前言:
因为在项目中集成了ElasticSearch,用于某些业务场景的搜素或筛选。这里关于ElasticSearch就不做介绍了,虽然解决了全文搜索的性能问题。但是当出现一些频繁更新的数据放置在ES就有点麻烦了。
这时候,一款能把MySQL数据即时同步到ElasticSearch的工具就显得格外重要了。经过比较筛选我选择了阿里的canal,这里应该就有人会说用Elastic全家桶的Logstash或filebeat不是更好吗!接下来就会介绍我为什么选canal以及最重要的canal的本地搭建(零基础视角)。
对比:
作为增量数据消费,应用与各种场景都有与之对应领域比较好的工具。比如上面的Logstash和filebeat虽都同属于Elastic但也截然不同,更别说flume等等工具。我选择canal的原因是他有适配器,只要是MySQL同步场景,对面是一个能储存的都可以,比如文件,队列,数据仓库,ES等等都可以。而其他的更多的应用场景可能是定时的日志采集,但cannal是通过监听binlog后触发操作,比较没有好坏,只有适合与不适合。
场景:
1. 实时同步MySQL数据到ElasticSearch
2. redis缓存的即时更新
3. 业务上商品订阅降价等等
下载:
1. 地址:
https://github.com/alibaba/canal/releases
2. github上如何下载源码发行包
刚开始打开canal没看到的可能只是工具的源码,但是在windows下需要工具包。源码编译打包对于新手来说还不是时候,所以就介绍一下github等其他版本仓库别人开源的工具类代码如何下载发行包。
(1). 进入github仓库主页,一般是在右上角有一个releases超链接,点击进入就有各迭代版本的发行包介绍和下载资源了。

3. 哪个才是canal服务的工具包?
点击进去可能看到的有如下好几个包,而给我们开发语言(客户端)能提供服务的是deployer,另外几个分别是管控台和适配器等,以后有时间再介绍他们的用途和安装方法。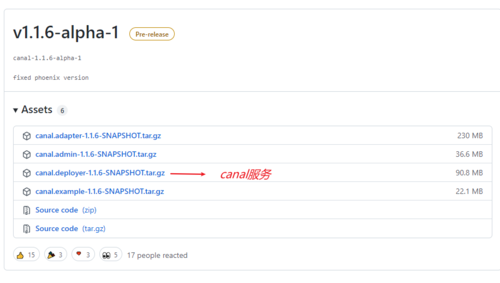
配置:
1. MySQL的binlog开启
因为canal通过伪装成MySQL一个slave,通过dump协议与master通讯,并解析MySQL的binlog文件。canal的工作原理和MySQL的binlog开启方法这里就不做介绍了,网上都比较多。
2. canal实例的主要的几个配置
(1). MySQL账户, conf/example/instance.properties
canal.instance.dbUsername=canal // 数据库账户canal.instance.dbPassword=canal // 数据库密码
(2). 数据库新建上面账户并授权
#创建用户CREATE USER canal IDENTIFIED BY 'canal'; #创建权限GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
(3). canal服务端口账户,conf/canal.properties
# tcp指定的IP, 不填表示0.0.0.0canal.ip =# register ip to zookeepercanal.register.ip =# canal服务端口canal.port = 11111canal.metrics.pull.port = 11112# canal 服务的账号密码,注释表示客户端连接无需账号密码# canal.user = canal# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
下载完canal deployer后,如果只是作为客户端请求测试,需要配置也就是上面两个文件(conf/example/instance.properties 和 conf/canal.properties), 除了上面按照自己的配置,其他的都保持原有参数不变即可。
启动:
windows下启动,打开cmd,进入根目录下的bin,然后运行startup.bat就可以。启动成功与否可以在logs目录的两个日志文件中查看,如果有Error字眼,一般就是配置有问题,可以根据具体报错具体查找原因。


测试:
因为canal是Java开发的,所以测试也采用Java作为客户端打印一下实时解析binlog的结果。不过在跑Java程序前,windows可以通过以下两个命令查看canal启动情况。
telnet 127.0.0.1 11111
netstat -ano | findstr "11111"
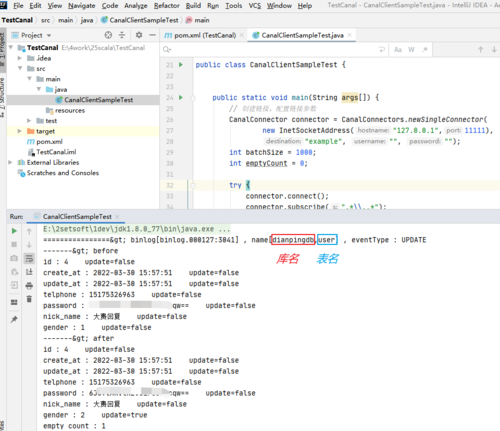
接下来也依然以新手的视角(因为以前都是写PHP,所以看我文件的应该也都是PHPer,所以熟悉的同学们可以复制下面代码测试)创建Java项目,构建Jar包,编写canal客户端,编译运行等等。
1. 打开IntekkiJ IDEA, 创建一个Maven项目。
2. 打开pom.xml添加以下依赖。
<dependencies> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.4</version> </dependency> </dependencies>

3. 打开编辑器右上角的Maven按钮,并按刷新,等待下载依赖。

4. src/main/java 新建一个 Java类文件,粘贴以下代码。
import java.net.InetSocketAddress;import java.util.List;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.protocol.Message;import com.alibaba.otter.canal.protocol.CanalEntry.Column;import com.alibaba.otter.canal.protocol.CanalEntry.Entry;import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;import com.alibaba.otter.canal.protocol.CanalEntry.EventType;import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;import com.alibaba.otter.canal.protocol.CanalEntry.RowData;public class CanalClientTest { public static void main(String args[]) { // 创建链接,这里就需要canal里配置的端口,账号密码,destination默认先example就行
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1",11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0; try {
connector.connect(); // 防止 deserializer failed报错
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120; while (emptyCount < totalEmptyCount) {
connector.subscribe(); Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size(); if (batchId == -1 || size == 0) {
emptyCount++; System.out.println("empty count : " + emptyCount); try { Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
} System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
} private static void printEntry(List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { continue;
} RowChange rowChage = null; try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
} EventType eventType = rowChage.getEventType(); System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType)); for (RowData rowData : rowChage.getRowDatasList()) { if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else { System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList()); System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
} private static void printColumn(List<Column> columns) { for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}5. 右击该文件Run, 开始编译运行,并打开运行台,然后再在数据库里随便找一张表,随便修改以下数据,就可以实时查看变动的信息了。