
 作者创建的图片。
作者创建的图片。
简介这篇文章最初发布于 https://vutr.substack.com。
我有一个虚拟的任务列表,里面包含了我想写的话题,而Apache Parquet已经在那里放了很久了。
这周,我把 Parquet 从待办事项中拿出来,拂去厚厚的灰尘,并承诺深入研究这种文件格式。
你正在阅读的文章是我学习了这种文件格式结构及其读写协议后的全部总结。
概览当处理大型数据集时,数据的结构会决定它能够被存储和访问的效率。
传统的行存储格式将数据以记录的形式依次存储,很像一个数据库表。
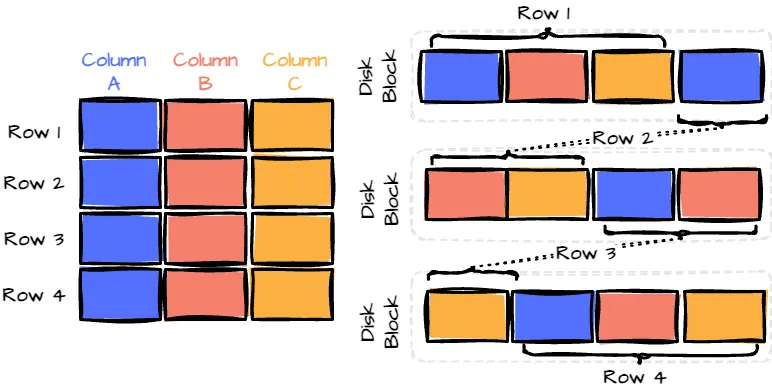
行式格式。由作者创建的图像。
这种格式直观且在频繁访问整个记录时表现良好。然而,在进行数据分析时,通常只需要从大型数据集中获取特定列,这时它可能会变得效率低下。
例如,想象一个有50列和数百万行的表。如果你只对分析其中的3列感兴趣,采用行级格式仍然需要为每一行读取所有的50列。
列式格式通过将数据按列而不是按行存储来解决此问题。这意味着当你需要特定的列时,你只需读取所需的列数据,从而显著减少了扫描的数据量。
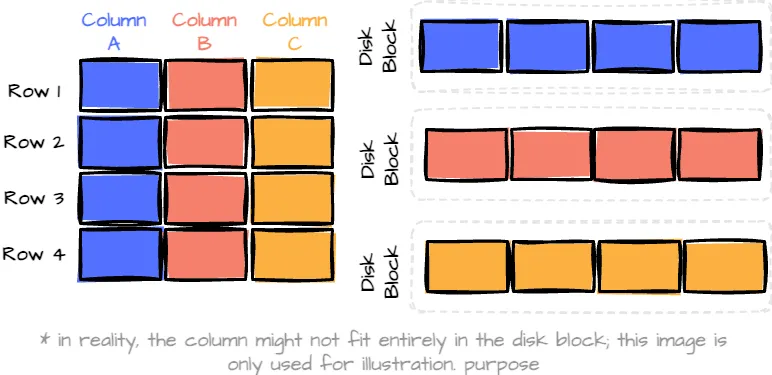
列式格式。由作者创建的图像。
然而,仅仅以列式格式存储数据有一些缺点。记录的写入或更新操作需要触碰多个列段,导致大量的I/O操作。这会显著降低写入性能,特别是在处理大规模数据集时。
此外,当查询涉及多个列时,数据库系统必须从单独的列中重新构建记录。这种重建的成本随着查询涉及的列数的增加而增加。
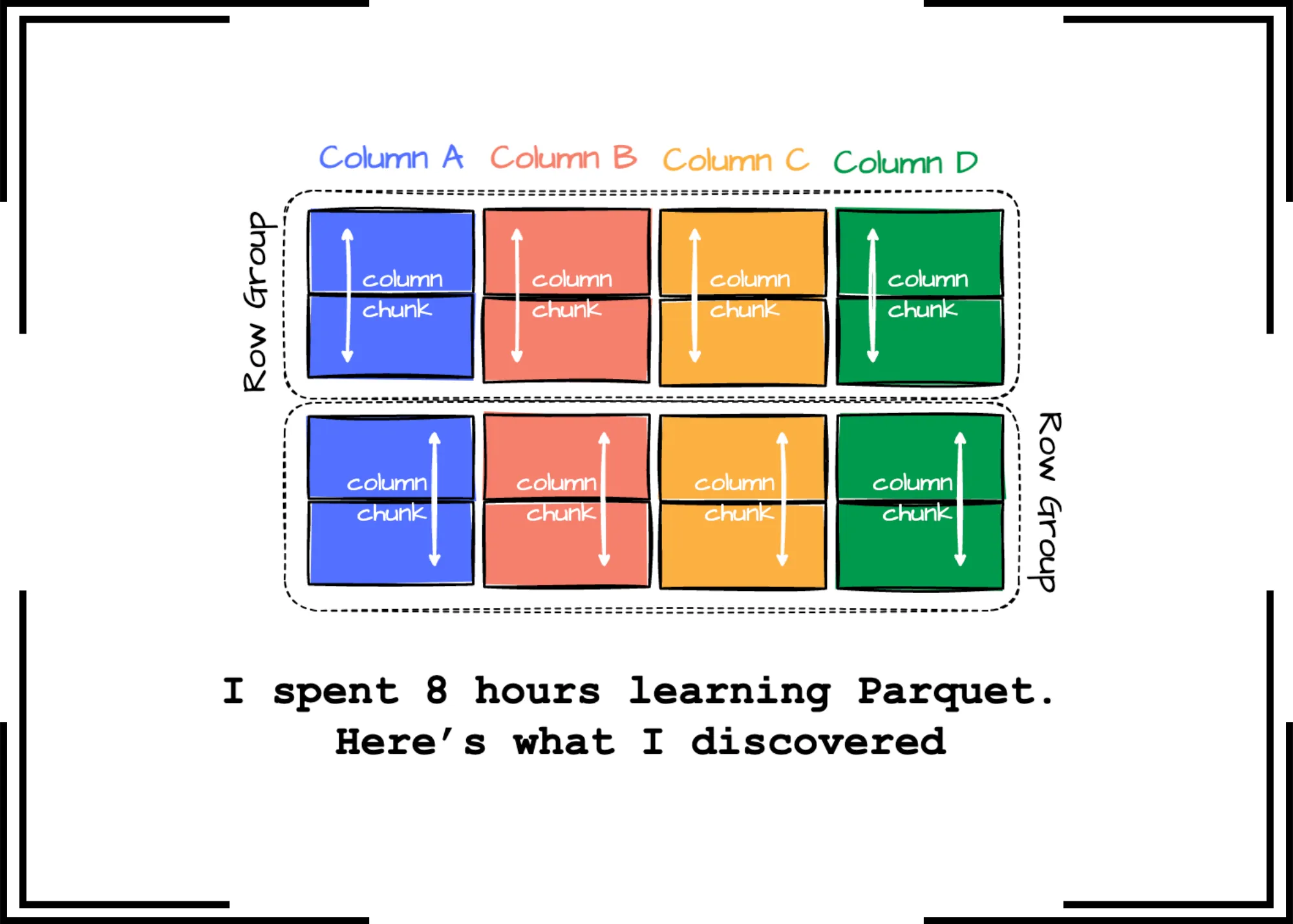
