
介绍
本文将介绍如何编写一个只有200行的Python脚本,为两张肖像照上人物的“换脸”。
这个过程可分为四步:
检测面部标记。
旋转、缩放和转换第二张图像,使之与第一张图像相适应。
调整第二张图像的色彩平衡,使之与第一个相匹配。
把第二张图像的特性混合在第一张图像中。
完整的源代码可以从这里下载: https://github.com/matthewearl/faceswap/blob/master/faceswap.py

1.使用dlib提取面部标记
该脚本使用dlib的Python绑定来提取面部标记:

用Dlib实现了论文One Millisecond Face Alignment with an Ensemble of Regression Trees中的算法(http://www.csc.kth.se/~vahidk/papers/KazemiCVPR14.pdf,作者为Vahid Kazemi 和Josephine Sullivan) 。算法本身非常复杂,但dlib接口使用起来非常简单:
PREDICTOR_PATH = "/home/matt/dlib-18.16/shape_predictor_68_face_landmarks.dat"detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor(PREDICTOR_PATH)def get_landmarks(im): rects = detector(im, 1) if len(rects) > 1: raise TooManyFaces if len(rects) == 0: raise NoFaces return numpy.matrix([[p.x, p.y] for p in predictor(im, rects[0]).parts()])
get_landmarks()函数将一个图像转化成numpy数组,并返回一个68 x2元素矩阵,输入图像的每个特征点对应每行的一个x,y坐标。
特征提取器(predictor)要一个粗糙的边界框作为算法输入,由传统的能返回一个矩形列表的人脸检测器(detector)提供,其每个矩形列表在图像中对应一个脸。
为了构建特征提取器,预训练模型必不可少,相关模型可从dlib sourceforge库下载(http://sourceforge.net/projects/dclib/files/dlib/v18.10/shape_predictor_68_face_landmarks.dat.bz2)。
2.用普氏分析(Procrustes analysis)调整脸部
现在我们已经有了两个标记矩阵,每行有一组坐标对应一个特定的面部特征(如第30行给出的鼻子的坐标)。我们现在要搞清楚如何旋转、翻译和规模化第一个向量,使它们尽可能适合第二个向量的点。想法是,可以用相同的变换在第一个图像上覆盖第二个图像。
把它们更数学化,寻找T,s和R,令下面这个表达式的结果最小:
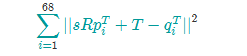
R是个2 x2正交矩阵,s是标量,T是二维向量,pi和qi是上面标记矩阵的行。
事实证明,这类问题可以用“常规普氏分析法” (Ordinary Procrustes Analysis) 解决:
def transformation_from_points(points1, points2): points1 = points1.astype(numpy.float64) points2 = points2.astype(numpy.float64) c1 = numpy.mean(points1, axis=0) c2 = numpy.mean(points2, axis=0) points1 -= c1 points2 -= c2 s1 = numpy.std(points1) s2 = numpy.std(points2) points1 /= s1 points2 /= s2 U, S, Vt = numpy.linalg.svd(points1.T * points2) R = (U * Vt).T return numpy.vstack([numpy.hstack(((s2 / s1) * R, c2.T - (s2 / s1) * R * c1.T)), numpy.matrix([0., 0., 1.])])
代码分别实现了下面几步:
将输入矩阵转换为浮点数。这是之后步骤的必要条件。
每一个点集减去它的矩心。一旦为这两个新的点集找到了一个最佳的缩放和旋转方法,这两个矩心c1和c2就可以用来找到完整的解决方案。
同样,每一个点集除以它的标准偏差。这消除了问题的组件缩放偏差。
使用Singular Value Decomposition计算旋转部分。可以在维基百科上看到关于解决正交普氏问题的细节(https://en.wikipedia.org/wiki/Orthogonal_Procrustes_problem)。
利用仿射变换矩阵(https://en.wikipedia.org/wiki/Transformation_matrix#Affine_transformations)返回完整的转化。
之后,结果可以插入OpenCV的cv2.warpAffine函数,将图像二映射到图像一:
def warp_im(im, M, dshape): output_im = numpy.zeros(dshape, dtype=im.dtype) cv2.warpAffine(im, M[:2], (dshape[1], dshape[0]), dst=output_im, borderMode=cv2.BORDER_TRANSPARENT, flags=cv2.WARP_INVERSE_MAP) return output_im
图像对齐结果如下:

3.校正第二张图像的颜色
如果我们试图直接覆盖面部特征,很快就会看到一个问题:

两幅图像之间不同的肤色和光线造成了覆盖区域的边缘不连续。我们试着修正:
COLOUR_CORRECT_BLUR_FRAC = 0.6LEFT_EYE_POINTS = list(range(42, 48)) RIGHT_EYE_POINTS = list(range(36, 42))def correct_colours(im1, im2, landmarks1): blur_amount = COLOUR_CORRECT_BLUR_FRAC * numpy.linalg.norm( numpy.mean(landmarks1[LEFT_EYE_POINTS], axis=0) - numpy.mean(landmarks1[RIGHT_EYE_POINTS], axis=0)) blur_amount = int(blur_amount) if blur_amount % 2 == 0: blur_amount += 1 im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount), 0) im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount), 0) # Avoid divide-by-zero errors. im2_blur += 128 * (im2_blur <= 1.0) return (im2.astype(numpy.float64) * im1_blur.astype(numpy.float64) / im2_blur.astype(numpy.float64))
结果是这样:

此函数试图改变图像2的颜色来匹配图像1。它通过用im2除以im2的高斯模糊,然后乘以im1的高斯模糊。这里的想法是用RGB缩放校色,但是不是用所有图像的整体常数比例因子,每个像素都有自己的局部比例因子。
用这种方法两图像之间光线的差异只能在某种程度上被修正。例如,如果图像1是从一边照亮,但图像2是均匀照明的,色彩校正后图像2也会出现未照亮边暗一些的现象。
也就是说,这是一个相当粗糙的办法,而且解决问题的关键是一个适当的高斯内核大小。如果太小,第一个图像的面部特征将显示在第二个图像中。过大,内核之外区域像素被覆盖,并发生变色。这里的内核用了一个0.6 *的瞳孔距离。
4.把第二张图像的特性混合在第一张图像中
用一个遮罩来选择图像2和图像1的哪些部分应该是最终显示的图像:

值为1(白色)的地方为图像2应该显示出的区域,值为0(黑色)的地方为图像1应该显示出的区域。值在0和1之间为图像1和图像2的混合区域。
这是生成上面那张图的代码:
LEFT_EYE_POINTS = list(range(42, 48)) RIGHT_EYE_POINTS = list(range(36, 42)) LEFT_BROW_POINTS = list(range(22, 27)) RIGHT_BROW_POINTS = list(range(17, 22)) NOSE_POINTS = list(range(27, 35)) MOUTH_POINTS = list(range(48, 61)) OVERLAY_POINTS = [ LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS, NOSE_POINTS + MOUTH_POINTS, ] FEATHER_AMOUNT = 11def draw_convex_hull(im, points, color): points = cv2.convexHull(points) cv2.fillConvexPoly(im, points, color=color)def get_face_mask(im, landmarks): im = numpy.zeros(im.shape[:2], dtype=numpy.float64) for group in OVERLAY_POINTS: draw_convex_hull(im, landmarks[group], color=1) im = numpy.array([im, im, im]).transpose((1, 2, 0)) im = (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0) > 0) * 1.0 im = cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0) return im mask = get_face_mask(im2, landmarks2) warped_mask = warp_im(mask, M, im1.shape) combined_mask = numpy.max([get_face_mask(im1, landmarks1), warped_mask], axis=0)
我们把上述代码分解:
get_face_mask()的定义是为一张图像和一个标记矩阵生成一个遮罩,它画出了两个白色的凸多边形:一个是眼睛周围的区域,一个是鼻子和嘴部周围的区域。之后它由11个像素向遮罩的边缘外部羽化扩展,可以帮助隐藏任何不连续的区域。
这样一个遮罩同时为这两个图像生成,使用与步骤2中相同的转换,可以使图像2的遮罩转化为图像1的坐标空间。
之后,通过一个element-wise最大值,这两个遮罩结合成一个。结合这两个遮罩是为了确保图像1被掩盖,而显现出图像2的特性。
最后,应用遮罩,给出最终的图像:
output_im = im1 * (1.0 - combined_mask) + warped_corrected_im2 * combined_mask






