
深度学习中损失函数是整个网络模型的“指挥棒”, 通过对预测样本和真实样本标记产生的误差反向传播指导网络参数学习。
分类任务的损失函数
假设某分类任务共有N个训练样本,针对网络最后分层第 i 个样本的输入特征为
交叉熵损失函数(cross entropy)
交叉熵损失函数又叫 softmax 损失函数。 是目前卷积神经网络中最常用的分类目标损失函数。
举个例子,比如 C = 3 ,也就是最后分类结果有三种,分别是0,1,2.假设对于第 i 个样本正确分类是1,h=(2,5,1),那么交叉熵损失函数就等于:
-(1 / 3)* (log((e^5) / (e^2 + e^5 + e^1)))
合页损失函数(hinge loss)
合页函数广泛在支持向量机中使用,有时也会在损失函数中使用。
在分类任务中,通常使用交叉熵函数要优于使用合页损失函数。
缺点:合页损失函数是对错误越大的样本施以更严重的惩罚。可是这样会导致损失函数对噪音敏感。举例,如果一个样本的标记错误或者是离群点,则由于错分导致分类误差会很大,如此便会影响整个分类超平面的学习,从而降低模型泛化能力。
坡道损失函数(ramp loss function)
优点:克服了合页损失函数鲁棒性差的特点,对噪声数据和离群数据有很好的抗噪能力。因此也被称作鲁棒损失函数。这类损失函数的特点是在分类(回归)问题误差较大区域进行了截断,使得较大的误差不再影响整个损失函数。
s指定了截断点的位置。
合页损失函数和坡道损失函数对比图: 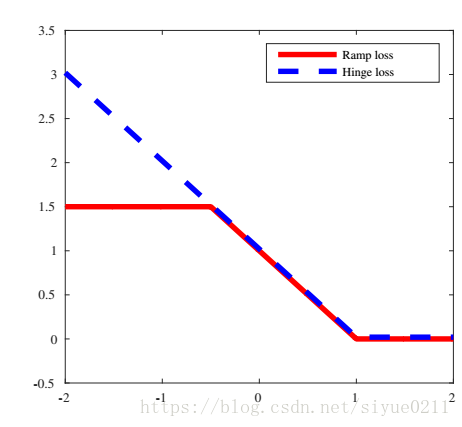
截断点 s = - 0.5 。
问题:坡道损失函数在x=1 和 x=s两处不可导,如何进行误差方向传播。真实情况下并不要求必须严格满足数学上的连续。因为计算机内部的浮点计算并不会得到完全导数落在尖点上的非常情况,最多只会落在尖点附近,仅需给出对应的导数值,因此数学上的尖点不影响使用。
对于截断点的设置,s的取值最好根据类别数C来定,一般设置为s = -1 / (C - 1)
交叉熵损失函数, 合页损失函数和坡道损失函数只是简单衡量模型预测值与样本真实值之间的误差从而指导训练。他们并没有显示的将特征判别性学习考虑到整个网络训练中,对此,为了进一步提高学习到的特征表示的判别性,近期研究者设计了一些新的损失函数如下:
大间隔交叉熵损失函数
网络的输出结果 h 实际上是全连接层参数 W 和最后一层的特征向量
其中
式子中
以二分类为例,我们希望正确样本的分数大于错误样本的分数,因此希望参数
那么大间隔交叉熵损失函数为了让特征更具有分辨能力则在这个基础上要求两者差距更大,于是引入m拉开差距, 这便是大间隔的由来。||W1|| ||xi|| cos(mθ1) > ||W2|| ||xi|| cos(θ2) (0 <=
综上: ||W1|| ||
定义:
相比于传统的交叉熵损失函数,仅仅是将第i类间隔拉大了, 其中:
k 为整数, k 属于[0, m-1]
下图表示了在二分类情况下,W1, W2 的模在等于, 小于, 大于三种不同关系下的决策边界。
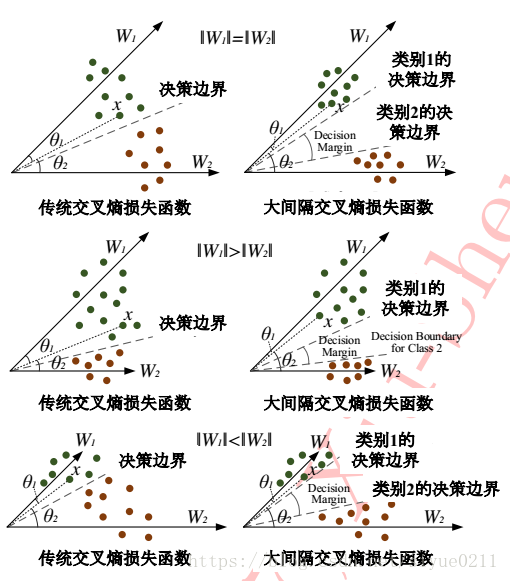
可以看出大间隔交叉熵损失函数扩大了类间的距离, 由于它不仅要求分类正确且要求分开的类保持较大的间隔。使得目标比传统交叉熵更加困难。训练目标变得困难带来的一个额外的好处就是起到防止过拟合的作用。并且在分类性能方面,大间隔交叉熵损失函数要优于交叉熵损失函数和合页函数。
中心损失函数
大间隔交叉熵损失函数主要考虑增加类间距离, 而中心损失函数则在考虑类间距离的同时还将一些注意力放在减少类间差异上。
中心损失函数定义:
其中
式子中 λ 为两个损失函数之间的调节,λ 越大类内差异占整个目标函数较大比重。
回归任务的损失函数
在分类任务中,样本的真实标记实际上对应 one hot vector : 对样本
在介绍不同回归任务的损失函数之前,首先介绍一个回归的基本概念,残差或称预测误差,用于衡量预测值和真实标记的靠近程度。假设回归问题对应第
l1损失函数
常用的回归问题的损失函数是l1 和 l2损失函数。对N个样本的L1损失函数定义如下:
l2损失函数
Tukey’s biweight 损失函数
同分类中提到的坡道损失函数一样, Tukey’s biweight损失函数也是一类非凸损失函数。可克服回归任务中离群点或样本噪声对整体回归模型的干扰和影响,是回归任务中一种鲁棒的损失函数,其定义:
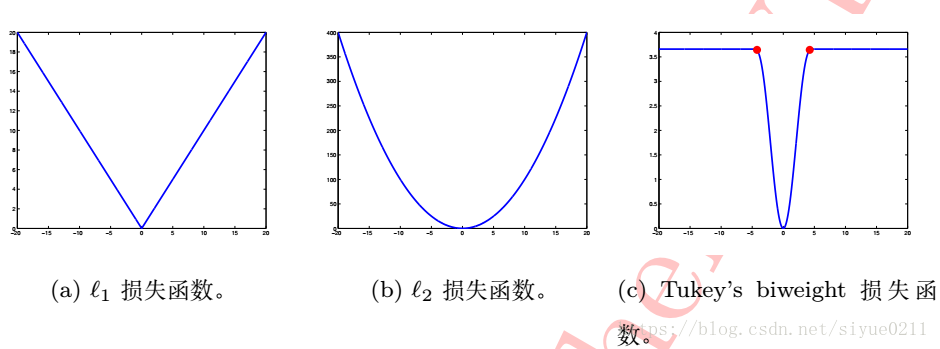
式子中,常数C指定了函数拐点,需要指出的是,该超参数并不需要人为设定,常用的C=4.6851 时, Tukey’s biweight损失函数可取得与 l2 损失函数 在最小化符合标准正态分布的残差类似的回归效果。
参考
解析卷积神经网络——深度学习实践手册





