
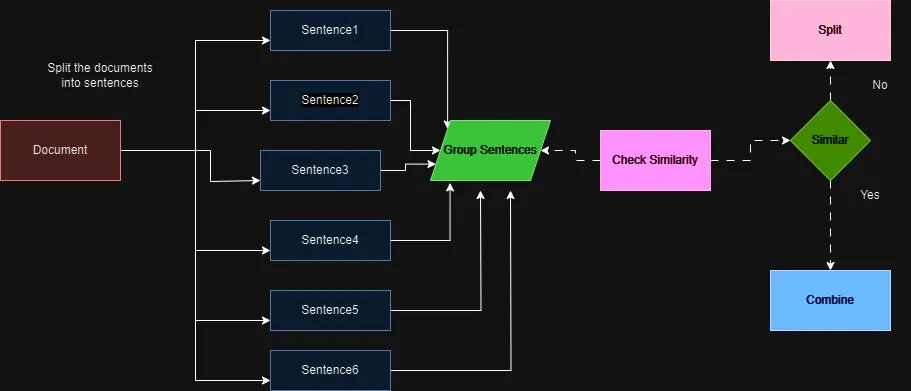
为了遵守大语言模型(LLM)的上下文窗口限制,我们通常将文本分成更小的部分,这称为分块。
什么是RAG?虽然大型语言模型(LLMs)能够生成既有意义又语法正确的文本,但这些LLMs存在一个称为“幻觉”的问题。在LLMs中,“幻觉”是指它们自信地生成错误答案,也就是说,它们以一种让我们相信其正确性的方式编造错误答案。自LLMs问世以来,这个问题一直是一个主要问题。这些幻觉导致了错误和不正确的答案。因此,引入了检索增强生成(RAG)来解决这个问题。
在RAG中,我们取一组文档或文档片段,并将这些文本文档编码为称为向量嵌入的数值表示,其中单个向量嵌入表示单个文档片段,并将其存储在一个称为向量存储的数据库中。用于将这些片段编码为嵌入的模型称为编码模型或双编码器。这些编码器是在大量数据上进行训练的,因此能够将文档片段编码为单个向量嵌入表示,从而变得非常强大。
检索很大程度上取决于片段在向量存储中是如何表现和存储的。对于任何给定的文本,找到合适的片段大小是一个非常困难的问题。
提高检索性能可以通过多种检索方法来实现。但也可以通过更优的分块策略来实现。
不同的分块方法:
- 固定大小分块
- 递归分块
- 文档特定分块
- 语义分块
- 代理分块
固定大小分块:这是最常见和最直接的分块方法:我们只需决定每个分块中的token数量,并可选择是否让分块之间有重叠。通常,我们希望分块之间保持一些重叠,以确保语义上下文不会在分块之间丢失。在大多数常见情况下,固定大小的分块将是最佳选择。与其它分块方法相比,固定大小的分块在计算上较为便宜且易于使用,因为它不需要使用任何NLP库。
递归分块:递归分块通过一组分隔符将输入文本分块,这种分块是分层和迭代进行的。如果初次尝试分割文本未能产生所需大小或结构的块,该方法会递归地在生成的块上使用不同的分隔符或标准进行调用,直到达到所需的块大小或结构。这意味着虽然块的大小不会完全相同,但它们仍然会“力求”保持相似的大小。这种方法利用了固定大小分块的优点并进行重叠。
文档特定分块: 它考虑了文档的结构。而不是使用固定数量的字符或递归过程,它创建与文档逻辑部分(如段落或子部分)对齐的块。通过这样做,它保持了作者对内容的组织,从而使文本保持连贯。这使得检索到的信息更加相关和有用,特别是对于具有明确定义部分的结构化文档。它可以处理诸如 Markdown、Html 等格式。
语义分块:语义分块考虑了文本内部的关系。它将文本划分为有意义、语义完整的块。这种方法确保在检索过程中信息的完整性,从而获得更准确和符合上下文的结果。与之前的分块策略相比,这种方法速度较慢。
代理块: 这里的假设是像人类处理文档那样来处理文档。
- 我们从文档的顶部开始,将第一部分视为一个块。
- 我们继续向下阅读文档,决定新的句子或信息是否应该与第一个块合并,或者是否应该开始一个新的块。
- 我们一直这样做,直到读完整个文档。
这种方法仍在测试中,由于处理多个LLM调用所需的时间和这些调用的成本,它还没有准备好用于大规模应用。目前公共库中还没有可用的实现。
在这里我们将试验语义分块和递归检索器。
方法步骤比较:- 加载文档
- 使用以下两种方法对文档进行分块:语义分块和递归检索。
- 使用RAGAS评估定性和定量的改进
语义分块涉及提取文档中每个句子的嵌入,比较所有句子之间的相似性,然后将嵌入最相似的句子分组在一起。
通过关注文本的意义和上下文,语义分块显著提升了检索的质量。当保持文本的语义完整性至关重要时,它是一个绝佳的选择。
这里的假设是我们可以使用单个句子的嵌入来创建更有意义的片段。基本思路如下:-
- 根据分隔符(.,?,!)将文档拆分成句子
- 根据位置索引每个句子。
- 分组:选择句子的两侧包含多少句子。在所选句子的两侧添加缓冲区句子。
- 计算句子组之间的距离。
- 基于相似性合并组,即保持相似的句子在一起。
- 拆分不相似的句子。
- Langchain : LangChain 是一个开源框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。它提供了一个标准接口来构建链,与许多其他工具的集成,并且提供了常见应用程序的端到端链。
