
大家好,我是小彭。
今天是五一假期的第二天,打周赛的人数比前一天的双周赛多了,难道大家都只玩一天吗?这场周赛是 LeetCode 第 343 场单周赛,如果不考虑第一题摆烂的翻译,整体题目质量还是很不错哒。
周赛概览
Q1. 保龄球游戏的获胜者(Easy)
标签:数组、模拟、计数
Q2. 找出叠涂元素(Medium)
标签:矩阵、散列表、计数
Q3. 前往目标的最小代价(Medium)
标签:最短路、Dijkstra、最小堆
Q4. 字典序最小的美丽字符串(Hard)
标签:贪心、构造
Q1. 保龄球游戏的获胜者(Easy)
https://leetcode.cn/problems/determine-the-winner-of-a-bowling-game/
题目描述
给你两个下标从 0 开始的整数数组 player1 和 player2 ,分别表示玩家 1 和玩家 2 击中的瓶数。
保龄球比赛由 n 轮组成,每轮的瓶数恰好为 10 。
假设玩家在第 i 轮中击中 xi 个瓶子。玩家第 i 轮的价值为:
- 如果玩家在前两轮中击中了
10个瓶子,则为2xi。 - 否则,为
xi。
玩家的得分是其 n 轮价值的总和。
返回
- 如果玩家 1 的得分高于玩家 2 的得分,则为
1; - 如果玩家 2 的得分高于玩家 1 的得分,则为
2; - 如果平局,则为
0。
示例 1:
输入:player1 = [4,10,7,9], player2 = [6,5,2,3]
输出:1
解释:player1 的得分是 4 + 10 + 2*7 + 2*9 = 46 。
player2 的得分是 6 + 5 + 2 + 3 = 16 。
player1 的得分高于 player2 的得分,所以 play1 在比赛中获胜,答案为 1 。
示例 2:
输入:player1 = [3,5,7,6], player2 = [8,10,10,2]
输出:2
解释:player1 的得分是 3 + 5 + 7 + 6 = 21 。
player2 的得分是 8 + 10 + 2*10 + 2*2 = 42 。
player2 的得分高于 player1 的得分,所以 play2 在比赛中获胜,答案为 2 。
示例 3:
输入:player1 = [2,3], player2 = [4,1]
输出:0
解释:player1 的得分是 2 + 3 = 5 。
player2 的得分是 4 + 1 = 5 。
player1 的得分等于 player2 的得分,所以这一场比赛平局,答案为 0 。
提示:
n == player1.length == player2.length1 <= n <= 10000 <= player1[i], player2[i] <= 10
题解(模拟)
简单模拟题,但题目描述的中文翻译有歧义,而且不能根据示例区分出来:
- 理解 1:只要最开始的两轮中击中了 10 个瓶子,那么后续得分加倍;
- 理解 2:任意轮的前两轮中击中了 10 个瓶子,那么该轮得分加倍。
按照理解 2 模拟即可:
class Solution {
fun isWinner(player1: IntArray, player2: IntArray): Int {
var cnt1 = 0
var cnt2 = 0
for (i in player1.indices) {
val mul1 = player1.slice(Math.max(0, i - 2) until i).any { it == 10 }
val mul2 = player2.slice(Math.max(0, i - 2) until i).any { it == 10 }
cnt1 += if (mul1) 2 * player1[i] else player1[i]
cnt2 += if (mul2) 2 * player2[i] else player2[i]
}
return if (cnt1 == cnt2) 0 else if (cnt1 > cnt2) 1 else 2
}
}
复杂度分析:
- 时间复杂度:O(n)O(n)O(n) 其中 n 是 player1 数组的长度;
- 空间复杂度:O(1)O(1)O(1) 仅使用常量级别空间。
Q2. 找出叠涂元素(Medium)
https://leetcode.cn/problems/first-completely-painted-row-or-column/
题目描述
给你一个下标从 0 开始的整数数组 arr 和一个 m x n 的整数 矩阵 mat 。arr 和 mat 都包含范围 [1,m * n] 内的 所有 整数。
从下标 0 开始遍历 arr 中的每个下标 i ,并将包含整数 arr[i] 的 mat 单元格涂色。
请你找出 arr 中在 mat 的某一行或某一列上都被涂色且下标最小的元素,并返回其下标 i 。
示例 1:
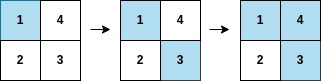
输入:arr = [1,3,4,2], mat = [[1,4],[2,3]]
输出:2
解释:遍历如上图所示,arr[2] 在矩阵中的第一行或第二列上都被涂色。
示例 2:
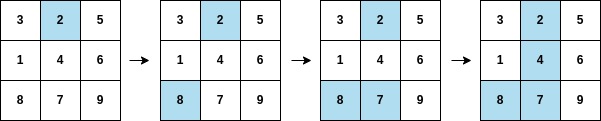
输入:arr = [2,8,7,4,1,3,5,6,9], mat = [[3,2,5],[1,4,6],[8,7,9]]
输出:3
解释:遍历如上图所示,arr[3] 在矩阵中的第二列上都被涂色。
提示:
m == mat.lengthn = mat[i].lengtharr.length == m * n1 <= m, n <= 1051 <= m * n <= 1051 <= arr[i], mat[r][c] <= m * narr中的所有整数 互不相同mat中的所有整数 互不相同
问题结构化
1、概括问题目标
计算涂满一行或一列时的最小下标。
2、观察数据特征
arr 数组和 mat 矩阵中的所有整数都没有重复数。
3、分析问题要件
- 涂色:使用 arr 数组对 mat 矩阵涂色;
- 终止条件:当存在一行或一列被涂满时,返回当前的 arr 数组下标。
至此,程序整体框架确定:
for (数字 in arr 数组) {
涂色
if (涂满一行或一列) 返回索引
}
return -1 // 问题一定有解
4、提高抽象程度
- 查找:对 mat 矩阵中的相同数字的单元格涂色时,需要查找数字在矩阵中的位置:
- 计数:结合「无重复数」的数据特征,判断是否存在一行或一列被涂满时,就是判断一行或一列中被涂色的计数是否达到行数或列数。
5、具体化解决手段
如何查找数字的位置?
- 手段 1(暴力枚举):枚举 mat 矩阵,直到匹配目标数字时停止;
- 手段 2(散列表):结合「无重复数」的数据特征,可以预处理 mat 矩阵获得数字和位置的映射关系,在涂色时以 O(1) 时间复杂度定位涂色位置。
如何判断达到终止条件?
- 手段 1(暴力枚举):枚举 mat 矩阵的行列,当一行或一列的涂色个数达到行数或列数时停止;
- 手段 2(计数数组):记录每一行和每一列的涂色计数,当计数达到行数或列数时,说明达到终止条件。
题解(散列表 + 计数)
题目的关键信息是「无重复数」,根据问题分析模拟即可:
class Solution {
fun firstCompleteIndex(arr: IntArray, mat: Array<IntArray>): Int {
val n = mat.size
val m = mat[0].size
// 计数数组
val rows = IntArray(n)
val columns = IntArray(m)
// 散列表
val hashMap = HashMap<Int, IntArray>()
// 预处理
for (i in 0 until n) {
for (j in 0 until m) {
hashMap[mat[i][j]] = intArrayOf(i, j)
}
}
// 涂色
for ((i, e) in arr.withIndex()) {
val node = hashMap[e]!!
