
00 导读
本文将介绍的论文 Long-tail Augmented Graph Contrastive Learning for Recommendation 已被 ECML/PKDD 2023 Research Track 接收。
论文中提到的模型实现,已经完全复现到 OpenAGL 里了,详情:https://github.com/TuGraph-family/TuGraph-AntGraphLearning/blob/main/README_CN.md
01 背景
推荐系统是电子商户乃至在线广告等众多在线服务的关键组成部分。其经典方法协同过滤(collaborative filtering, CF)通过观测 user / item 间的交互行为(例如点击、领取等)来产出其嵌入表征,这在个性化推荐中发挥着至关重要的作用。最近,基于图神经网络的推荐方法(例如 LightGCN 等)表现出了巨大的潜力,该方法将 user - item 交互数据表示为图,并通过邻域信息传播来迭代学习更有效的节点表示。与传统的 CF 方法相比,基于 GCN 的推荐方法能够更好的捕捉高阶协同信号,从而改进节点表征的学习。
尽管基于 GCN 的推荐方法已经被证明了其有效性,但它在真实场景中仍面临着许多数据稀疏性的问题。由于现有大多数模型遵循监督学习的训练范式,而可观测的监督信号往往仅占总交互空间极少的一部分,这也导致该类方法可能难以学到更加充分的表征。近期,有研究工作(例如 SGL、SimGCL 等)试图通过对比学习来缓解交互数据的稀疏性,它们通常依赖于预定义好的数据增强策略,如结构扰动(node/edge dropout)或特征扰动。但是,这些方法没有考虑到 Graph 中头部节点与尾部节点间存在的显著差异,其也缺乏为不同数据集构建自适应数据增强的能力,因而此类方法可能产出不均匀的分布表示,这也影响了对比学习方法本身的性能。举一个简单的例子,尾部节点由于其本身仅有少量的邻居使其在 GNN 中的表征效果远弱于头部节点,直接的结构扰动会删减其本就少量的邻居边缘,而直接的特征扰动又会引入很大的噪声,显然,本可应用于头部节点的方法难以直接作用于尾部节点中,这也就导致了现有图对比学习的方法在尾部节点的效果欠佳。
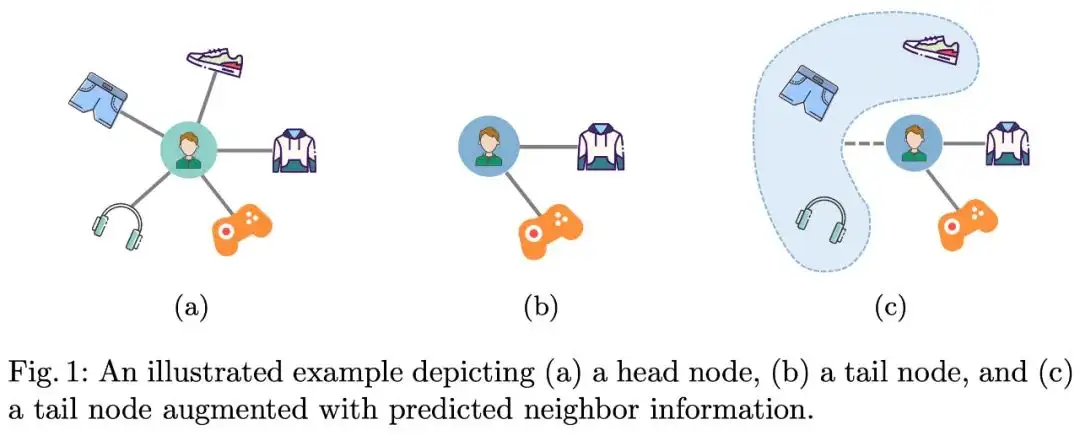