这种混合格式结合了两种格式的优点。
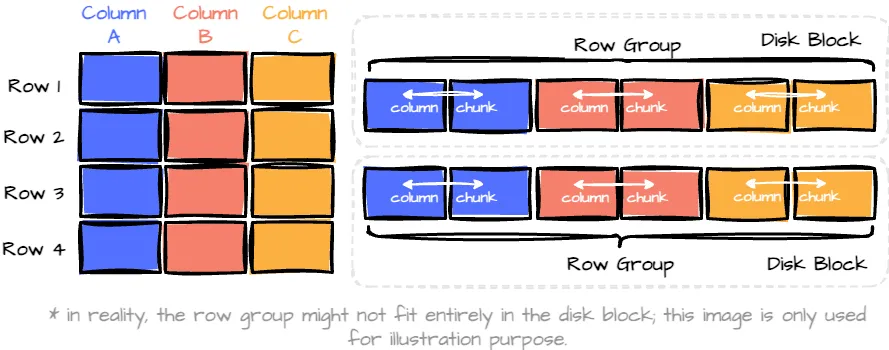
混合格式。作者创建的图片。
该格式将数据分组成“行组”,每个行组包含一部分行。(水平分区。)在每个行组内,每一列的数据称为“列块。”(垂直分区)
在行组中,这些数据块保证在磁盘上连续存储。
在过去,我认为Parquet纯粹是一种列式格式,我相信你们中的许多人可能也有同样的想法。更准确地说,Parquet在幕后以一种混合格式组织数据。
我们将在这部分内容中深入探讨Parquet文件结构。
内部结构术语和元数据
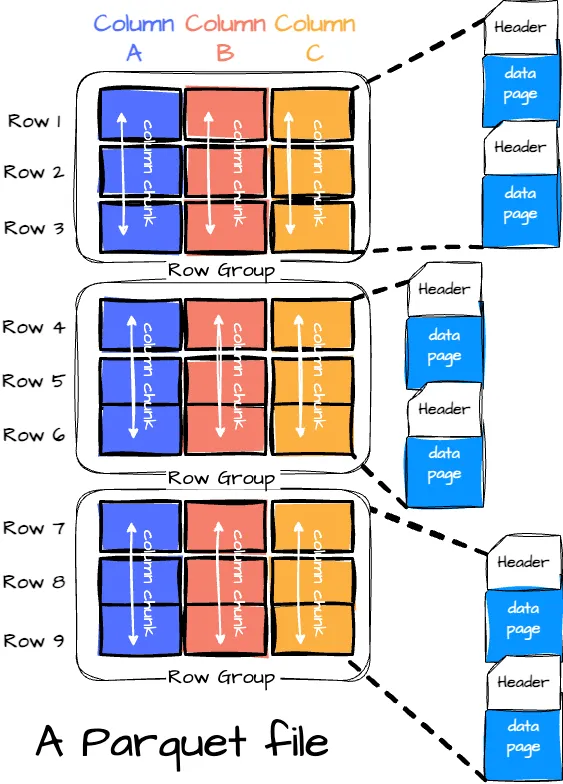
作者创建的图像。
一个 Parquet 文件由以下部分组成:
- 行组: 每个行组包含数据集的一部分行。数据在每个行组内的列中组织,每一列的数据存储在一个 列块 中。
- 列块: 列块是行组中特定列的数据。
- 页: 列块进一步划分为页。页是 Parquet 中最小的数据单位。页有几种类型,包括数据页(包含实际数据)、字典页(包含字典编码的值)和索引页(用于更快的数据查找)。
Parquet 是一种自描述文件格式,包含了消费该文件的应用程序所需的所有信息。这使得软件能够高效地理解和处理文件,而无需额外的外部信息。因此,元数据是 Parquet 的关键部分:
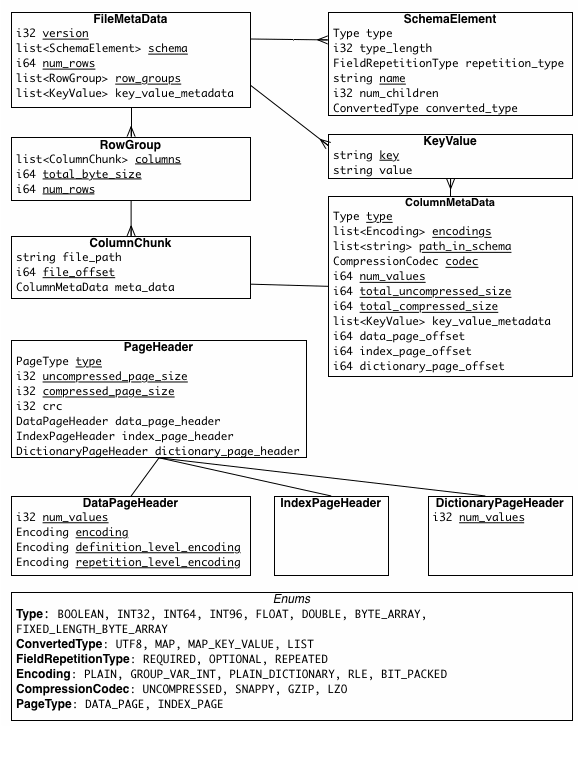
Parquet 元数据模型。来源
- 魔数 : 魔数是一组特定的字节 (