// 判断
if (++rows[node[0]] == m || ++columns[node[1]] == n) return i
}
return -1
}
}
复杂度分析:
- 时间复杂度:O(nm)O(nm)O(nm) 其中 n 和 m 分别为矩阵的行数和列数,预处理和涂色分别对每个元素访问 1 次;
- 空间复杂度:O(nm)O(nm)O(nm) 散列表和计数数组空间。
Q3. 前往目标的最小代价(Medium)
https://leetcode.cn/problems/minimum-cost-of-a-path-with-special-roads/
题目描述
给你一个数组 start ,其中 start = [startX, startY] 表示你的初始位置位于二维空间上的 (startX, startY) 。另给你一个数组 target ,其中 target = [targetX, targetY] 表示你的目标位置 (targetX, targetY) 。
从位置 (x1, y1) 到空间中任一其他位置 (x2, y2) 的代价是 |x2 - x1| + |y2 - y1| 。
给你一个二维数组 specialRoads ,表示空间中存在的一些特殊路径。其中 specialRoads[i] = [x1i, y1i, x2i, y2i, costi] 表示第 i 条特殊路径可以从 (x1i, y1i) 到 (x2i, y2i) ,但成本等于 costi 。你可以使用每条特殊路径任意次数。
返回从 (startX, startY) 到 (targetX, targetY) 所需的最小代价。
示例 1:
输入:start = [1,1], target = [4,5], specialRoads = [[1,2,3,3,2],[3,4,4,5,1]]
输出:5
解释:从 (1,1) 到 (4,5) 的最优路径如下:
- (1,1) -> (1,2) ,移动的代价是 |1 - 1| + |2 - 1| = 1 。
- (1,2) -> (3,3) ,移动使用第一条特殊路径,代价是 2 。
- (3,3) -> (3,4) ,移动的代价是 |3 - 3| + |4 - 3| = 1.
- (3,4) -> (4,5) ,移动使用第二条特殊路径,代价是 1 。
总代价是 1 + 2 + 1 + 1 = 5 。
可以证明无法以小于 5 的代价完成从 (1,1) 到 (4,5) 。
示例 2:
输入:start = [3,2], target = [5,7], specialRoads = [[3,2,3,4,4],[3,3,5,5,5],[3,4,5,6,6]]
输出:7
解释:最优路径是不使用任何特殊路径,直接以 |5 - 3| + |7 - 2| = 7 的代价从初始位置到达目标位置。
提示:
start.length == target.length == 21 <= startX <= targetX <= 1051 <= startY <= targetY <= 1051 <= specialRoads.length <= 200specialRoads[i].length == 5startX <= x1i, x2i <= targetXstartY <= y1i, y2i <= targetY1 <= costi <= 105
预备知识 · 最短路算法
这道题是最短路问题,先回顾下几种最短路算法的区别:
- Floyd 算法(多源汇正权最短路)
- 适用于求任意节点之间的最短路,需要三层循环枚举中转点 i、枚举起点 j 和枚举终点 k,时间复杂度最高。
- Bellman Ford 算法(单源负权最短路)
- 在每一轮迭代中,尝试对图上每一条边进行松弛,直到没有松弛操作时结束。
- Dijkstra 算法(单源正权最短路):
- 在每一轮迭代中,使用确定集中最短路长度最小的节点去松弛相邻节点,由于负权边会破坏贪心策略的选择,无法处理负权问题;
- 稀疏图小顶堆的写法更优,稠密图朴素写法更优。
| 最短路算法 | Floyd | Bellman-Ford | Dijkstra | Johnson |
|---|---|---|---|---|
| 最短路类型 | 每对结点之间的最短路 | 单源最短路 | 单源最短路 | 每对结点之间的最短路 |
| 作用于 | 任意图 | 任意图 | 非负权图 | 任意图 |
| 能否检测负环? | 能 | 能 | 不能 | 能 |
| 时间复杂度 | O(n^3) | O(nm) | O(mlgn)最小堆 | O(nmlgm) |
其中 n 是节点数,m 是边数。
问题结构化
1、概括问题目标
计算从 start 到 target 节点的最小代价。
2、观察数据特征
- 数据大小:节点数据范围的上界是 10^5,相比于节点范围,特殊路径最多只有 200 条,特殊路径是稀疏的。
3、分析问题要件
以 start 为起点,target 为终点,在每次操作可以从 from 节点移动到 to 节点,花费的代价是 |x2 - x1| + |y2 - y1|,另外二维平面中有一些特殊路径,花费的代价是特殊的。
4、提高抽象程度
- 曼哈顿距离:花费的代价是 |x2 - x1| + |y2 - y1| 就是两个节点之间的曼哈顿距离;
- 正权边:「从 from 节点移动到 to 节点的代价 x」等价于「从 from 节点到 to 节点的边权为 x」;
- 有向边:由于题目描述特殊路径只能从 (x1, y1) 走到 (x2, y2),因此题目是有向边;
- 是否为决策问题?由于每次操作有多种移动位置选择,因此这是决策问题,准确来说是最短路问题;
- 总结:这是一道图的单源正权有向边的最短路问题。
5、具体化解决方案
如何解决图的单源正权最短路问题?
