
大家好,我是Python进阶者。
一、前言
前几天在Python钻石交流群【梦】问了一个Python网络爬虫的问题,这个网站不知道使用了什么反爬手段,都获取不到页面数据。原来的那篇文章竟然爆文了,突破了1.5w的阅读量,欢迎大家围观。
不过这里粉丝的需求有点奇怪,他不需要JS加载后的数据页面,而是需要JS的源网页。昨天在群里又讨论起这个问题,这次一起来看看这个问题。
二、实现过程
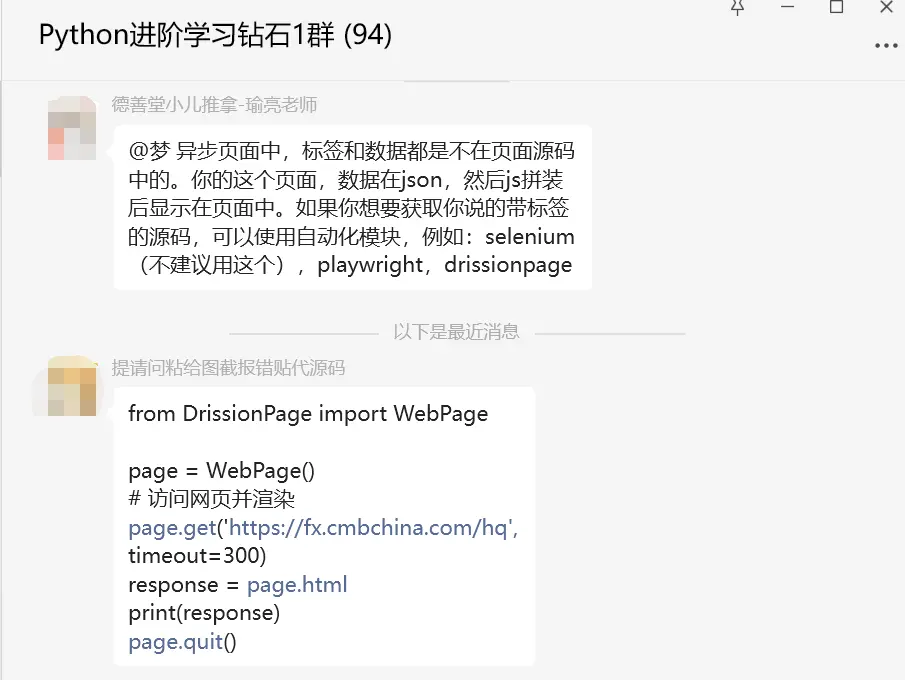
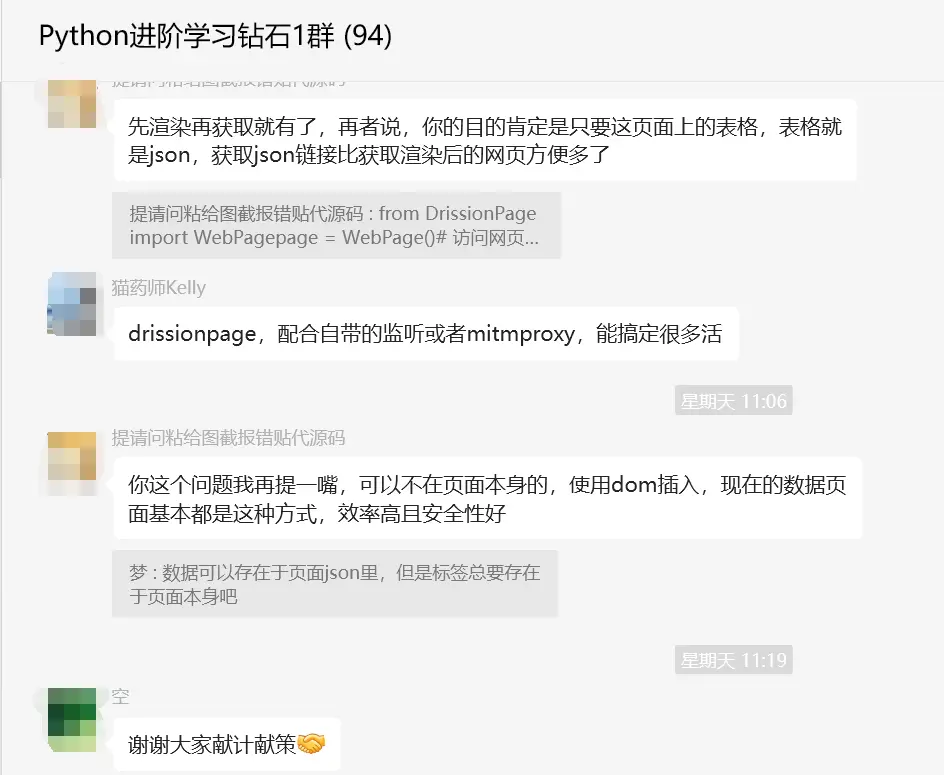
这里【瑜亮老师】指出异步页面中,标签和数据都是不在页面源码中的。你的这个页面,数据在json,然后js拼装后显示在页面中。如果你想要获取你说的带标签的源码,可以使用自动化模块,例如:selenium(不建议用这个),playwright,drissionpage。
后来【提请问粘给图截报错贴代源码】给出了具体的源码:
from DrissionPage import WebPage
page = WebPage()
# 访问网页并渲染
page.get('https://fx.cmbchina.com/hq', timeout=300)
response = page.html
print(response)
page.quit()
打开network,查看这个网页的渲染方式,你就知道这个网页一开始是没有内容的,全靠js在渲染。
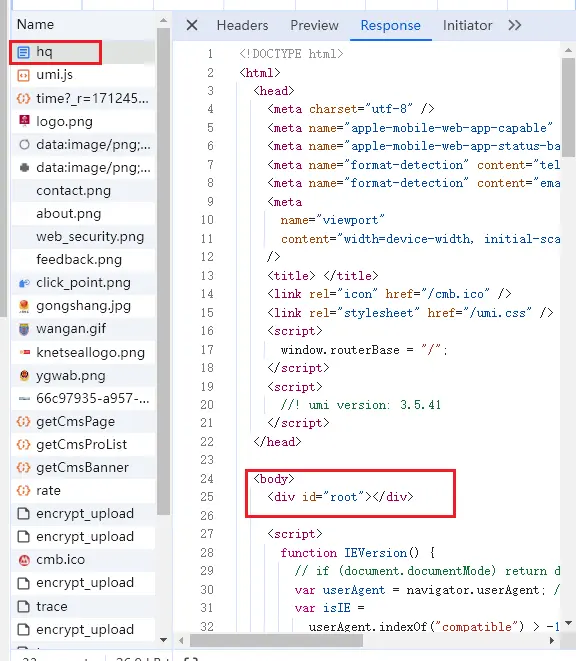
你直接访问这个链接就是没有内容。
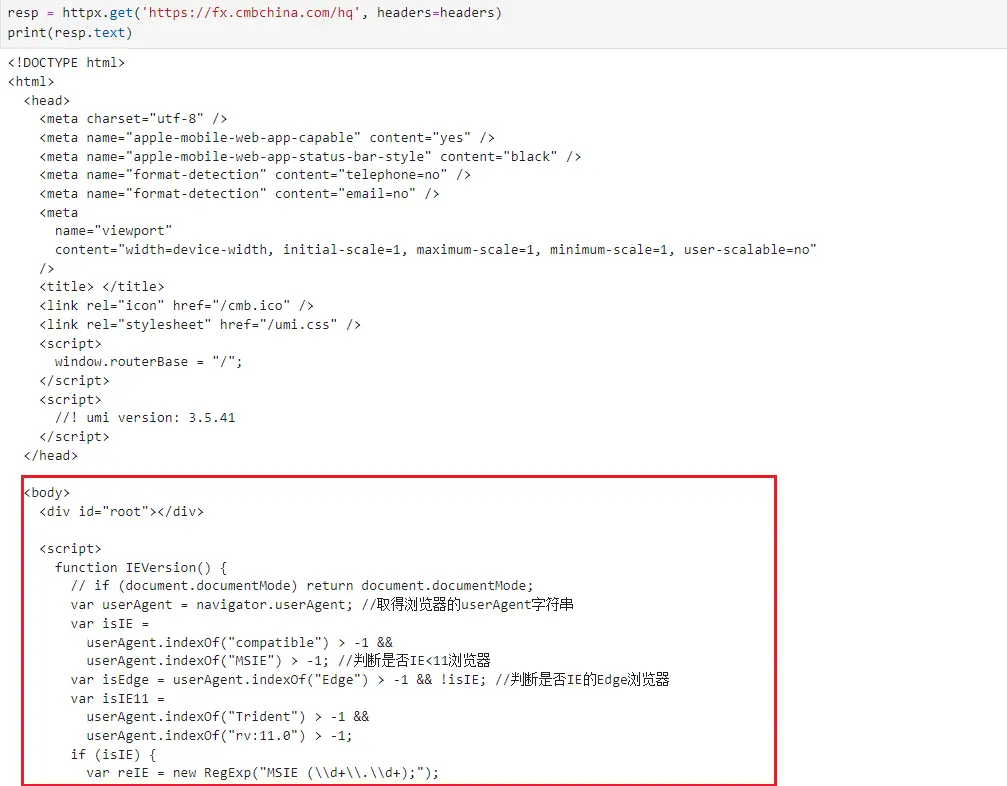
先渲染再获取就有了,再者说,你的目的肯定是只要这页面上的表格,表格就是json,获取json链接比获取渲染后的网页方便多了。可以不在页面本身的,使用dom插入,现在的数据页面基本都是这种方式,效率高且安全性好。
【猫药师Kelly】也指出使用drissionpage,配合自带的监听或者mitmproxy,能搞定很多活。
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python网络爬虫网页JS渲染源网页源码获取的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【梦】提出的问题,感谢【论草莓如何成为冻干莓】、【瑜亮老师】、【猫药师Kelly】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。






