
作者1:Mehdi Mirza,D ́epartement d’informatique et de recherche op ́erationnelle Universit ́e de Montr ́eal,Montr ́eal, QC H3C 3J7,
作者2:Simon Osindero,Flickr / Yahoo Inc. San Francisco, CA 94103
一、Abstract(摘要)
- Generative Adversarial Nets were recently introduced as a novel way to train generative models.
生成对抗网是最近推出的一种训练生成模型的新方法。
词汇;1. recently(adverb):最近;2. introduce(verb):介绍;3.a novel way:一种新方法。 - In this work we introduce the conditional version of generative adversarial nets, which can be constructed by simply feeding the data, y, we wish to condition on to both the generator and discriminator.
在这项工作中,我们引入了条件版生成式对抗网,只需将我们希望作为条件的数据 y 输入生成器和判别器即可构建生成式对抗网。
**词汇;1.construct(verb):构建;2.simply(adverb):简单地; 3.feeding(noun)喂养; ** - We show that this model can generate MNIST digits conditioned on class labels.
我们的研究表明,该模型可以生成以类别标签为条件的 MNIST 数字。
** 词汇;1.digit(noun):数字;** - We also illustrate how this model could be used to learn a multi-modal model, and provide preliminary examples of an application to image tagging in which we demonstrate how this approach can generate descriptive tags which are not part of training labels.
我们还说明了如何利用该模型学习多模态模型,并提供了应用于图像标记的初步示例,其中我们演示了这种方法如何生成不属于训练标签的描述性标签。
词汇;1.illustrate(verb):阐明;2.multi-modal(adjective):多模态;3.provide(verb):提供;
4.preliminary(adjective):初步的;5.tagging(noun):标记;6.demonstrate(verb):证明;
7.approach(noun):方法;8. descriptive(adjective):描述性的
二、Introduction 简介
- Generative adversarial nets were recently introduced as an alternative framework for training generative models in order to sidestep the difficulty of approximating many intractable probabilistic computations.
生成对抗网是最近推出的一种训练生成模型的替代框架,目的是避免近似许多难以处理的概率计算的困难。 - Adversarial nets have the advantages that Markov chains are never needed, only backpropagation is used to obtain gradients, no inference is required during learning, and a wide variety of factors and interactions can easily be incorporated into the model.
对抗网络的优势在于:无需马尔可夫链,只需使用反向传播来获取梯度,学习过程中无需推理,而且可以轻松地将各种因素和相互作用纳入模型。 - Furthermore,as demonstrated in,it can produce state of the art log-likelihood estimates and realistic samples.
此外,正如本文所示,它还能产生最先进的对数似然估计值和现实样本。 - In an unconditioned generative model, there is no control on modes of the data being generated.
在无条件生成模型中,生成数据的模式不受控制。 - However, by conditioning the model on additional information it is possible to direct the data generation process.
然而,通过对额外信息对模型进行调节,可以指导数据生成过程。 - Such conditioning could be based on class labels, on some part of data for inpainting like , or even on data from different modality.
这种调节可以基于类标签,也可以基于用于内绘的部分数据,如 ,甚至可以基于不同模态的数据。 - In this work we show how can we construct the conditional adversarial net.
在这项工作中,我们将展示如何构建条件对抗网。 - And for empirical results we demonstrate two set of experiment.
为了获得实证结果,我们演示了两组实验。 - One on MNIST digit data set conditioned on class labels and one on MIR Flickr 25,000 dataset for multi-modal learning.
一个是以类标签为条件的 MNIST 数字数据集,一个是用于多模态学习的 MIR Flickr 25,000 数据集
三、Related Work
3.1 Multi-model Learning For Image Labelling(图像标记的多模态学习)
- Despite the many recent successes of supervised neural networks (and convolutional networks in particular) , it remains challenging to scale such models to accommodate an extremely large number of predicted output categories.
尽管有监督神经网络(尤其是卷积网络)最近取得了许多成功,但要扩展此类模型以适应数量极多的预测输出类别,仍然具有挑战性。 - A second issue is that much of the work to date has focused on learning one-to-one mappings from input to output.