PAR1),位于文件的开头和结尾。该数字用于验证文件是否为有效的Parquet文件。 - FileMetadata: Parquet将FileMetadata存储在文件的尾部。此元数据提供了行数、数据模式和行组元数据等信息。每个行组元数据包含有关其列块(ColumnMetadata)的信息,例如编码和压缩方案、未压缩/压缩大小、页面偏移量、值的数量以及列块的最小/最大值。在导航Parquet文件时,应用程序可以使用此元数据来限制数据扫描;它可以根据过滤器修剪不必要的行组或仅读取所需的列。
- PageHeader: 页面头部元数据与页面数据一起存储,并包含有关值编码、定义编码和重复编码的信息。除了数据值外,Parquet还存储定义和重复级别以处理嵌套数据。应用程序使用页面头部来读取和解码数据。
谷歌的 Dremel(BigQuery 背后的查询引擎)启发了 Parquet 实现嵌套和重复字段存储的方法。在一篇于 2010 年发表的文章 中,谷歌详细介绍了其在分析工作负载中高效处理嵌套和重复字段的方法,使用定义级别(用于嵌套字段)和重复级别(用于类似数组的字段)。我七个月前写了一篇文章介绍这种方法,你可以在这里阅读:
你可能不知道:BigQuery 如何存储半结构化数据?事实:Apache Parquet 也实现了这种方法。medium.com为了更好地理解Parquet文件背后的数据存储方式,我编写了一个Python程序,将一个Pandas数据框写入Parquet文件,并使用fastparquet读取该文件。我尽量保持过程简单,以便快速理解这个概念。因此,在文件写入过程中没有使用任何配置,如多线程,只是将一个包含10行的数据框写入了一个单独的Parquet文件。读取过程也很简单,除了文件路径外,没有使用任何参数。