鉴于上述的限制与挑战,我们提出了一种新的长尾增强的图对比学习方法(LAGCL)。简单来说,如图 1 所示,(a) 中的头部用户与 (b) 中的尾部用户有着相似的偏好,我们的方法旨在从头部用户中提取出一种迁移模式,并有效的将其应用于尾部用户中,如 (c) 所示。具体的,我们设计了一个 auto drop 模块,它可以将头部节点(real-head node)通过自适应采样产出模拟真实尾部节点(real-tail node)的伪尾部节点(pseudo-tail node)。然后,我们利用 pseudo-tail node 当前的子图结构以及其残缺子图结构来学习知识迁移模块(knowledge transfer module),该模块旨在通过为尾部节点添加预测的邻域缺失信息来将其扩充为 pseudo-head node(即长尾增强的尾部节点,augmented tail node)。我们使用生成对抗网络来确保自适应采样产出的 pseudo-tail node 更像 real-tail node,同时也确保 pseudo-head node 无论从信息量还是信息精度上都更接近 real-head node。最后,我们通过对 real/pseudo head node 做特征扰动下的对比学习,进一步的提升长尾增强节点的稳定性与整体表征的均匀性。
02 模型方法
在本节中,我们将介绍长尾增强的图对比学习方法 LAGCL(如图 2 所示)。模型整体上遵循一般的对比学习范式,我们首先通过自适应采样模块以及知识迁移模块来增强尾部节点的表示,随后利用特征扰动的方式产出不同的 view,最后通过对比学习来约束使不同 view 的相同节点表征更相近,不同节点表征更不同。在该框架下,模型的主任务依然是推荐任务(例如 CTR 预估等),而对比学习以及知识迁移等模块均为辅助任务。
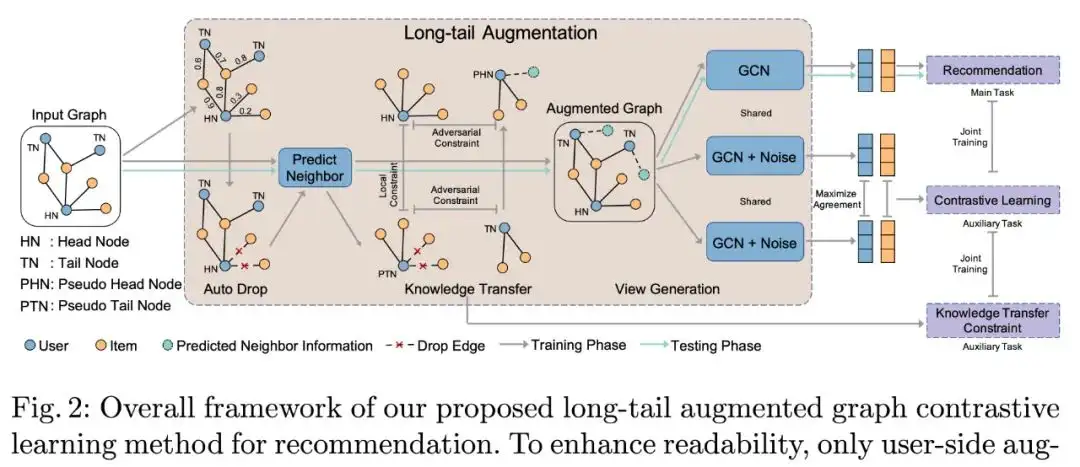
图 2 中包含几种类型的节点,其具体定义如下:
HN(real-head node),头部节点,即原始图中节点度 >k 的节点
TN(real-tail node),尾部节点,即原始图中节点度 <=k 的节点
PTN(pseudo-tail node),伪标签尾部节点,即头部节点做完自适应采样(Auto Drop)后的节点
PHN(pseudo-head node),伪标签头部节点,即尾部节点/伪标签尾部节点做完知识迁移(Knowledge Transfer)操作后的节点