- LLM : Groq 的 Language Processing Unit (LPU) 是一种前沿技术,旨在显著提升AI计算性能,特别是在大型语言模型(LLM)方面。Groq LPU 系统的主要目标是提供实时、低延迟的体验,并具有出色的推理性能。
- Embedding Model : FastEmbed 是一个轻量级、快速的 Python 库,用于生成嵌入。
- Evaluation: Ragas 提供了用于单独评估您 RAG 管道中每个组件的指标。
安装所需的依赖
!pip install -qU langchain_experimental langchain_openai langchain_community langchain ragas chromadb langchain-groq fastembed pypdf openai langchain==0.1.16
langchain-community==0.0.34
langchain-core==0.1.45
langchain-experimental==0.0.57
langchain-groq==0.1.2
langchain-openai==0.1.3
langchain-text-splitters==0.0.1
langcodes==3.3.0
langsmith==0.1.49
chromadb==0.4.24
ragas==0.1.7
fastembed==0.2.6下载数据
! wget "https://arxiv.org/pdf/1810.04805.pdf"处理PDF内容
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
#
loader = PyPDFLoader("1810.04805.pdf")
documents = loader.load()
#
print(len(documents))执行原生分块(RecursiveCharacterTextSplitting)
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
length_function=len,
is_separator_regex=False
)
#
naive_chunks = text_splitter.split_documents(documents)
for chunk in naive_chunks[10:15]:
print(chunk.page_content+ "\n")
###########################RESPONSE###############################
BERT BERT
E[CLS] E1 E[SEP] ... ENE1’... EM’
C
T1
T[SEP] ...
TN
T1’...
TM’
[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokM
Question Paragraph Start/End Span
BERT
E[CLS] E1 E[SEP] ... ENE1’... EM’
C
T1
T[SEP] ...
TN
T1’...
TM’
[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokM
Masked Sentence A Masked Sentence B
Pre-training Fine-Tuning NSP Mask LM Mask LM
Unlabeled Sentence A and B Pair SQuAD
Question Answer Pair NER MNLI Figure 1: 整体预训练和微调过程。除了输出层外,预训练和微调使用相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,所有参数都会被微调。[CLS] 是每个输入示例前添加的特殊符号,而 [SEP] 是特殊分隔符(例如,用于分隔问题/答案)。
ing and auto-encoder objectives have been used
for pre-training such models (Howard and Ruder,
2018; Radford et al., 2018; Dai and Le, 2015).