在接下来的部分,我将阐述我对 Parquet 写入和读取数据过程的理解。
Parquet 格式的数据是如何写入的?我将使用“Parquet Writer”这一术语来指代负责以Parquet格式写入数据的过程。
以下是将数据集写入 Parquet 文件的概述过程:
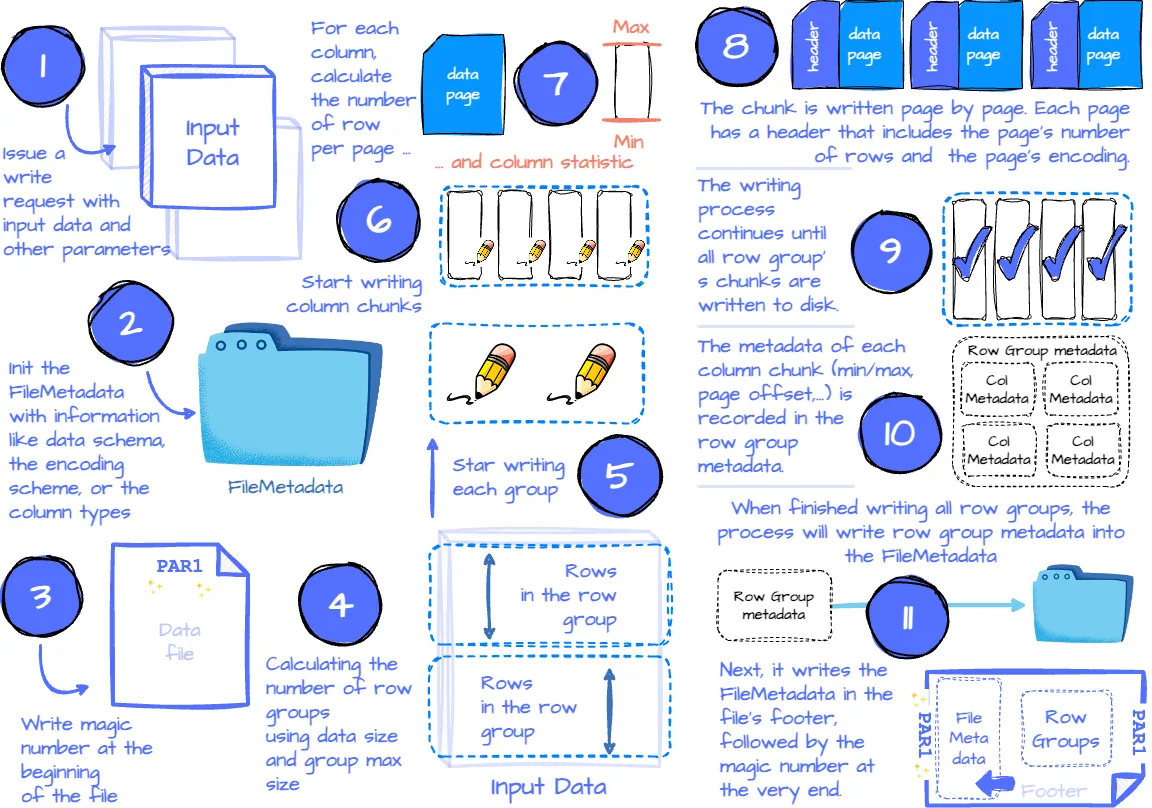
Parquet 写入过程。作者创建的图片。
- 应用程序发出一个书面请求,包含参数,如数据、每列的压缩方案(可选)、每列的编码方案(可选)、文件方案(写入一个文件或多个文件)、自定义元数据等。
- Parquet Writer 首先收集信息,如数据模式、空值出现情况、编码方案和所有列类型,这些信息记录在
FileMetadata中。 - 接下来,Writer 在文件开头写入魔数。
- 然后,根据行组的最大大小(可配置)和数据大小计算行组的数量。这一步还确定了哪些数据子集属于哪个行组。之后,开始每个行组的物理写入过程。
- 对于每个行组,它遍历列列表来写入该行组的每个列块。此步骤将使用用户指定的压缩方案(默认为无压缩)来压缩数据。
- 列块写入过程开始于使用最大页面大小和块大小计算每页的行数。接下来,它将尝试计算列的最小/最大统计信息。(此计算仅适用于可测量类型的列,如整数或浮点数。)
- 然后,列块按顺序一页一页地写入。每页有一个包含该页行数、数据编码、重复和定义的页头。如果该列使用字典编码,则字典页在数据页之前存储。字典页也有相关的页头。
- 在写入列块的所有页面后,Parquet Writer 为该块构建列块元数据,其中包括列的最小/最大值(如果有)、未压缩大小、压缩大小、第一个数据页偏移量、第一个字典页偏移量等信息。
- 列块写入过程继续,直到行组中的所有列都写入磁盘,确保列块连续存储。每个列块的元数据记录在行组元数据中。
- 在写入所有行组后,所有行组的元数据记录在
FileMetadata中。 FileMetadata写入文件尾部。- 整个过程最后在文件末尾写入魔数。
我将使用“Parquet Reader”这一术语来指代负责读取Parquet数据文件的过程。
以下是读取 Parquet 文件的概述过程:
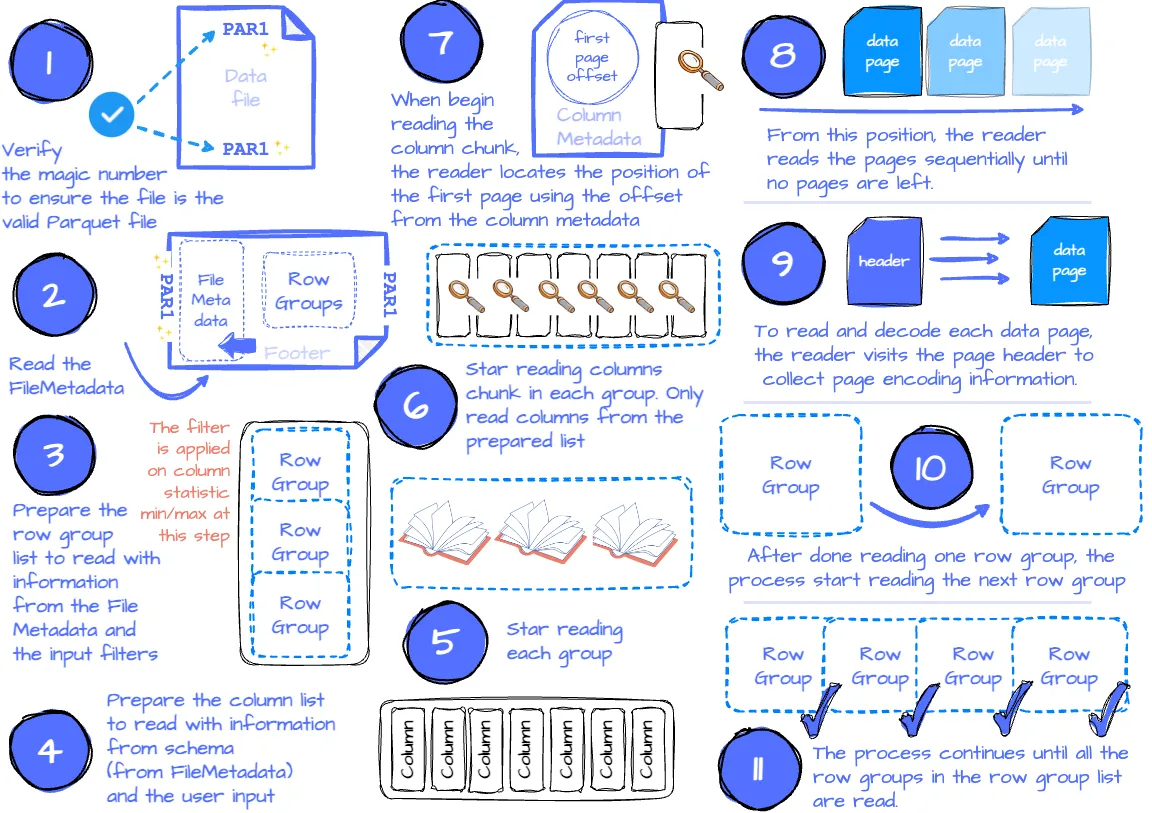
Parquet 阅读过程。由作者创建的图像。
- 应用程序发出带有参数的读取请求,例如输入文件、限制读取行组数量的过滤器、所需的列集等。
- 如果应用程序需要验证是否正在读取有效的Parquet文件,读取器将通过查找文件开头和结尾的前四个字节来检查是否存在魔数。
- 然后尝试从文件尾部读取FileMetadata。它提取文件模式和行组元数据等信息,供后续使用。
- 如果指定了过滤器,它们将限制扫描的行组数量。这是因为行组包含所有列块的元数据,其中包括每个可测量列块的最小/最大统计信息;读取器只需遍历每个行组并将其统计信息与每个块的过滤器进行比较。如果满足过滤器条件,该行组将添加到行组列表中,该列表稍后用于读取。如果没有过滤器,列表将包含所有行组。
- 接下来,读取器定义列列表。如果应用程序指定了要读取的列子集,列表中只包含这些列。否则,列表将包含所有列。
- 接下来是读取行组。读取器将遍历行组列表并读取每个行组。