2.1 长尾增强技术
在开始具体的方法描述前,首先介绍一下本文的一些前提与假设。在 Graph 中,本文通过节点度阈值 k来将所有节点划分为头部(degree>k)与尾部(degree<=k)。此外,我们假设每一个节点都存在一个 ground truth 的邻域集合,而头部节点拥有完备的邻域集合,尾部节点其可观测的邻居仅为完备邻域的一个子集。不完备的邻域信息会对模型效果产生负面的影响,因此,长尾增强技术旨在为尾部节点补齐邻域缺失的信息,并依此来最大化头尾节点表征的一致性。本文方法背后的直觉是,当前头部节点已经充分观测到了邻居信息,那如果我们可以通过对头部节点自适应采样来产出更像真实尾部节点(real-tail node)的 pseudo-tail node,那么我们便可以利用 pseudo-tail node 来学习长尾增强的策略。该策略可分为以下三个模块:自适应采样模块、知识迁移模块以及生成对抗学习模块。
自适应采样模块(Auto Drop)
一种直观的方法是通过对头部节点的邻居做随机采样来产出 pseudo-tail node,但这种方法缺乏有效的监督信号来指导采样的过程,因此会导致 pseudo-tail node 与 real-tail node 之间存在一定的分布偏差。为了改进采样的过程,我们提出了一种可训练的自适应采样模块,它主要由边权重计算以及根据权重做过滤两个步骤,其中节点间的重要性权重计算公式如下:
 为 n 个节点 d 维的表征,A为 Graph 的邻接矩阵,⊙ 为点乘的操作。随后,为了模拟真实的尾部节点,我们从 [1,k] 的范围内随机为每个头部节点分配一个目标的邻居数量
为 n 个节点 d 维的表征,A为 Graph 的邻接矩阵,⊙ 为点乘的操作。随后,为了模拟真实的尾部节点,我们从 [1,k] 的范围内随机为每个头部节点分配一个目标的邻居数量 �� ,我们将要对这些头部节点采样到 �� 的节点度。
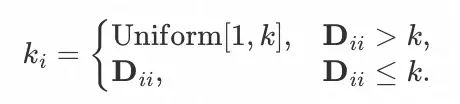
为节点的度矩阵(对角矩阵),其中 ��� 为 A中节点 i 的度。最后,我们为每个节点保留与其在重要性矩阵 S 中最大的 �� 个邻居,并产出新的邻接矩阵如下:
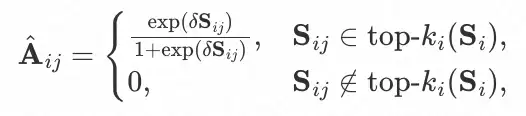