第二个问题是,迄今为止的大部分工作都侧重于学习从输入到输出的一对一映射。 - However, many interesting problems are more naturally thought of as a probabilistic one-to-many mapping.
然而,许多有趣的问题更自然地被视为概率性的 "一对多 "映射。 - For instance in the case of image labeling there may be many different tags that could appropriately applied to a given image, and different (human) annotators may use different (but typically synonymous or related) terms to describe the same image.
例如,在图像标注的情况下,可能有许多不同的标签可以适当地应用于给定的图像,不同的(人类)注释者可能会使用不同的(但通常是同义或相关的)术语来描述同一幅图像。 - One way to help address the first issue is to leverage additional information from other modalities: for instance, by using natural language corpora to learn a vector representation for labels in which geometric relations are semantically meaningful.
帮助解决第一个问题的方法之一是利用来自其他模式的额外信息:例如,通过使用自然语言语料库来学习几何关系具有语义意义的标签向量表示法。 - When making predictions in such spaces, we benefit from the fact that when prediction errors we are still often ‘close’ to the truth (e.g. predicting ’table’ instead of ’chair’), and also from the fact that we can naturally make predictive generalizations to labels that were not seen during training time.
在这样的空间中进行预测时,我们会受益于这样一个事实:当预测错误时,我们往往仍然 "接近 "真相(例如,预测 "桌子 "而不是 “椅子”),而且我们可以自然地对训练期间未见的标签进行预测归纳。 - Works such as have shown that even a simple linear mapping from image feature-space to word-representation-space can yield improved classification performance.
等工作表明,即使是从图像特征空间到单词表示空间的简单线性映射,也能提高分类性能。 - One way to address the second problem is to use a conditional probabilistic generative model, the input is taken to be the conditioning variable and the one-to-many mapping is instantiated as a conditional predictive distribution.
解决第二个问题的方法之一是使用条件概率生成模型,将输入作为条件变量,并将一对多映射实例化为条件预测分布。 - take a similar approach to this problem, and train a multi modal Deep Boltzmann Machine on the MIR Flickr 25,000 dataset as we do in this work.
在这个问题上,我们采用了类似的方法,在 MIR Flickr 25,000 数据集上训练多模态深度玻尔兹曼机。 - Additionally, in the authors show how to train a supervised multi-modal neural language model, and they are able to generate descriptive sentence for images.
此外,作者还展示了如何训练有监督的多模态神经语言模型,并能为图像生成描述性句子。
四、Conditional Adversarial Nets(条件对抗网络)
4.1 Generative Adversarial Nets(生成对抗网络)
- Generative adversarial nets were recently introduced as a novel way to train a generative model.
生成对抗网是最近推出的一种训练生成模型的新方法。 - They consists of two ‘adversarial’ models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G.
它们由两个 "对抗 "模型组成:一个是捕捉数据分布的生成模型 G,另一个是估计样本来自训练数据而非 G 的概率的判别模型 D。 - Both G and D could be a non-linear mapping function, such as a multi-layer perceptron.
G 和 D 都可以是非线性映射函数,如多层感知器。 - To learn a generator distribution pg over data data x, the generator builds a mapping function from a prior noise distribution pz (z) to data space as G(z; θg ).
为了学习数据 x 上的生成器分布 pg,生成器建立了从先验噪声分布 pz (z) 到数据空间的映射函数 G(z; θg ) 。 - And the discriminator, D(x; θd), outputs a single scalar representing the probability that x came form training data rather than pg .
而判别器 D(x; θd) 则输出一个标量,代表 x 来自训练数据而非 pg 的概率。 - G and D are both trained simultaneously: we adjust parameters for G to minimize log(1 − D(G(z)) and adjust parameters for D to minimize logD(X), as if they are following the two-player min-max game with value function V (G, D):
G 和 D 的训练是同时进行的:我们调整 G 的参数,使 log(1 - D(G(z)) 最小化,调整 D 的参数,使 logD(X) 最小化,就像在进行价值函数 V (G, D) 的双人最小最大博弈: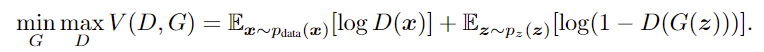
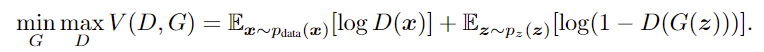
4.2 Conditional Adversarial Nets(条件对抗网络)
- Generative adversarial nets can be extended to a conditional model if both the generator and discrim-inator are conditioned on some extra information y.