2.3 监督数据的迁移学习
还有一些工作表明,从具有大规模数据集的监督任务中进行有效迁移,例如自然语言推理(Conneau et al.,
2017)和机器翻译(McCann et al.,
2017)。计算机视觉研究也展示了从大规模预训练模型中进行迁移学习的重要性,其中一种有效的方法是使用ImageNet(Deng et al., 2009; Yosinski et al., 2014)进行预训练模型的微调。
3 BERT
在本节中,我们介绍BERT及其详细实现。我们的框架分为两个步骤:预训练和微调。在预训练过程中,模型在未标记的数据上进行训练,涉及不同的预训练任务。在微调过程中,BERT模型首先使用预训练参数进行初始化,并使用下游任务的标记数据对所有参数进行微调。每个下游任务都有独立的微调模型,尽管它们都是使用相同的预训练参数进行初始化的。图1中的问答示例将作为本节的示例。
BERT的一个显著特点是其在不同任务中的统一架构。预训练架构和最终的下游架构之间的差异很小。
模型架构 BERT的模型架构是一个基于Vaswani等人(2017)描述的原始实现的多层双向Transformer编码器,并在tensor2tensor库中发布。1由于Transformer的使用已经变得普遍,我们的实现几乎与原始实现相同,因此我们将省略对模型架构的详尽背景描述,并将读者引导至Vaswani等人(2017)以及诸如“The Annotated Transformer”2等优秀指南。
在这项工作中,我们用L表示层数(即,Transformer块的数量),用H表示隐藏大小,用A表示自注意力头的数量。3我们主要报告两种模型大小的结果:
BERT BASE(L=12, H=768, A=12, 总参数=110M)和 BERT LARGE(L=24, H=1024, A=16, 总参数=340M)。
为了比较目的,BERT BASE 选择了与OpenAI GPT相同的模型大小。
关键的是,BERT Transformer 使用双向自注意力,而GPT Transformer 使用受限自注意力,其中每个标记只能关注其左侧的上下文。4
1https://github.com/tensorflow/tensor2tensor
2http://nlp.seas.harvard.edu/2018/04/03/attention.html
3在所有情况下,我们将前馈/过滤器大小设置为4H,即对于H= 768为3072,对于H= 1024为4096。
4我们注意到,在文献中,双向Transformer的输入/输出表示
输入/输出表示 为了使BERT能够处理各种下游任务,我们的输入表示能够明确地表示单个句子和句子对(例如,⟨问题,答案⟩)在一个标记序列中。
在这项工作中,“句子”可以是任意连续的文本片段,而不仅仅是实际的句子。一个“序列”是指输入给BERT的标记序列,它可能是一个句子或两个句子的组合。
我们使用WordPiece嵌入(Wu et al.,
2016)和一个30,000个标记的词汇表。每个序列的第一个标记始终是一个特殊的分类标记( [CLS] )。该标记对应的最终隐藏状态被用作分类任务的序列表示。句子对被组合成一个序列。我们通过两种方式区分句子。首先,我们用一个特殊的标记( [SEP] )将它们分开。其次,我们添加了一个学习的嵌入实例化嵌入模型
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")设置 LLM 的 API 密钥
from google.colab import userdata
from groq import Groq
from langchain_groq import ChatGroq
#
groq_api_key = userdata.get("GROQ_API_KEY")执行语义分块
今天我们将以 percentile 阈值为例进行说明——但在语义分块中,你可以使用三种不同的策略:
- `分位数 `(默认)——在此方法中,将计算所有句子之间的差异,然后将任何大于X分位数的差异进行分割。
- `标准差 ` — 在这种方法中,任何大于X个标准差的差异都会被分割。
- `四分位距` — 在这种方法中,使用四分位距来分割块。
注意:此方法目前处于实验阶段,并未达到稳定最终版本——请期待未来几个月的更新和改进
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
semantic_chunker = SemanticChunker(embed_model, breakpoint_threshold_type="percentile")
#
semantic_chunks = semantic_chunker.create_documents([d.page_content for d in documents])