- 读取器将根据列列表为每个行组读取列块。它使用ColumnMetadata来读取块。
- 当第一次读取列块时,读取器使用列元数据中的第一个页面偏移量来定位第一个数据页面(如果使用字典编码,则为字典页面)的位置。从该位置开始,读取器按顺序读取页面,直到没有剩余页面。为了知道是否有剩余数据,读取器跟踪已读取的行数,并将其与块的总行数进行比较。如果这两个数字相等,则读取器已读取完所有块数据。
- 为了读取和解码每个数据页面,读取器访问页面头以收集值编码、定义级别和重复级别编码等信息。
- 在读取完所有行组的列块后,读取器将读取下一个行组。
- 该过程将继续,直到读取完行组列表中的所有行组。
多文件我一路上的观察
应用程序可以指定写入过程,将数据集输出到多个文件中,甚至可以指定分区标准,以便将 Parquet 输出文件组织到 Hive 分区文件夹中。例如,所有 2024-08-01 的数据存储在文件夹 date=2024-08-01 中,所有 2024-08-02 的数据存储在文件夹 date=2024-08-02 中。
因为 Parquet 文件可以存储在多个文件中,应用程序可以使用多线程同时读取它们。
此外,单个Parquet文件在水平(行组)和垂直(列块)上进行分区,这允许应用程序在行组或列级别上并行读取数据,从而使用多线程。
编码Parquet 中的列块数据在行组中紧密存储在一起。这有助于 Parquet 更高效地编码数据,因为同一列中的数据往往更加同质和重复。
Parquet 利用字典编码和运行长度编码(RLE)等技术显著减少存储空间。经过字典编码后,Parquet 进一步对数据进行运行长度编码。

作者创建的图像。