如果生成器和判别器都以某些额外信息 y 为条件,生成式对抗网就可以扩展为条件模型。 - y could be any kind of auxiliary information, such as class labels or data from other modalities.
y 可以是任何类型的辅助信息,如类别标签或来自其他模态的数据。 - We can perform the conditioning by feeding y into the both the discriminator and generator as additional input layer.
我们可以将 y 作为附加输入层输入到鉴别器和发生器中,从而进行调节。 - In the generator the prior input noise pz (z), and y are combined in joint hidden representation, and the adversarial training framework allows for considerable flexibility in how this hidden representation is composed.
在生成器中,先验输入噪声 pz (z) 和 y 被组合在联合隐藏表示中,对抗训练框架允许在如何组成隐藏表示方面有相当大的灵活性。 - In the discriminator x and y are presented as inputs and to a discriminative function (embodied again by a MLP in this case).
在判别器中,x 和 y 分别作为输入和判别函数(在本例中同样由 MLP 体现)。 - The objective function of a two-player minimax game would be as Eq 2.
双人最小博弈的目标函数为公式 2。

- Fig 1 illustrates the structure of a simple conditional adversarial net.
图 1 展示了一个简单的条件对抗网的结构。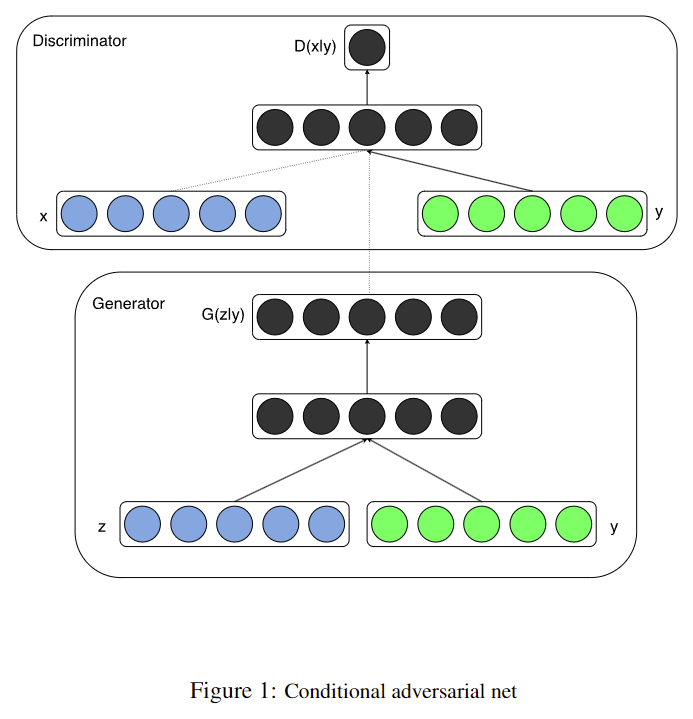

五、Experimental Results(实验结果)
5.1 Unimodal(单模式)
- We trained a conditional adversarial net on MNIST images conditioned on their class labels, encoded as one-hot vectors.
我们在 MNIST 图像上训练了一个条件对抗网,其条件是图像的类别标签,编码为单击向量。 - In the generator net, a noise prior z with dimensionality 100 was drawn from a uniform distribution within the unit hypercube.
在生成器网络中,从单位超立方体内的均匀分布中提取了维数为 100 的噪声先验 z。 - Both z and y are mapped to hidden layers with Rectified Linear Unit (ReLu) activation [4, 11], with layer sizes 200 and 1000 respectively, before both being mapped to second, combined hidden ReLu layer of dimensionality 1200.
z 和 y 被映射到具有整流线性单元(ReLu)激活功能的隐藏层[4, 11],层的大小分别为 200 和 1000,然后被映射到维度为 1200 的第二个组合隐藏 ReLu 层。 - We then have a final sigmoid unit layer as our output for generating the 784-dimensional MNIST samples.