#
for semantic_chunk in semantic_chunks:
if "预训练任务的影响" in semantic_chunk.page_content:
print(semantic_chunk.page_content)
print(len(semantic_chunk.page_content))
#############################响应###############################
Dev Set
任务 MNLI-m QNLI MRPC SST-2 SQuAD
(Acc) (Acc) (Acc) (Acc) (F1)
BERT BASE 84.4 88.4 86.7 92.7 88.5
无NSP 83.9 84.9 86.5 92.6 87.9
LTR & 无NSP 82.1 84.3 77.5 92.1 77.8
+ BiLSTM 82.1 84.1 75.7 91.6 84.9
表5:使用BERT BASE架构进行预训练任务的消融研究。“无NSP”是在没有“下一句预测”任务的情况下进行训练。“LTR & 无NSP”是在没有“下一句预测”的情况下作为左到右语言模型进行训练,类似于OpenAI GPT。“+ BiLSTM”在“LTR + 无NSP”模型的微调过程中添加了一个随机初始化的BiLSTM。消融研究可以在附录C.5.1中找到。5.1 预训练任务的影响
我们通过使用与BERT BASE完全相同的预训练数据、微调方案和超参数来评估两个预训练目标,展示了BERT的双向深度的重要性:
无NSP:一个双向模型,使用“掩码语言模型”(MLM)进行训练,但没有“下一句预测”(NSP)任务。LTR & 无NSP:一个仅使用标准左到右(LTR)语言模型进行训练的左上下文模型。
实例化向量存储
from langchain_community.vectorstores import Chroma
semantic_chunk_vectorstore = Chroma.from_documents(semantic_chunks, embedding=embed_model)我们将“限制”我们的语义检索器为 k = 1,以展示语义分块策略的强大之处,同时保持语义检索和简单检索的上下文中的 token 数量相似。
实例化检索步骤
semantic_chunk_retriever = semantic_chunk_vectorstore.as_retriever(search_kwargs={"k" : 1})
semantic_chunk_retriever.invoke("描述基于BERT的特征方法?")
########################响应###################################
[Document(page_content='论文的右侧部分展示了\nDev集的结果。对于基于特征的方法,\n我们将BERT的最后4层进行拼接作为\n特征,这在第5.3节中被证明是最优的方法。\n从表中可以看出,微调对不同的掩码策略\n具有惊人的鲁棒性。然而,如预期的那样,\n仅使用MASK策略在应用基于特征的方法\n进行NER时存在问题。有趣的是,仅使用\nRND策略的表现比我们的策略差得多。')]实例化增强步骤(用于内容增强)
from langchain_core.prompts import ChatPromptTemplate
rag_template = """\
使用以下上下文来回答用户的查询。如果无法回答,请回复 '我不知道'。
用户的查询:
{question}
上下文:
{context}
"""
rag_prompt = ChatPromptTemplate.from_template(rag_template)实例化生成步骤
chat_model = ChatGroq(temperature=0,
model_name="mixtral-8x7b-32768",
api_key=userdata.get("GROQ_API_KEY"),) from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
semantic_rag_chain = (
{"context" : semantic_chunk_retriever, "question" : RunnablePassthrough()}
| rag_prompt
| chat_model
| StrOutputParser()
)问问题 1
semantic_rag_chain.invoke("描述基于特征的BERT方法?")
################ 回复 ###################################
如上下文所述,基于特征的BERT方法涉及将BERT用作特征提取器,用于下游的自然语言处理任务,具体来说是命名实体识别(NER)。
要在基于特征的方法中使用BERT,会将BERT的最后4层进行拼接,以作为任务的特征。这是在论文的5.3节中发现的最有效的方法。
上下文还提到,对BERT进行微调对不同的掩码策略具有惊人的鲁棒性。然而,当使用基于特征的方法进行NER时,仅使用掩码策略存在问题。此外,仅使用随机策略的表现远不如提议的方法。
总之,基于特征的BERT方法涉及将BERT的最后4层用作下游NLP任务的特征,并针对特定任务对这些特征进行微调。该方法对不同的掩码策略具有鲁棒性,但仅使用某些策略对NER来说存在问题。问问题 2
semantic_rag_chain.invoke("什么是SQuADv2.0?")
################ 回复 ###################################
SQuAD v2.0,或称SQuAD Two Point Zero,是斯坦福问答数据集(SQuAD)的一个版本,它扩展了SQuAD 1.1的问题定义,允许在提供的段落中不存在简短答案的可能性。这使得问题更加现实,因为并非所有问题都能在提供的文本中找到直接的答案。SQuAD 2.0任务通过将没有答案的问题视为具有起始和结束位置在[CLS]标记上的答案跨度,并将无答案跨度的得分与最佳非空答案跨度的得分进行比较,来简单地扩展了SQuAD 1.1的BERT模型。文档还提到,BERT集成,即使用不同预训练检查点和微调种子的7个不同系统的组合,在SQuAD 2.0中远远超过了所有现有系统的表现,即使排除了使用BERT作为其组件之一的条目。问问题3
semantic_rag_chain.invoke("什么是消融研究的目的?")
################ 回复 ###################################
消融研究用于理解机器学习模型的不同组件或设置对其性能的影响。在提供的上下文中,消融研究用于回答有关训练步骤的数量和掩码程序对BERT模型性能影响的问题。通过比较模型在不同条件下的性能,研究人员可以了解这些组件或设置的重要性以及它们如何对模型的整体性能做出贡献。 naive_chunk_vectorstore = Chroma.from_documents(naive_chunks, embedding=embed_model)
naive_chunk_retriever = naive_chunk_vectorstore.as_retriever(search_kwargs={"k" : 5})
naive_rag_chain = (
{"context" : naive_chunk_retriever, "question" : RunnablePassthrough()}
| rag_prompt
| chat_model
| StrOutputParser()
)注意:这里我们将使用 k = 5;这是为了“公平比较”这两种策略。
问问题1
naive_rag_chain.invoke("描述基于BERT的基于特征的方法?")
#############################响应##########################
基于BERT的基于特征的方法涉及从预训练的BERT模型中提取固定特征,而不是将所有参数在下游任务上进行联合微调的方法。基于特征的方法具有某些优势,例如适用于难以用Transformer编码器架构表示的任务,并通过预先计算训练数据的昂贵表示来提供主要的计算优势,然后在此表示上运行许多实验,使用更便宜的模型。在提供的上下文中,基于特征的方法与微调方法在CoNLL-2003命名实体识别(NER)任务上进行了比较,基于特征的方法使用了保持大小写一致的WordPiece模型,并包括数据提供的最大文档上下文。表7显示了这两种方法在NER任务上的性能。问问题 2
naive_rag_chain.invoke("什么是SQuADv2.0?")
#############################回答##########################
SQuAD v2.0,即斯坦福问答数据集版本2.0,是一系列问题/答案对的集合,它扩展了SQuAD v1.1的问题定义,允许在提供的段落中不存在短答案的可能性。这使得问题更加现实。SQuAD v2.0的BERT模型是在SQuAD v1.1模型的基础上扩展的,将没有答案的问题视为具有起始和结束位置都在[CLS]标记的答案跨度,并将起始和结束答案跨度位置的概率空间扩展到包括[CLS]标记的位置。在预测时,将无答案跨度的得分与最佳非空跨度的得分进行比较。问问题3
naive_rag_chain.invoke("什么是消融研究的目的?")
#############################回答##########################
消融研究用于评估机器学习模型中不同组件或设置的效果。在提供的上下文中,消融研究用于理解BERT模型的某些方面(如训练步骤的数量和掩码程序)对模型性能的影响。
例如,一项消融研究调查了训练步骤数量对BERT性能的影响。结果显示,与训练500k步相比,BERT BASE在MNLI上训练1M步时获得了更高的微调精度,表明更多的训练步骤有助于更好的性能。
另一项消融研究关注预训练期间的不同掩码程序。该研究将BERT的掩码语言模型(MLM)与从左到右的策略进行了比较。结果显示,掩码策略旨在减少预训练和微调之间的不匹配,因为[MASK]符号在微调阶段不会出现。该研究还报告了MNLI和命名实体识别(NER)任务的开发集结果,考虑了NER的微调和基于特征的方法。使用 RecursiveCharacterTextSplitter 拆分文档
synthetic_data_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
length_function=len,
is_separator_regex=False
)
#
synthetic_data_chunks = synthetic_data_splitter.create_documents([d.page_content for d in documents])
print(len(synthetic_data_chunks))创建以下数据集
- 问题 — 合成生成(grogq-mixtral-8x7b-32768)
- 上下文 — 上方创建的(合成数据块)
- 真实答案 — 合成生成(grogq-mixtral-8x7b-32768)
- 答案 — 由我们的语义RAG链生成
questions = []
ground_truths_semantic = []
contexts = []
answers = []
question_prompt = """\
你是一位老师,正在准备一份测试。请根据以下上下文创建一个问题。
上下文:
{context}
"""
question_prompt = ChatPromptTemplate.from_template(question_prompt)
ground_truth_prompt = """\
使用以下问题和上下文,仅根据提供的上下文回答问题。
问题:
{question}
上下文:
{context}
"""
ground_truth_prompt = ChatPromptTemplate.from_template(ground_truth_prompt)
question_chain = question_prompt | chat_model | StrOutputParser()
ground_truth_chain = ground_truth_prompt | chat_model | StrOutputParser()
for chunk in synthetic_data_chunks[10:20]:
questions.append(question_chain.invoke({"context" : chunk.page_content}))
contexts.append([chunk.page_content])
ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))
answers.append(semantic_rag_chain.invoke(questions[-1]))注意:为了实验目的,我们仅考虑了10个样本