这道题只需要计算从 start - target 之间的最短路问题,而且边是非负权边,符合 Dijkstra 算法的应用场景。Dijkstra 算法的本质是贪心 + BFS,我们需要将所有节点分为 2 类,在每一轮迭代中,我们从 “候选集” 中选择距离起点最短路长度最小的节点,由于该点不存在更优解,所以可以用该点来 “松弛” 相邻节点。
- 1、确定集:已确定(从起点开始)到当前节点最短路径的节点;
- 2、候选集:未确定(从起点开始)到当前节点最短路径的节点。
需要考虑哪些节点?
这道题没有限制只能走特殊路径,那么是不是二维平面上所有节点都需要考虑在呢?其实需要,结合「三角不等式」观察,我们发现两个点连续走两次曼哈顿距离没有意义,也就是说,目标路径一定是在起点、终点和特殊路径节点中间移动。
- 策略 1:从 from 到 to 走曼哈顿距离;
- 策略 2:先从 from 走到特殊路径起点,走完特殊路径后再走曼哈顿距离;
- 策略 3(没有意义):先从 from 走曼哈顿距离到 x,再从 x 走曼哈顿距离到 to。
如何表示二维节点?
最简单的方法是通过位移将 (x, y) 压缩为一个唯一整数,由于这道题的坐标范围最大到 10^5,所以应该转化到长整型。
val U = 100000L // 数值上界 + 1
压缩:
val key = x * U + y
还原:
val x = (key / U).toInt()
val y = (key % U).toInt()
至此,我们可以使用朴素 Dijkstra 算法模拟问题。
是否有优化空间?
朴素 Dijkstra 的每轮迭代中需要遍历 n 个节点寻找候选集中的最短路长度。事实上,这 n 个节点中有部分是 “确定集”,有部分是远离起点的边缘节点,每一轮都遍历显得没有必要。我们使用小顶堆记录候选集中最近深度的节点。不过,这道题是稠密图,朴素 Dijkstra 优于 Dijkstra + 最小堆。
继续挖掘三角不等式性质:
由于连续走两次曼哈顿距离没有意义,那我们甚至不需要把特殊路径的起点考虑到图中,或者说直接可以使用 specialRoads 数组,而不需要建图的步骤。
6、答疑
- 这道题的数据范围到 10^5,而特殊路径最多只有 200 条,不是应该算稀疏图?
