
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【哎呦喂 是豆子~】问了一个Pandas数据处理问题,一起来看看吧。问题描述:
大佬们 这个是为啥呀啊? 为啥替换后int类的数据直接NaN了 加加了判断也是没替换成功
原始数据如下:
tt = pd.DataFrame({'name':['A','B','C'],
'money':[15,'17$',58],
'id':['$15',25,'25$52']
})
她自己的原始代码如下所示:
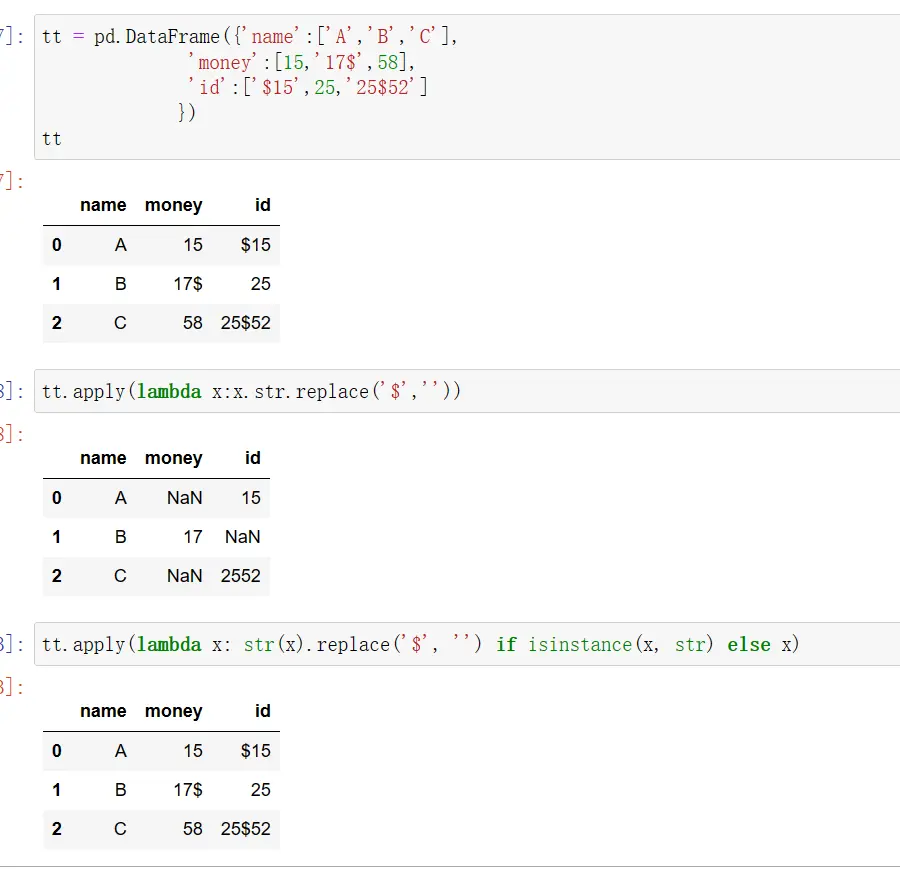
二、实现过程
这里【隔壁😼山楂】给了自己的代码,如下:
import pandas as pd
tt = pd.DataFrame({'name':['A','B','C'],
'money':[15,'17$',58],
'id':['$15',25,'25$52']
})
res = tt.replace("\$", "", regex=True)
print(res)
代码运行之后,结果如下:
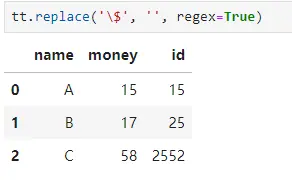
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据处理问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【哎呦喂 是豆子~】提出的问题,感谢【隔壁😼山楂】给出的思路,感谢【莫生气】、【猫药师Kelly】、【冫马讠成】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。