δ 是用于控制 �^ 平滑性的超参数,我们定义 ��^ 为 �^ 中节点 i 的邻居集合。
知识迁移模块(Knowledge Transfer)
在有了自适应采样模块后,本节所设计的知识迁移模块是利用 pseudo-tail node 已知的邻域缺失信息来训练如何为 real-tail node 预测其真实的邻域缺失信息。具体的,我们利用多层感知机
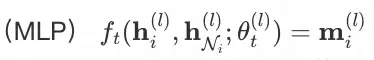
基于中心节点表征以及可观测邻域的表征来预测缺失的邻域信息。
ℎ�(�) 为节点 i 在第 l 层 GNN 后的表征,ℎ��(�)为可观测邻居的 mean pooling 表征,预测所得的ℎ��(�)将作为尾部节点的虚拟邻居参与其消息传播。因此,在自适应采样产出的稀疏图�^中,头部节点 i (pseudo-head node)的信息聚合函数如下:
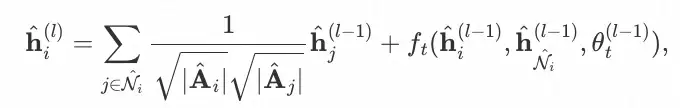
其中
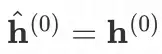
,头部节点 i 在原始图 A 中的信息聚合函数如下:
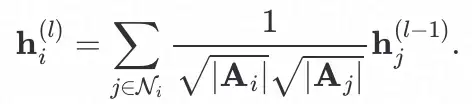
为了训练知识迁移函数,我们定义了如下的损失:
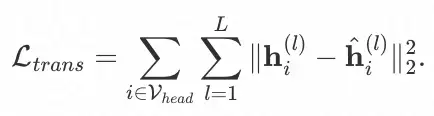
生成对抗学习模块(Generative Adversarial Learning)
为了更有效的学习长尾增强的策略,自适应采样模块所产出的 pseudo-tail node 应尽可能的更接近 real-tail node,因此,我们在稀疏图�^中定义了如下的运算,其中
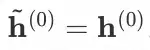
。
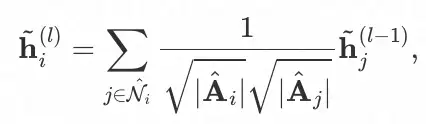
此外,知识迁移模块所产出的 pseudo-head node 也应尽可能的接近 real-head node。为了实现这两点,我们引入了生成对抗网络。鉴别器的目标是根据节点表征来区分 pseudo head/tail node 与 real head/tail node,而生成器旨在使提供的信息在鉴别器中都会被归类为 real。具体的,我们为 pseudo-tail node 与 real-tail node 间定义了如下的对抗约束:
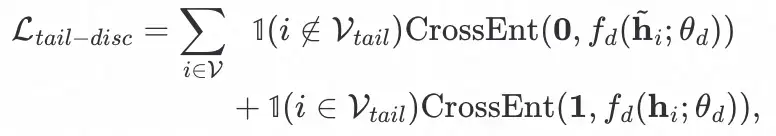
为 pseudo-head node 与 real-head node 间定义了如下的对抗约束:
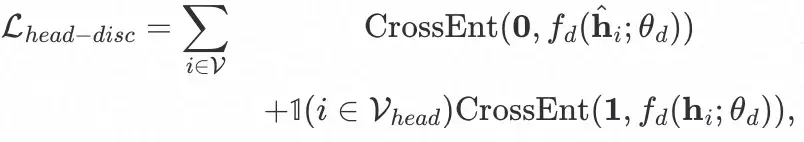
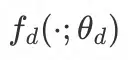
为鉴别器网络,其输入为节点的表征,输出为该节点属于 real 类别的概率,定义如下:
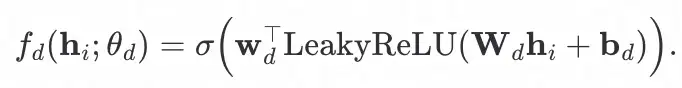
2.2 对比学习
基于前文的知识迁移模块,我们可以通过下式得到尾部节点增强后的节点表征。
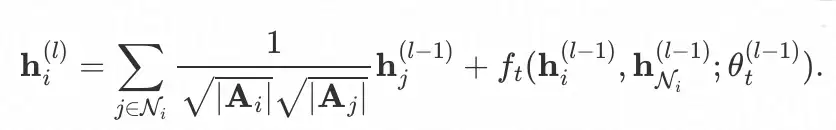
随后,我们参考了 SimGCL 中的特征扰动方法,其通过在空间中相同象限下对向量做轻微旋转来生成新的视图,该操作可形式化为:
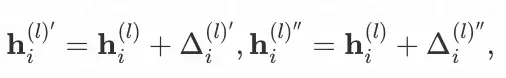
其中,扰动向量 Δ�′ 与Δ�″服从
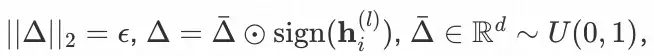
超参数 ϵ 可控制扰动的幅度。为了简单起见,我们用 ℎ� 代表节点 i 在第 L 层 GNN 聚合后的最终表征,此时ℎ�′与ℎ�″即为对比学习所需的两个 view。最后,我们利用 InfoNCE 来最大化相同节点的表征一致性,最小化不同节点间的表征相似性,InfoNCE 的定义如下(以 user 侧为例):
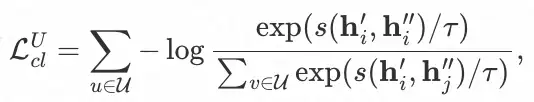
其中 s(⋅) 为距离度量函数,例如余弦相似度;γ 为预定义的超参数(temperature)。同理,我们可以计算 item 侧的对比损失
,则对比学习模块最终的损失函数为
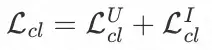
2.3 多任务训练
在 LAGCL 中,我们采用多任务的训练策略进行联合优化,包括主推荐任务以及一些辅助任务(知识迁移部分、对抗网络部分以及对比学习部分等)。我们的目标是最小化下式:
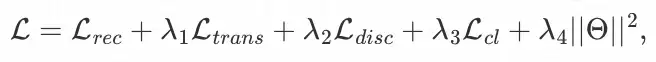
其中,θ 为模型参数, �1 ,�2,�3,�4为用于控制各辅助任务强度的超参数,
