(类似于 scikit-learn 中的功能)。目标是让模型在给定输入的情况下动态输出预测结果。在推理过程中,没有目标:模型首先通过关注输出来输出一个令牌,然后使用自己的预测来继续输出令牌。这就是为什么这些模型通常被称为自回归模型,因为它们使用过去的预测来预测下一个令牌。
贪婪解码的问题在于它在每一步都考虑概率最高的词。如果最初的几个词完全错误,这会导致非常糟糕的预测。还有其他解码方法,例如束搜索,它会考虑一个候选序列的短名单(想象一下在每个时间步保留前 k 个词而不是取 argmax),并返回总概率最高的序列。
目前,让我们实现贪心解码并将其添加到我们的Transformer模型中:
def 预测(
self,
x: torch.Tensor,
sos_idx: int=1,
eos_idx: int=2,
max_length: int=None
) -> torch.Tensor:
"""
在推理时使用的方法。从x中逐个令牌预测y。此方法为贪心解码。
如果需要提高准确性,可以使用束搜索代替。
输入
x: str
输出
(B, L, C) logits
"""
# 用句子开头和结尾的令牌填充令牌
x = torch.cat([
torch.tensor([sos_idx]),
x,
torch.tensor([eos_idx])]
).unsqueeze(0)
encoder_output, mask = self.transformer.encode(x) # (B, S, E)
if not max_length:
max_length = x.size(1)
outputs = torch.ones((x.size()[0], max_length)).type_as(x).long() * sos_idx
for step in range(1, max_length):
y = outputs[:, :step]
probs = self.transformer.decode(y, encoder_output)
output = torch.argmax(probs, dim=-1)
# 如果需要查看逐步骤预测,取消注释
# print(f"Knowing {y} we output {output[:, -1]}")
if output[:, -1].detach().numpy() in (eos_idx, sos_idx):
break
outputs[:, step] = output[:, -1]
return outputs我们定义了一个小型数据集,该数据集反转单词,这意味着“helloworld”将返回“dlrowolleh”:
import numpy as np
import torch
from torch.utils.data import Dataset
np.random.seed(0)
def generate_random_string():
length = np.random.randint(10, 20)
return "".join([chr(x) for x in np.random.randint(97, 97+26, length)])
class ReverseDataset(Dataset):
def __init__(self, n_samples, pad_idx, sos_idx, eos_idx):
super(ReverseDataset, self).__init__()
self.pad_idx = pad_idx
self.sos_idx = sos_idx
self.eos_idx = eos_idx
self.values = [generate_random_string() for _ in range(n_samples)]
self.labels = [x[::-1] for x in self.values]
def __len__(self):
return len(self.values) # 数据集中样本的数量
def __getitem__(self, index):
return self.text_transform(self.values[index].rstrip("\n")), \
self.text_transform(self.labels[index].rstrip("\n"))
def text_transform(self, x):
return torch.tensor([self.sos_idx] + [ord(z)-97+3 for z in x] + [self.eos_idx])我们现在将定义训练和评估步骤:
PAD_IDX = 0
SOS_IDX = 1
EOS_IDX = 2
def 训练(model, 优化器, 加载器, 损失函数, epoch):
model.train()
损失 = 0
准确率 = 0
损失历史 = []
准确率历史 = []
with tqdm(loader, position=0, leave=True) as tepoch:
for x, y in tepoch:
tepoch.set_description(f"Epoch {epoch}")
优化器.zero_grad()
logits = model(x, y[:, :-1])
损失值 = 损失函数(logits.contiguous().view(-1, model.vocab_size), y[:, 1:].contiguous().view(-1))
损失值.backward()
优化器.step()
损失 += 损失值.item()
预测值 = logits.argmax(dim=-1)
掩码预测值 = 预测值 * (y[:, 1:]!=PAD_IDX)
准确率值 = (掩码预测值 == y[:, 1:]).float().mean()
准确率 += 准确率值.item()
损失历史.append(损失值.item())
准确率历史.append(准确率值.item())
tepoch.set_postfix(loss=损失值.item(), accuracy=100. * 准确率值.item())