将生成的内容格式化为HuggingFace Dataset格式
from datasets import load_dataset, Dataset
qagc_list = []
for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):
qagc_list.append({
"question" : question,
"answer" : answer,
"contexts" : context,
"ground_truth" : ground_truth
})
eval_dataset = Dataset.from_list(qagc_list)
eval_dataset
###########################RESPONSE###########################
Dataset({
features: ['question', 'answer', 'contexts', 'ground_truth'],
num_rows: 10
})实现RAGAS指标并评估我们创建的数据集。
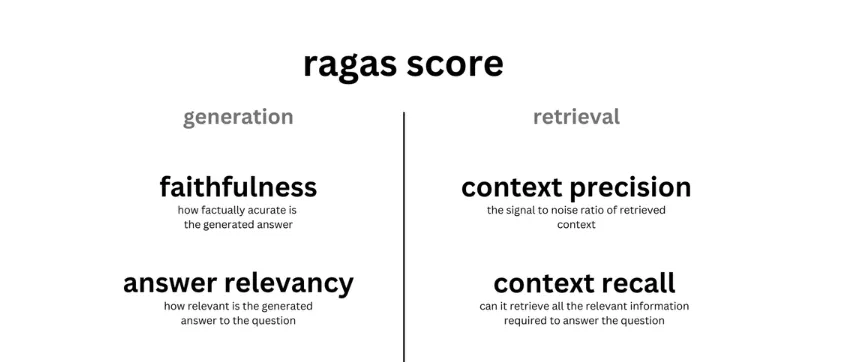
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
#
from ragas import evaluate
result = evaluate(
eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
llm=chat_model,
embeddings=embed_model,
raise_exceptions=False
)在这里我尝试使用Groq的开源LLM,但遇到了速率限制错误:
groq.RateLimitError: 错误代码: 429 - {'error': {'message': '模型 `mixtral-8x7b-32768` 在组织 `org_01htsyxttnebyt0av6tmfn1fy6` 上的每分钟令牌数(TPM)达到速率限制: 限制为 4500,已使用 3867,请求约 1679。请在 13.940333333 秒后重试。有关更多信息,请访问 https://console.groq.com/docs/rate-limits。', 'type': 'tokens', 'code': 'rate_limit_exceeded'}}
所以将 LLM 重定向为使用 OpenAI,而 OpenAI 是 RAGAS 框架默认使用的。
设置 OpenAI API 密钥
import os
from google.colab import userdata
import openai
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
openai.api_key = os.environ['OPENAI_API_KEY'] from ragas import evaluate
result = evaluate(
eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result
#########################RESPONSE##########################
{'context_precision': 1.0000, 'faithfulness': 0.8857, 'answer_relevancy': 0.9172, 'context_recall': 1.0000} # 将结果提取到数据框中
results_df = result.to_pandas()