为主要的推荐任务损失函数(本文使用的是 Bayesian Personalized Ranking (BPR) loss)。
03 实验
3.1 有效性实验
我们在 Yelp2018、Amazon-Book 以及 Movielens-25M 这三个公开数据集中验证了我们的模型,这三个数据集有着不同的数据量级与稀疏度。
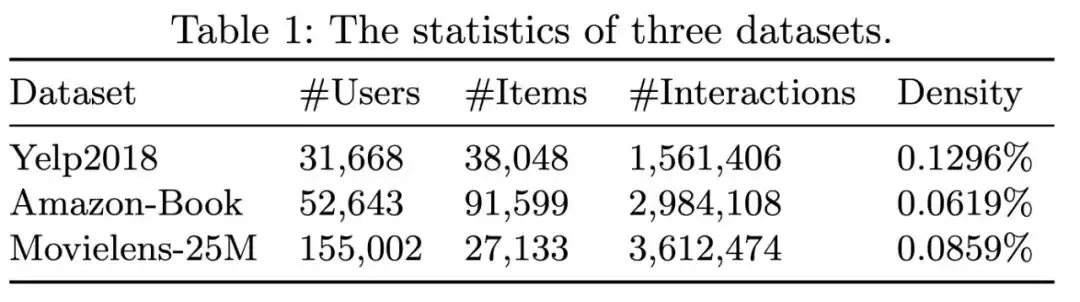
从实验结果上看:
所有基于 Graph 的对比学习方法(SGL[2]、NCL[5]、RGCF[6]、SimGCL[3]、LAGCL)均优于 LightGCN,这表明对比学习方法在协同过滤任务中是有效的。
SimGCL 相比 SGL、NCL、RGCF 有着更显著的效果,这表明特征扰动的数据增强策略比结构扰动更适合协同过滤任务。
本文方法通过增强尾部节点的邻域信息,避免了特征扰动直接作用于尾部节点所引入大量噪声的问题。最终,LAGCL 取得了最佳的效果。
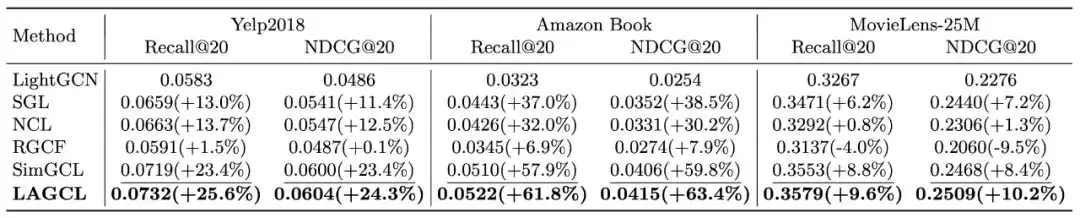
3.2 消融实验
我们验证了实验每个子模块的有效性,其中『w/o AD』代表使用随机采样替代自适应采样,『w/o KT』代表去除为尾部节点弥补邻域缺失信息的知识迁移模块,『w/o GAN』代表去除训练中所有的生成对抗网络。从消融实验中,我们有如下结论:
本文所提出的每个子模块都是有效的,且弥补尾部节点邻域缺失信息的知识迁移模块的作用最大。
自适应采样能够更好的捕获到节点与其邻居之间通过随机采样所学习不到的迁移模式。
生成对抗网络能够确保自适应采样产出的 pseudo-tail node 更像 real-tail node,且能保证知识迁移模块产出的 pseudo-head node 从信息丰富度与准确性上更接近 real-head node。它保证了 LAGCL 整个训练框架的有效性。
3.3 模型详细分析
分布均匀性分析
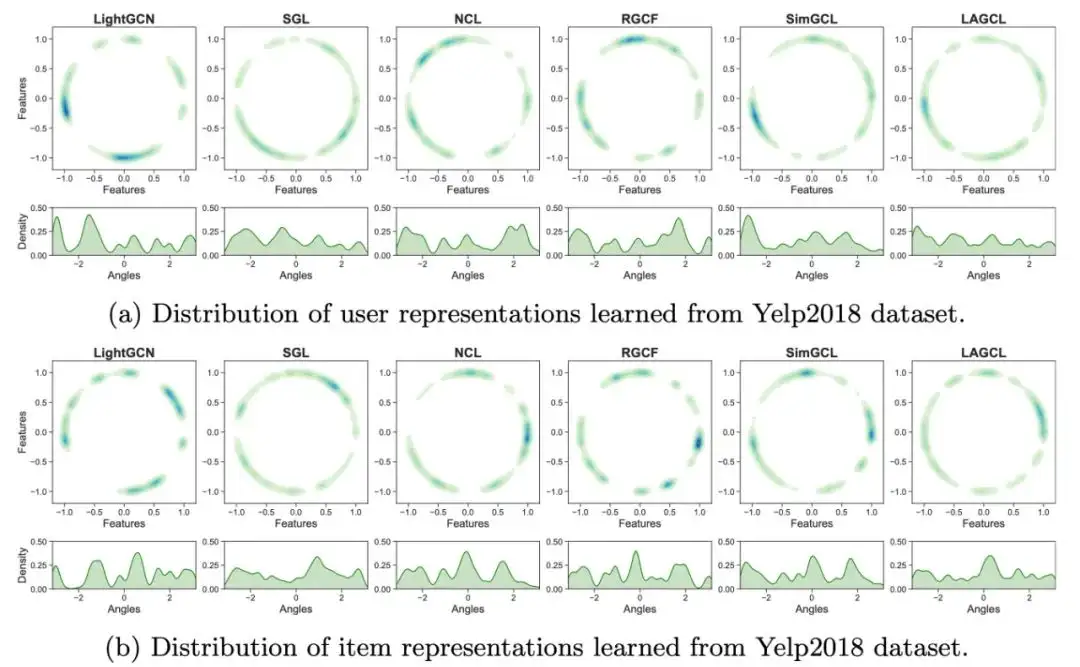
为了更好的理解 LAGCL,我们对模型训练产出的 user 与 item 的表征进行可视化。先前的研究表明[3,4],对比学习与表征均匀性之间存在着很强的关联,因此,我们推测更均匀的表征分布能够赋予模型更好的能力来捕获不同的 user 偏好以及 item 特性。从图中可以看出,无对比学习的 LightGCN 其分布在圆弧上有多个聚簇,而其他图对比学习的方法其表征分布则更均匀。在基线中,SimGCL 的表现最佳,而本文方法相比于 SimGCL,弧上的暗区更少,因此具有更均匀的分布。