return 损失 / len(list(loader)), 准确率 / len(list(loader)), 损失历史, 准确率历史
def 评估(model, 加载器, 损失函数):
model.eval()
损失 = 0
准确率 = 0
损失历史 = []
准确率历史 = []
for x, y in tqdm(loader, position=0, leave=True):
logits = model(x, y[:, :-1])
损失值 = 损失函数(logits.contiguous().view(-1, model.vocab_size), y[:, 1:].contiguous().view(-1))
损失 += 损失值.item()
预测值 = logits.argmax(dim=-1)
掩码预测值 = 预测值 * (y[:, 1:]!=PAD_IDX)
准确率值 = (掩码预测值 == y[:, 1:]).float().mean()
准确率 += 准确率值.item()
损失历史.append(损失值.item())
准确率历史.append(准确率值.item())
return 损失 / len(list(loader)), 准确率 / len(list(loader)), 损失历史, 准确率历史并且训练模型几个epoch:
import torch
import time
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
from mpl_toolkits.axes_grid1 import ImageGrid
def collate_fn(batch):
"""
此函数使用 PAD_IDX 对输入进行填充,使批次具有相等的长度
"""
src_batch, tgt_batch = [], []
for src_sample, tgt_sample in batch:
src_batch.append(src_sample)
tgt_batch.append(tgt_sample)
src_batch = pad_sequence(src_batch, padding_value=PAD_IDX, batch_first=True)
tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_IDX, batch_first=True)
return src_batch, tgt_batch
# 模型超参数
args = {
'vocab_size': 128,
'model_dim': 128,
'dropout': 0.1,
'n_encoder_layers': 1,
'n_decoder_layers': 1,
'n_heads': 4
}
# 定义模型
model = Transformer(**args)
# 实例化数据集
train_iter = ReverseDataset(50000, pad_idx=PAD_IDX, sos_idx=SOS_IDX, eos_idx=EOS_IDX)
eval_iter = ReverseDataset(10000, pad_idx=PAD_IDX, sos_idx=SOS_IDX, eos_idx=EOS_IDX)
dataloader_train = DataLoader(train_iter, batch_size=256, collate_fn=collate_fn)
dataloader_val = DataLoader(eval_iter, batch_size=256, collate_fn=collate_fn)
# 在调试过程中,我们确保源和目标确实被反转了
# s, t = next(iter(dataloader_train))
# print(s[:4, ...])
# print(t[:4, ...])
# print(s.size())
# 初始化模型参数
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
# 定义损失函数:我们忽略填充标记的 logits
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.98), eps=1e-9)
# 保存历史记录到字典
history = {
'train_loss': [],
'eval_loss': [],
'train_acc': [],
'eval_acc': []
}
# 主循环
for epoch in range(1, 4):
start_time = time.time()
train_loss, train_acc, hist_loss, hist_acc = train(model, optimizer, dataloader_train, loss_fn, epoch)
history['train_loss'] += hist_loss
history['train_acc'] += hist_acc
end_time = time.time()
val_loss, val_acc, hist_loss, hist_acc = evaluate(model, dataloader_val, loss_fn)
history['eval_loss'] += hist_loss
history['eval_acc'] += hist_acc
print(f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Train acc: {train_acc:.3f}, Val loss: {val_loss:.3f}, Val acc: {val_acc:.3f} Epoch time = {(end_time - start_time):.3f}s")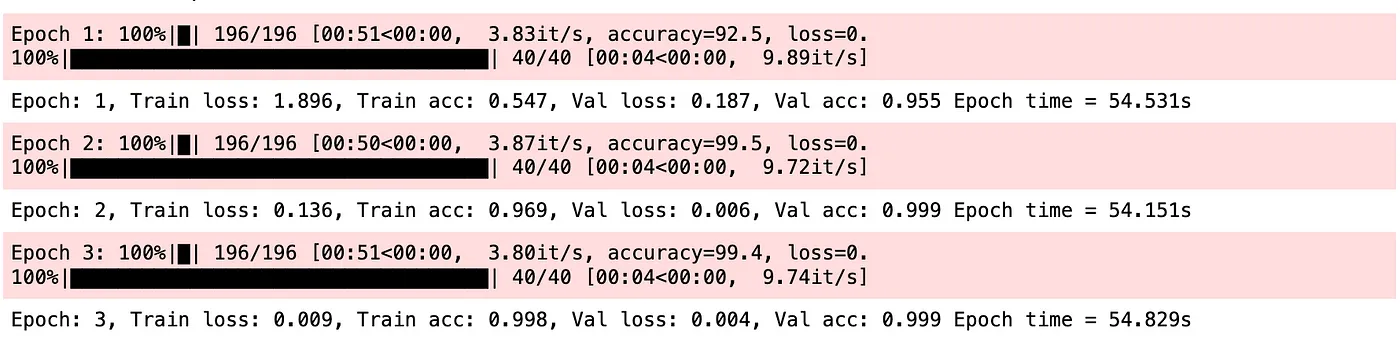
我们定义了一个小函数来访问注意力头的权重:
fig = plt.figure(figsize=(10., 10.))