然后,我们以最终的 sigmoid 单元层作为输出,生成 784 维的 MNIST 样本。
注意:For now we simply have the conditioning input and prior noise as inputs to a single hidden layer of a MLP, but one could imagine using higher order interactions allowing for complex generation mechanisms that would be extremely difficult to work with in a traditional generative framework.
现在,我们只需将调节输入和先验噪声作为 MLP 单个隐层的输入,但我们可以想象使用更高阶的交互来实现复杂的生成机制,这在传统的生成框架中是极其困难的。

Table 1: Parzen window-based log-likelihood estimates for MNIST. We followed the same procedure as for computing these values.
表 1:基于 Parzen 窗口的 MNIST 对数似然估计值。我们采用了与计算这些值相同的程序。
- The discriminator maps x to a maxout layer with 240 units and 5 pieces, and y to a maxout layer with 50 units and 5 pieces.
判别器将 x 映射到最大输出层,该层有 240 个单元和 5 个片段,将 y 映射到最大输出层,该层有 50 个单元和 5 个片段。 - Both of the hidden layers mapped to a joint maxout layer with 240 units and 4 pieces before being fed to the sigmoid layer.
两个隐层都映射到一个有 240 个单元和 4 个片段的联合最大输出层,然后再送入 sigmoid 层。 - (The precise architecture of the discriminator is not critical as long as it has sufficient power; we have found that maxout units are typically well suited to the task.)
(只要具有足够的能力,判别器的精确架构并不重要;我们发现 maxout 单元通常非常适合该任务。) - The model was trained using stochastic gradient decent with mini-batches of size 100 and initial learning rate of 0.1 which was exponentially decreased down to .000001 with decay factor of 1.00004.
该模型采用随机梯度梯度法进行训练,小批次大小为 100,初始学习率为 0.1,学习率以指数方式下降到 0.000001,衰减系数为 1.00004 - Also momentum was used with initial value of .5 which was increased up to 0.7.
此外,动量的初始值为 0.5,后来增加到 0.7。 - Dropout with probability of 0.5 was applied to both the generator and discriminator.
生成器和判别器均采用概率为 0.5 的 Dropout。 - And best estimate of log-likelihood on the validation set was used as stopping point.
并以验证集上的最佳估计对数似然作为停止点。
Table 1 shows Gaussian Parzen window log-likelihood estimate for the MNIST dataset test data.
表 1 显示了 MNIST 数据集测试数据的高斯 Parzen 窗口对数似然估计。 - 1000 samples were drawn from each 10 class and a Gaussian Parzen window was fitted to these samples.
从每 10 个类别中抽取 1000 个样本,并对这些样本拟合高斯帕尔森窗口。 - We then estimate the log-likelihood of the test set using the Parzen window distribution.
然后,我们使用帕尔森窗分布估计测试集的对数似然。 - The conditional adversarial net results that we present are comparable with some other network based, but are outperformed by several other approaches – including non-conditional adversarial nets.
我们提出的条件对抗网结果与其他一些基于网络的方法不相上下,但比其他几种方法(包括非条件对抗网)更胜一筹。 - We present these results more as a proof-of-concept than as demonstration of efficacy, and believe that with further exploration of hyper-parameter space and architecture that the conditional model should match or exceed the non-conditional results.
我们认为,随着对超参数空间和结构的进一步探索,条件模型应能达到或超过非条件模型的结果。
Fig 2 shows some of the generated samples. Each row is conditioned on one label and each column is a different generated sample.
图 2 显示了一些生成的样本。每一行以一个标签为条件,每一列是不同的生成样本。

5.2 Multimodal(多模式)
- Photo sites such as Flickr are a rich source of labeled data in the form of images and their associated user-generated metadata (UGM) — in particular user-tags.
Flickr 等图片网站以图片及其相关的用户生成元数据(UGM)–尤其是用户标签–的形式提供了丰富的标签数据源。 - User-generated metadata differ from more ‘canonical’ image labelling schems in that they are typically more descriptive, and are semantically much closer to how humans describe images with natural language rather than just identifying the objects present in an image.