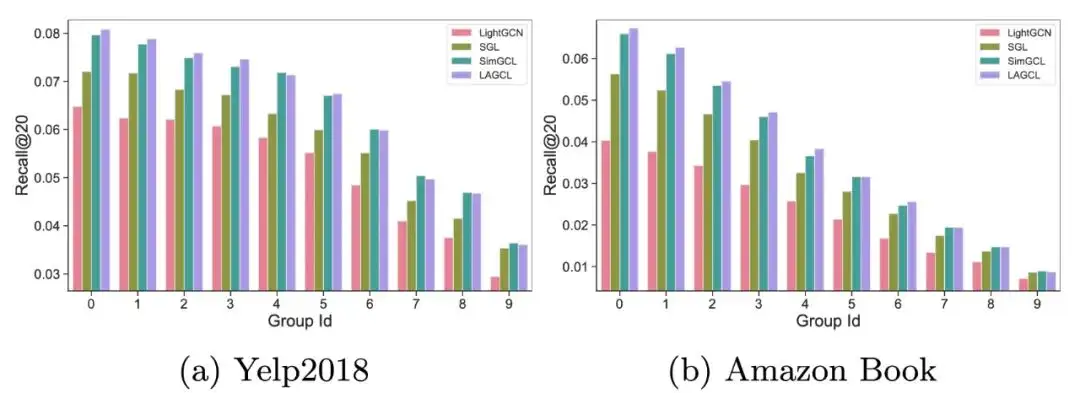
长尾性能分析
为了探究 LAGCL 是否可以真的为尾部节点带来额外的性能增益,我们根据 user-item 二分图中的节点度数,将用户节点等频划分为了 10 组。Group Id 越小,节点度越低,用户的活跃性也越低。从结果上看,LAGCL 在低活用户中有着更好的性能增益,而高活用户与其他基线差别不大。tips: 当前观测的指标为 Recall,由于低活用户本身行为较少,因此其在计算 Recall 时的分母比高活用户要小很多,所以实验呈现尾部效果 > 头部效果的趋势。
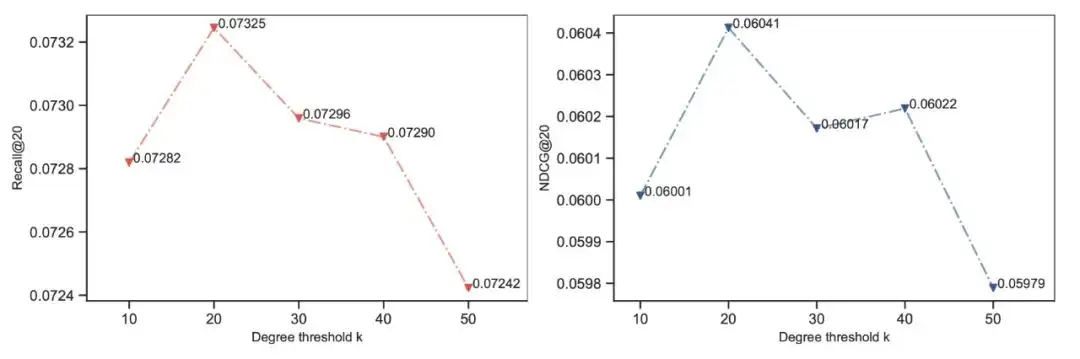
阈值 k 敏感性分析
我们对划分头尾节点的阈值 k 做了参数敏感性分析,在 Yelp2018 数据集中,当 k=20 时模型达到最佳性能。更大或更小的 k 都会导致效果下降,因此有以下结论:
LAGCL 能够通过节点度 >k 的头部点来学习知识迁移策略,最终为尾部节点带来增益
较大的 k 会导致训练知识迁移模块的头部数据不足,而较小的 k 会导致头部用户内部的数据质量参差不齐,因此选择合适的 k 能够最大程度地提高整体收益
04 总结
本文提出了一种新的长尾增强的图对比学习方法(LAGCL),该方法促使模型同时兼顾头部节点与尾部节点之间的知识,并通过长尾增强技术来使模型产出更均匀更准确的节点表征,从而改进基于 GNN 的推荐任务。具体的,我们通过使用预测的邻域缺失信息来增强尾部节点的表征。为了使整个过程可学习,我们设计了一种从头部节点生成 pseudo tail node 的自适应采样模块,以及从 pseudo tail node 节点重构为 pseudo head node 的知识迁移模块。最后,我们基于生成对抗网络以及对比学习保证了整个训练框架的可靠性。实验结果表明我们的方法是有效的。
05 作者简介
赵前(im0qianqian、千千),一个电脑迷、技术控,退役 ACMer(CF 2000+)。主要研究图学习、推荐算法、大语言模型与知识图谱的应用,曾在 SemEval 2020, WSDM Cup 2022 等国际赛事中取得过冠军。