images = model.decoder.decoder_blocks[0].cross_attention.attention_weigths[0,...].detach().numpy()
grid = ImageGrid(fig, 111, # 与 subplot(111) 类似
nrows_ncols=(2, 2), # 创建 2x2 的轴网格
axes_pad=0.1, # 轴之间的英寸间隔
)
for ax, im in zip(grid, images):
# 遍历网格会返回 Axes。
ax.imshow(im)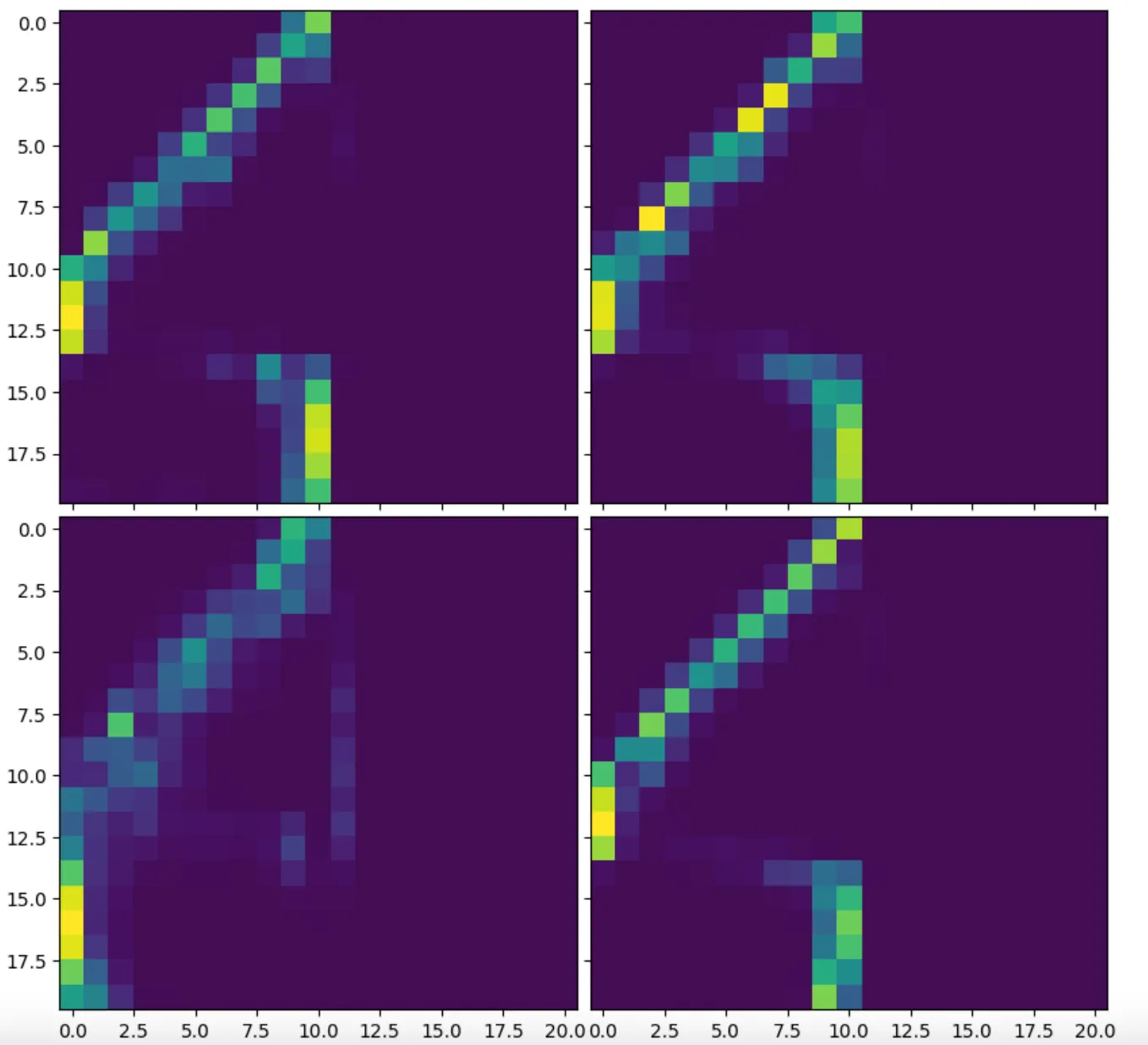
图片来自作者
我们可以看到一个很好的从右到左的模式,当从顶部读取权重时。y轴底部的垂直部分可能确实代表了由于填充掩码导致的掩权重。
测试我们的模型!为了用新数据测试我们的模型,我们将定义一个小小的 Translator 类来帮助我们进行解码:
class Translator(nn.Module):
def __init__(self, transformer):
super(Translator, self).__init__()
self.transformer = transformer
