
1 定义
一个数据集是分布式的数据集合。Spark 1.6增加新接口Dataset,提供
- RDD的优点:强类型、能够使用强大lambda函数
- Spark SQL优化执行引擎的优点
可从JVM对象构造Dataset,然后函数式转换(map、flatMap、filter等)操作。Dataset API在Scala和Java中可用。
Python不支持Dataset API,但由于Python动态性质,许多Dataset API优点已经能使用(可通过名称自然访问行的字段row.columnName)。R的情况类似。
Python支持DataFrame API是因为DataFrame API是基于Python#Pandas库构建,而Pandas库提供强大易用的数据分析工具集。因此,Spark提供对Pandas DataFrame对象的支持,使Python使用DataFrame API非常方便。Python的Pandas也提供强类型保证,使Spark可在保持动态特性同时提供类型检查和类型推断。因此,虽Python不支持Spark的Dataset API,但它支持Spark的DataFrame API,这为Python用户提供一种方便的数据处理方式。
2 案例
package com.javaedge.bigdata.cp04
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object DatasetApp {
def main(args: Array[String]): Unit = {
val projectRootPath = "/Users/javaedge/Downloads/soft/sparksql-train"
val spark = SparkSession.builder()
.master("local").appName("DatasetApp")
.getOrCreate()
import spark.implicits._
// 创建一个包含一条记录的Seq,这条记录包含一个名为 "JavaEdge" 年龄为 18 的人员信息
val ds: Dataset[Person] = Seq(Person("JavaEdge", "18"))
// 将Seq转换为一个Dataset[Person]类型数据集,该数据集只包含一条记录
.toDS()
ds.show()
val primitiveDS: Dataset[Int] = Seq(1, 2, 3).toDS()
primitiveDS.map(x => x + 1).collect().foreach(println)
val peopleDF: DataFrame = spark.read.json(projectRootPath + "/data/people.json")
val peopleDS: Dataset[Person] = peopleDF.as[Person]
peopleDS.show(false)
peopleDF.select("name").show()
peopleDS.map(x => x.name).show()
spark.stop()
}
/**
* 自定义的 case class,其中包含两个属性
*/
private case class Person(name: String, age: String)
}
output:
+--------+---+
| name|age|
+--------+---+
|JavaEdge| 18|
+--------+---+
2
3
4
+----+-------+
|age |name |
+----+-------+
|null|Michael|
|30 |Andy |
|19 |Justin |
+----+-------+
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
+-------+
| value|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
3 DataFrame V.S Dataset
val peopleDF: DataFrame = spark.read.json(projectRootPath + "/data/people.json")
val peopleDS: Dataset[Person] = peopleDF.as[Person]
peopleDS.show(false)
// 弱语言类型,运行时才报错
peopleDF.select("nameEdge").show()
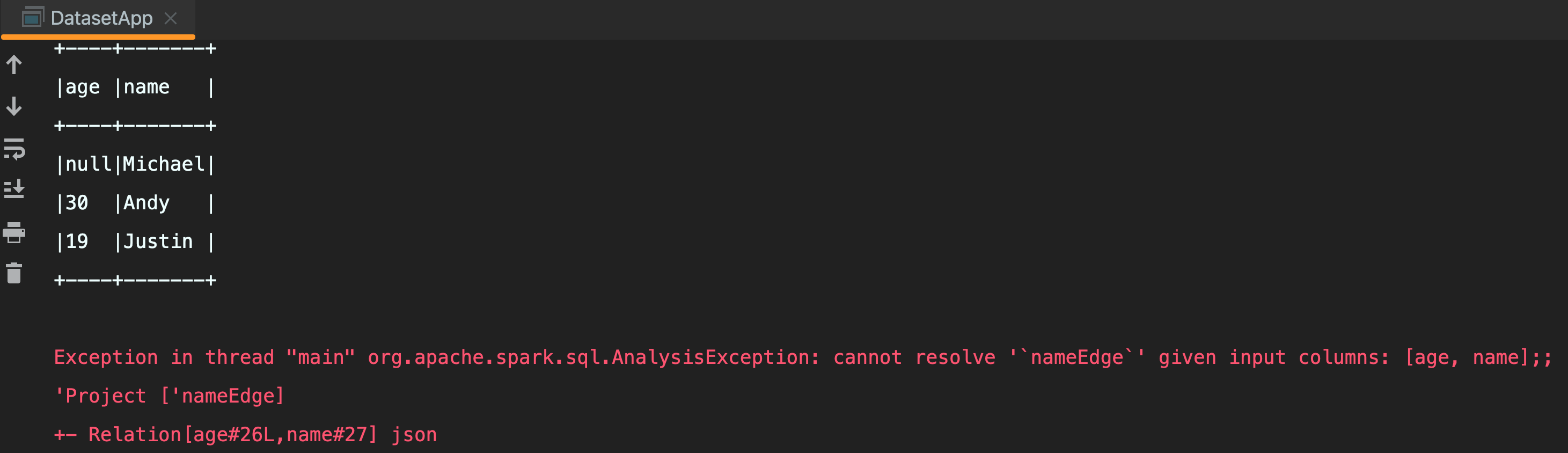
编译期报错:

关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家兼架构,多家大厂后端一线研发经验,各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:




