
在一些系统中有时某张表会出现百万或者千万的数据量,尽管其中使用了索引,查询速度也不一定会很快。这时候可能就需要通过分库,分表,分区来解决这些性能瓶颈。
一. 选择合适的解决方法
1. 分库分表。
分库分表从名字上就明白是需要创建额外的新数据库或新表,可以建在其他的机器上也可以是和当前数据库同一台机器。在优化查询上可能需要买新机器或者要修改逻辑代码了。比如一张user表,当数据超过10W,就可以创建新的user表,假设是user2。通过接收的UID,和分组10W(假定),取模就是对应的user表名的索引数字。
2. 分区。
分区这里是指表分区,mysql数据库管理系统提供的表功能,分区后逻辑上是同一张表,物理上数据存储是分开的。能否优化查询还取决于在查询中是否使用到了分区字段,这个就和索引的使用有点类似,但是好处就是这个不像分库分表,可以几乎不修改业务逻辑代码就可以提升速度。下面再总结一下mysql数据保存格式和innodb,myisam。
2.1. innodb存储引擎。
innodb,支持事务处理,外来键,在查询方面要慢于myisam。对并发友好,支持行锁和表锁,行锁的形成要看查询条件。有共享空间结构和独立空间结构,保存的格式有frm和ibddata1(共享结构),ibd(独立结构)。
2.1.1.共享空间结构。
共享结构为innodb默认的结构,除了frm保存innodb表结构外,整个数据库所有表的索引和数据源都保存在ibdata中。可以通过在mysql-ini中添加 innodb_file_per_table=1设置为独立空间结构。
2.1.2.独立空间结构。
独立空间结构就是每个对应的表保存对应的数据源和索引在一个后缀为ibd的文件中,表结构同样也保存在frm中。
2.2. myisam存储引擎
myisam是mysql默认存储引擎,不支持事务,但是会对I/O进行平均分配,相较于innodb查询速度要快,对并发不友好,支持表锁。格式frm同样也是表结构,myd为表的数据源,myi表的索引储存(所以一张表的索引不是越多越好,因为在添加和修改数据时也需要对索引库进行修改和添加)
二. 表分区的几种分区类型。
1. RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
2. LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
3. HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
4. KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
具体介绍可以搜索以下"mysql表分区的分区类型"。
三. 表分区的创建。
par格式为保存的是分区的规则,ibd就是分别为每一块分区后的数据源,以下为innodb分区,myisam的是有多个myd文件同时也存在par。
1. 新建表时添加分区。
比如以下创建一张employees 的表,并创建了list类型的4个分区,以store_id 字段为分区字段。
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT)PARTITION BY LIST(store_id) PARTITION pNorth VALUES IN (3,5,6,9,17), PARTITION pEast VALUES IN (1,2,10,11,19,20), PARTITION pWest VALUES IN (4,12,13,14,18), PARTITION pCentral VALUES IN (7,8,15,16) );
2. 存在的表添加分区
将原来的数据以当前的分区规则对原来数据进行规整,以下是对ztest表添加range类型的3个分区,以id字段为分区字段。
alter table rm_ztest partition by RANGE (id) ( PARTITION p0 VALUES LESS THAN (948), PARTITION p1 VALUES LESS THAN (960), PARTITION p3 VALUES LESS THAN MAXVALUE )
3. navicat for mysql工具添加或创建。
平时我使用上面的工具比较多,所以他也有一个添加分区的功能。"新建表"或者是"设计表",点击"选项",“分割区”就可以进入分区的创建了。

四. 分区查询的实验结果。
我就拿了一张几百万数据的表备份了副本,其中一张创建了分区,并使用id分区字段进行查询。
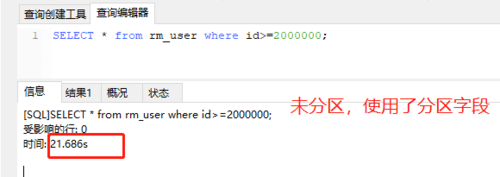

从上面两张截图可以看出使用了分区的查询速度要比未使用分区快差不多1倍,但是如果不使用id为查询条件或没有使用到,速度二者是一样的,甚至有时分区过的还要慢于未分区的,所以在使用上还需结合当前业务做合理的选择。
explain partitions select * from table_name …… 可以查看当前查询是否使用了分区,分区使用的是哪几个等等信息。