@staticmethod
def str_to_tokens(s):
return [ord(z)-97+3 for z in s]
@staticmethod
def tokens_to_str(tokens):
return "".join([chr(x+94) for x in tokens])
def __call__(self, sentence, max_length=None, pad=False):
x = torch.tensor(self.str_to_tokens(sentence))
x = torch.cat([torch.tensor([SOS_IDX]), x, torch.tensor([EOS_IDX])]).unsqueeze(0)
encoder_output, mask = self.transformer.encode(x) # (B, S, E)
if not max_length:
max_length = x.size(1)
outputs = torch.ones((x.size()[0], max_length)).type_as(x).long() * SOS_IDX
for step in range(1, max_length):
y = outputs[:, :step]
probs = self.transformer.decode(y, encoder_output)
output = torch.argmax(probs, dim=-1)
print(f"知道 {y} 我们输出 {output[:, -1]}")
if output[:, -1].detach().numpy() in (EOS_IDX, SOS_IDX):
break
outputs[:, step] = output[:, -1]
return self.tokens_to_str(outputs[0])
translator = Translator(model)你应该能够看到以下内容:
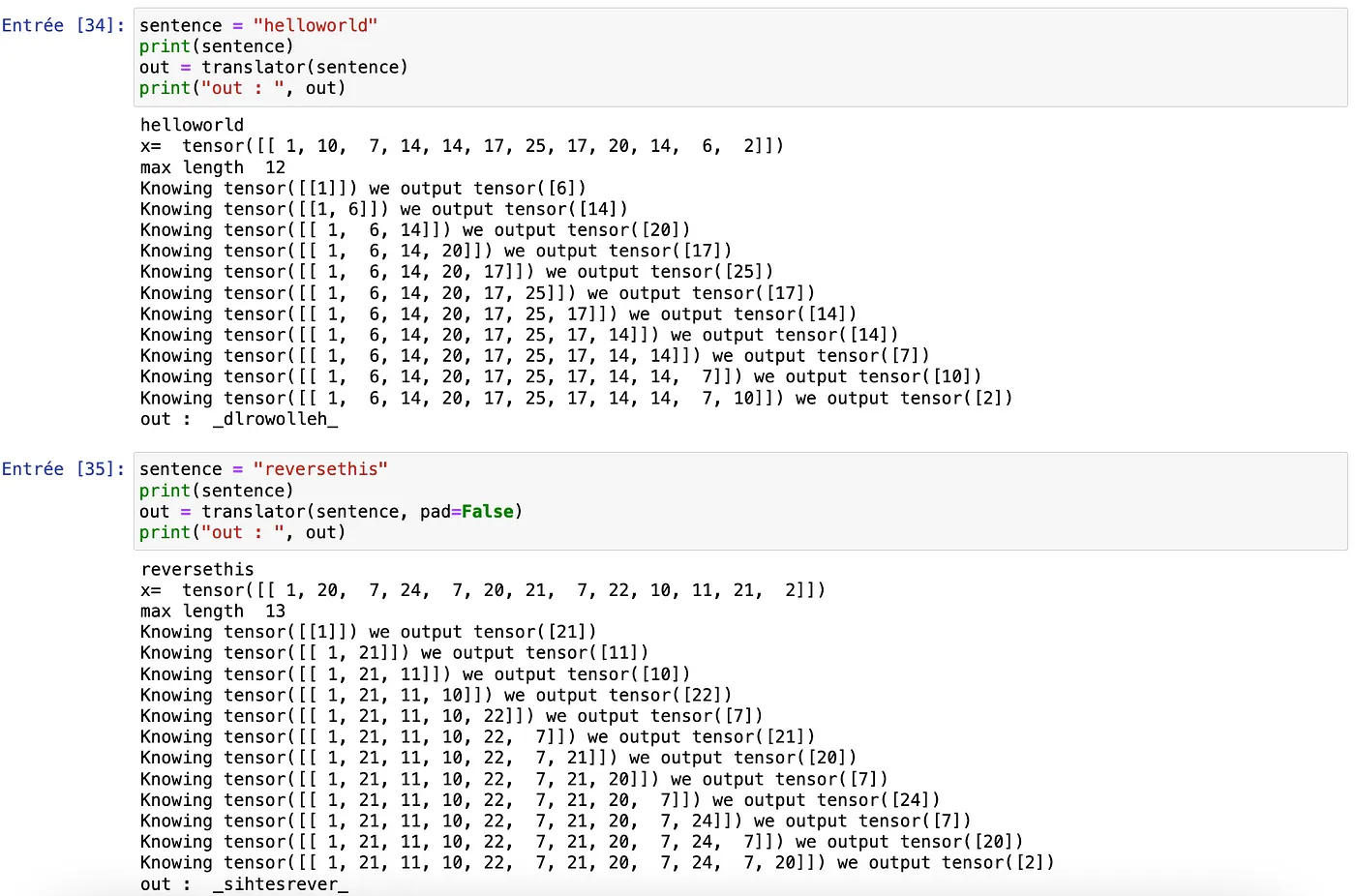
如果我们打印注意力头,将会观察到以下内容:
fig = plt.figure()
images = model.decoder.decoder_blocks[0].cross_attention.attention_weigths[0,...].detach().numpy().mean(axis=0)
fig, ax = plt.subplots(1,1, figsize=(10., 10.))