用户生成的元数据与更多的 "标准 "图像标签模式不同,它们通常描述性更强,在语义上更接近人类用自然语言描述图像的方式,而不仅仅是识别图像中的物体。 - Another aspect of UGM is that synoymy is prevalent and different users may use different vocabulary to describe the same concepts — consequently, having an efficient way to normalize these labels becomes important.
UGM 的另一个特点是同义现象普遍存在,不同的用户可能会使用不同的词汇来描述相同的概念–因此,有一种有效的方法来规范这些标签就变得非常重要。 - Conceptual word embeddings can be very useful here since related concepts end up being represented by similar vectors.
概念词嵌入在这里非常有用,因为相关的概念最终会由相似的向量来表示。 - In this section we demonstrate automated tagging of images, with multi-label predictions, using conditional adversarial nets to generate a (possibly multi-modal) distribution of tag-vectors conditional on image features.
在本节中,我们将演示利用条件对抗网生成以图像特征为条件的标签向量分布(可能是多模态的),并进行多标签预测的图像自动标记。 - For image features we pre-train a convolutional model similar to the one from on the full ImageNet dataset with 21,000 labels.
针对图像特征,我们预先训练了一个卷积模型,该模型类似于在包含 21,000 个标签的完整 ImageNet 数据集上训练的模型。 - We use the output of the last fully connected layer with 4096 units as image representations.
我们使用最后一个全连接层 4096 个单元的输出作为图像表示。 - For the world representation we first gather a corpus of text from concatenation of user-tags, titles and descriptions from YFCC100M 2 dataset metadata.
我们首先从 YFCC100M 2 数据集元数据中的用户标签、标题和描述的连接中收集了一个文本语料库。 - After pre-processing and cleaning of the text we trained a skip-gram model with word vector size of 200.
在对文本进行预处理和清理后,我们训练了一个词向量大小为 200 的跳格模型。 - And we omitted any word appearing less than 200 times from the vocabulary, thereby ending up with a dictionary of size 247465.
我们省略了词汇中出现次数少于 200 次的单词,因此字典的大小为 247465。 - We keep the convolutional model and the language model fixed during training of the adversarial net.
在对抗网的训练过程中,我们保持卷积模型和语言模型固定不变。 - And leave the experiments when we even backpropagate through these models as future work.
至于如何通过这些模型进行反向传播的实验,则留待今后研究。 - For our experiments we use MIR Flickr 25,000 dataset, and extract the image and tags features using the convolutional model and language model we described above.
在实验中,我们使用了 MIR Flickr 25,000 数据集,并使用上述卷积模型和语言模型提取了图像和标签特征。 - Images without any tag were omitted from our experiments and annotations were treated as extra tags.
没有任何标签的图像在我们的实验中被省略,而注释则被视为额外的标签。 - The first 150,000 examples were used as training set. Images with multiple tags were repeated inside the training set once for each associated tag.
前 150,000 个例子被用作训练集。带有多个标签的图像在训练集中重复出现,每个相关标签重复出现一次。 - For evaluation, we generate 100 samples for each image and find top 20 closest words using cosine similarity of vector representation of the words in the vocabulary to each sample.
为了进行评估,我们为每幅图像生成 100 个样本,并使用词汇表中单词向量表示与每个样本的余弦相似度找出最接近的前 20 个单词。 - Then we select the top 10 most common words among all 100 samples.
然后,我们从所有 100 个样本中选出最常见的前 10 个词。 - Table 4.2 shows some samples of the user assigned tags and annotations along with the generated tags.
表 4.2 显示了用户指定的标签和注释以及生成的标签的一些示例。 - The best working model’s generator receives Gaussian noise of size 100 as noise prior and maps it
to 500 dimension ReLu layer.
最佳工作模型的生成器接收大小为 100 的高斯噪声作为噪声先验,并将其映射到 500 维 ReLu 层。 - And maps 4096 dimension image feature vector to 2000 dimension ReLu hidden layer.
并将 4096 维图像特征向量映射到 2000 维 ReLu 隐藏层。 - Both of these layers are mapped to a joint representation of 200 dimension linear layer which would output the generated word vectors.