results_df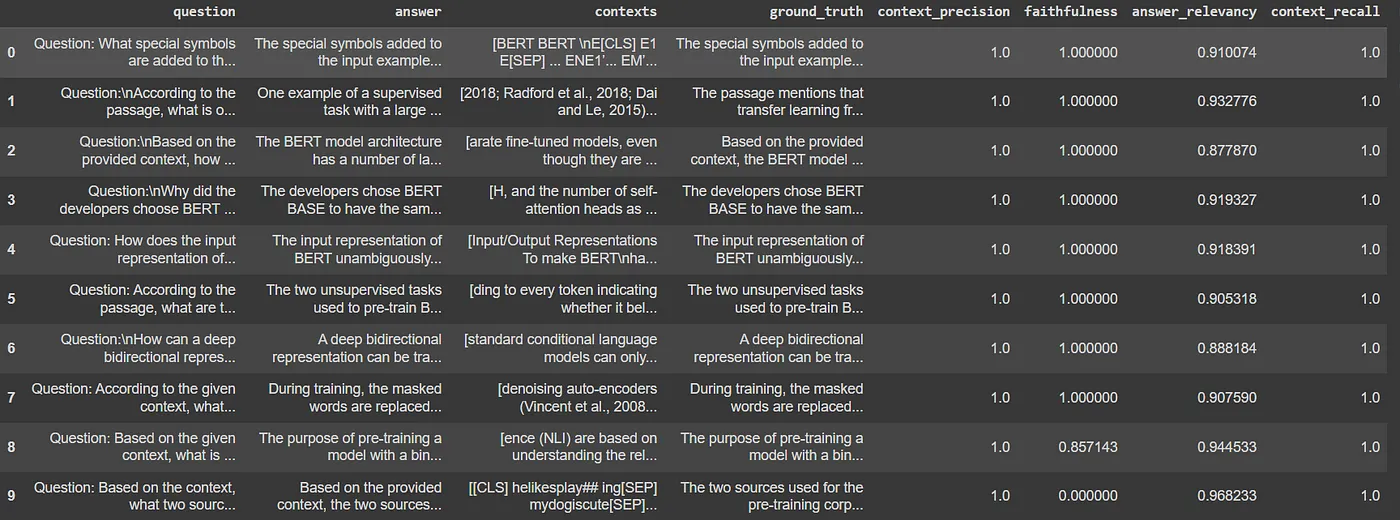
import tqdm
questions = []
ground_truths_semantic = []
contexts = []
answers = []
for chunk in tqdm.tqdm(synthetic_data_chunks[10:20]):
questions.append(question_chain.invoke({"context" : chunk.page_content}))
contexts.append([chunk.page_content])
ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))
answers.append(naive_rag_chain.invoke(questions[-1]))制定朴素的分块评估数据集
qagc_list = []
for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):
qagc_list.append({
"question" : question,
"answer" : answer,
"contexts" : context,
"ground_truth" : ground_truth
})
naive_eval_dataset = Dataset.from_list(qagc_list)
naive_eval_dataset
############################RESPONSE########################
Dataset({
特征: ['question', 'answer', 'contexts', 'ground_truth'],
行数: 10
})评估我们创建的数据集,使用RAGAS框架
naive_result = evaluate(
naive_eval_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
#
naive_result
############################RESPONSE#######################
{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000} naive_results_df = naive_result.to_pandas()
naive_results_df
###############################RESPONSE #######################
{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000}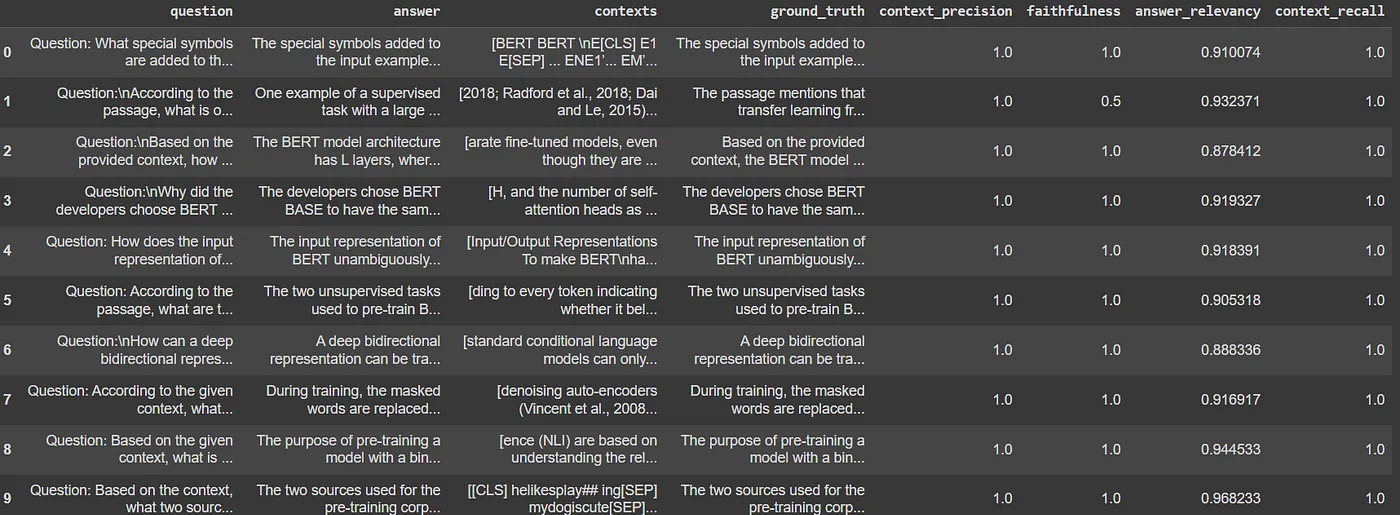
在这里我们可以看到,语义分块和朴素分块的结果几乎相同,除了朴素分块器在事实表示上得分较高,为0.95,而语义分块器的得分为0.88。
总之,语义分块能够将上下文相似的信息进行分组,从而创建独立且有意义的片段。这种方法通过提供聚焦的输入,增强了大规模语言模型的效率和效果,最终提升了它们理解和处理自然语言数据的能力。
参考资料: GroqCloud 体验全球最快的推理能力 console.groq.com 指标 | RagasSkip to content 直接跳到内容 在任何机器学习系统中,就像在LLM中的各个组件一样,性能的衡量…docs.ragas.io 语义分块 | 🦜️🔗 LangChain 根据语义相似性分割文本。python.langchain.com