# 遍历网格会返回 Axes。
ax.set_yticks(range(len(out)))
ax.set_xticks(range(len(sentence)))
ax.xaxis.set_label_position('top')
ax.set_xticklabels(iter(sentence))
ax.set_yticklabels([f"step {i}" for i in range(len(out))])
ax.imshow(images)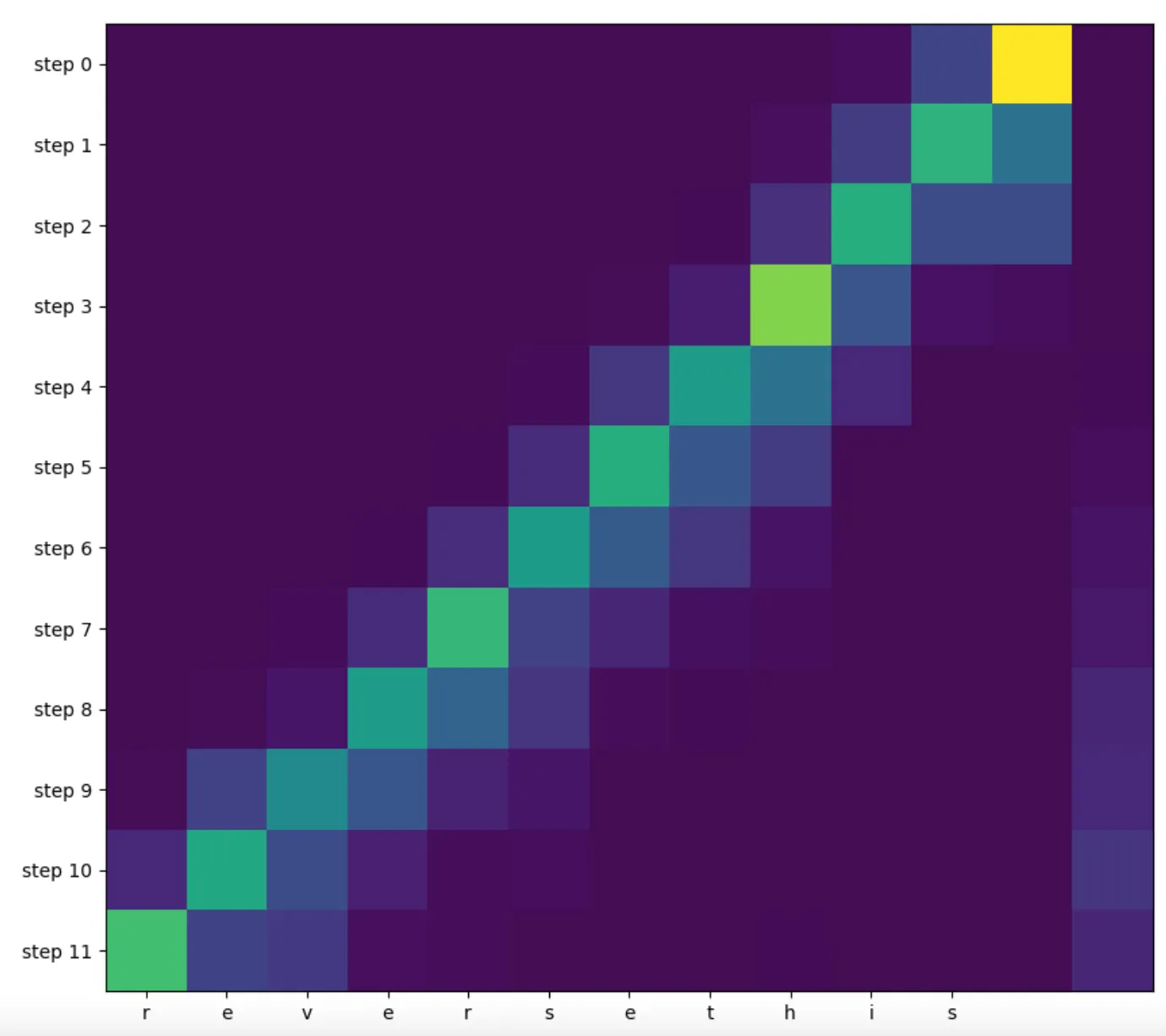
图片来自作者
我们可以清楚地看到,当我们将句子“reversethis”倒序时,模型是从右向左进行注意力处理的!(第0步实际上接收到的是句子开始的标记)。
结论就这样,你现在可以编写Transformer,并使用更大的数据集来进行机器翻译或创建你自己的BERT模型!
我希望这篇教程能让你注意到编写Transformer时的注意事项:填充和掩码可能是需要特别关注的部分(无意双关),因为它们将决定模型在推理时的表现。
在接下来的文章中,我们将介绍如何创建自己的 BERT 模型,以及如何使用基于 JAX 的高性能库 Equinox。
敬请期待 !
有用的链接(+) “详解Transformer”
(+) “从零开始的Transformers”
(+) “使用Transformer和Keras进行神经机器翻译”
(+) “插图详解Transformer”
(+) 阿姆斯特丹大学深度学习教程
(+) Pytorch的Transformer教程