这两个层都被映射到一个联合表示的 200 维线性层,该层将输出生成的单词向量。 - The discriminator is consisted of 500 and 1200 dimension ReLu hidden layers for word vectors and image features respectively and maxout layer with 1000 units and 3 pieces as the join layer which is finally fed to the one single sigmoid unit.
鉴别器由 500 维和 1200 维 ReLu 隐藏层组成,分别用于识别单词向量和图像特征,最大输出层有 1000 个单元和 3 个片段作为连接层,最后馈送到一个单一的 sigmoid 单元。 - The model was trained using stochastic gradient decent with mini-batches of size 100 and initial learning rate of 0.1 which was exponentially decreased down to .000001 with decay factor of 1.00004.
该模型采用随机梯度梯度法进行训练,迷你批次大小为 100,初始学习率为 0.1,学习率以指数方式下降到 0.000001,衰减系数为 1.00004。 - Also momentum was used with initial value of .5 which was increased up to 0.7.
此外,动量的初始值为 0.5,后来增加到 0.7。 - Dropout with probability of 0.5 was applied to both the generator and discriminator.
生成器和判别器均采用概率为 0.5 的 Dropout。 - The hyper-parameters and architectural choices were obtained by cross-validation and a mix of random grid search and manual selection (albeit over a somewhat limited search space.)
超参数和结构选择是通过交叉验证以及随机网格搜索和人工选择(尽管搜索空间有限)相结合的方式获得的。
六、Future Work(今后的工作)
-
The results shown in this paper are extremely preliminary, but they demonstrate the potential of conditional adversarial nets and show promise for interesting and useful applications.
本文所展示的结果是极其初步的,但它们展示了条件对抗网的潜力,并为有趣和有用的应用带来了希望。 -
In future explorations between now and the workshop we expect to present more sophisticated models, as well as a more detailed and thorough analysis of their performance and characteristics.
从现在到研讨会期间的未来探索中,我们希望提出更复杂的模型,并对其性能和特点进行更详细、更透彻的分析。
-
Also, in the current experiments we only use each tag individually.
此外,在目前的实验中,我们只单独使用每个标签。 -
But by using multiple tags at the same time (effectively posing generative problem as one of ‘set generation’) we hope to achieve better results.
但通过同时使用多个标签(实际上将生成问题视为 "集合生成 "问题),我们希望能取得更好的效果。 -
Another obvious direction left for future work is to construct a joint training scheme to learn the language model.
未来工作的另一个明显方向是构建一个联合训练方案来学习语言模型。 -
Works such as has shown that we can learn a language model for suited for the specific task.
等作品表明,我们可以学习适合特定任务的语言模型。

七、Acknowledgments(致谢)
- This project was developed in Pylearn2 framework, and we would like to thank Pylearn2 developers.
本项目采用 Pylearn2 框架开发,在此向 Pylearn2 开发人员表示感谢。 - We also like to thank Ian Goodfellow for helpful discussion during his affiliation at University of Montreal.
我们还要感谢伊恩-古德费洛(Ian Goodfellow)在蒙特利尔大学工作期间与我们进行的有益讨论。 - The authors gratefully acknowledge the support from the Vision & Machine Learning, and Production Engineering teams at Flickr (in alphabetical order: Andrew Stadlen, Arel Cordero, Clayton Mellina, Cyprien Noel, Frank Liu, Gerry Pesavento, Huy Nguyen, Jack Culpepper, John Ko, Pierre Garrigues, Rob Hess, Stacey Svetlichnaya, Tobi Baumgartner, and Ye Lu).
作者衷心感谢 Flickr 的视觉与机器学习团队和生产工程团队(按字母顺序排列: Andrew Stadlen、Arel Cordero、Clayton Mellina、Cyprien Noel、Frank Liu、Gerry Pesavento、Huy Nguyen、Jack Culpepper、John Ko、Pierre Garrigues、Rob Hess、Stacey Svetlichnaya、Tobi Baumgartner 和 Ye Lu)。
八、References(参考文献)
17 articles, references.