字典编码将重复的值替换为较短的唯一键,从而减少冗余并提高压缩率。据我所知,字典编码在 Parquet 中默认实现。如果数据满足预定义的条件(如不同值的数量),则会应用字典编码。
另一方面,RLE(运行长度编码)通过只存储一个值及其重复次数来压缩连续相同的值。这些方法通过减少需要扫描的数据量来最小化存储的数据量并优化读取性能。
OLAP工作负载使用统计信息过滤行组并仅选择所需读取的列,可以显著提升分析工作负载的性能。给定以下查询:

创建于 carbon.now.sh
使用以下 Parquet 布局,我们只需要读取行组 1 和 2,关注每个行组中的列 A 和 B,而不是读取所有列。
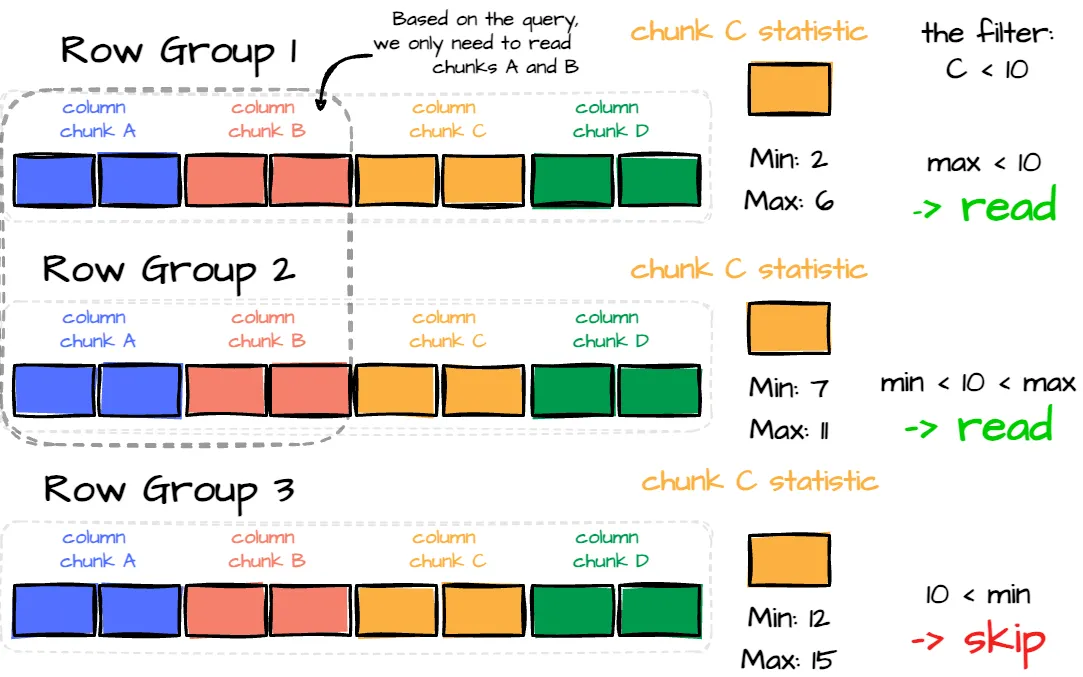
作者创建的图像。
结语以上是我对 Parquet 的所有了解。我计划在未来撰写更多与此文件格式相关的深入文章。所以敬请期待我的后续作品 ;)
顺便说一下,我对 Parquet 的了解有限,可能无法从更广泛的视角来看待这种格式。如果您觉得我遗漏了某些内容或想要进一步讨论,请在评论区留言或直接通过 LinkedIn、电子邮件 或 Twitter 联系我。
参考资料[1] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, Marios Skounakis,为缓存性能编织关系
[2]Parquet 官方文档
[3] Wes McKinney,使用多线程的Python中的并行Apache Parquet实现极致IO性能 (2017)
[4] Michael Berk,揭秘Parquet文件格式 (2022)