这个观点混淆了稠密图的定义,稠密或稀疏取决于边数相对于节点数的大小。简单来说,在节点数固定的情况下,边数越大则图越稠密。在这道题中,每个节点都存在到其他所有节点的路径,因此不仅是稠密图,甚至是完全图。
题解一(朴素 Dijkstra)
- 使用 Dijkstra 算法解决最短路问题。
class Solution {
fun minimumCost(start: IntArray, target: IntArray, specialRoads: Array<IntArray>): Int {
// 单源正权最短路
val U = 100001L // 数值上界 + 1
val INF = 0x3F3F3F3F
val startL = start[0] * U + start[1]
val targetL = target[0] * U + target[1]
if (startL == targetL) return 0
// 1、节点与最短路长度
val nodes = HashMap<Long, Int>()
// 1.1 特殊路径上的节点
for (road in specialRoads) {
// 过滤无意义的特殊路径(路径花费大于曼哈顿距离)
nodes[road[0] * U + road[1]] = INF
nodes[road[2] * U + road[3]] = INF
}
// 1.2 起点节点与终点节点
nodes[targetL] = INF
nodes[startL] = 0 // 起点可能为终点,如果开头不做特判需要注意顺序
// 2、建有向图(邻接表)<from -> <to -> cost>>
val graph = HashMap<Long, HashMap<Long, Int>>()
// 2.1 节点之间的路径(双向边)
for ((from, _) in nodes) {
graph[from] = HashMap<Long, Int>()
val fromX = (from / U).toInt()
val fromY = (from % U).toInt()
for ((to, _) in nodes) {
if (from == to) continue
val toX = (to / U).toInt()
val toY = (to % U).toInt()
graph[from]!![to] = Math.abs(toX - fromX) + Math.abs(toY - fromY)
}
}
// 2.2 特殊路径(单向边)
for (road in specialRoads) {
val from = road[0] * U + road[1]
val to = road[2] * U + road[3]
graph[from]!![to] = Math.min(graph[from]!!.getOrDefault(to, INF), road[4]) // 特殊路径的花费可能更长
}
// 3、访问标记
val visit = HashSet<Long>()
// 4、朴素 Dijkstra
while (true) {
// 寻找候选集中最短路长度最短的节点
var minNode = -1L
var minDis = -1
for ((to, dis) in nodes) {
if (visit.contains(to)) continue
if (minDis == -1 || dis < minDis) {
minDis = dis
minNode = to
}
}
// println("minNode=$minNode, minDis=$minDis")
// 找到目标点的最短路长度
if (minNode == targetL) return minDis
// 访问标记
visit.add(minNode)
// 松弛相邻节点
for ((to, cost) in graph[minNode]!!) {
// println("to=$to, cost=$cost")
if (minDis + cost < nodes[to]!!) {
nodes[to] = minDis + cost
}
}
}
return -1 // 必然有解
}
}
复杂度分析:
- 时间复杂度:O(n2)O(n^2)O(n2) 其中 n 是 specialRoads 特殊路径数组的长度;
- 空间复杂度:O(n2)O(n^2)O(n2) 图空间 + 标记数组空间。
题解二(Dijkstra 优化)
- 优化:剪去图空间。
class Solution {
fun minimumCost(start: IntArray, target: IntArray, specialRoads: Array<IntArray>): Int {
// 单源正权最短路
val U = 100001L // 数值上界 + 1
val INF = 0x3F3F3F3F
val startL = start[0] * U + start[1]
val targetL = target[0] * U + target[1]
if (startL == targetL) return 0
// 1、节点与最短路长度
val nodes = HashMap<Long, Int>()
// 起点节点与终点节点
nodes[targetL] = INF
nodes[startL] = 0 // 起点可能为终点,如果开头不做特判需要注意顺序
// 2、访问标记
val visit = HashSet<Long>()
// 3、朴素 Dijkstra
while (true) {
// 寻找候选集中最短路长度最短的节点
var minNode = -1L
var minDis = -1
for ((to, dis) in nodes) {
if (visit.contains(to)) continue
if (minDis == -1 || dis < minDis) {
minDis = dis
minNode = to
}
}
// println("minNode=$minNode, minDis=$minDis")
// 找到目标点的最短路长度
if (minNode == targetL) return minDis
// 访问标记
visit.add(minNode)
val minNodeX = (minNode / U).toInt()
val minNodeY = (minNode % U).toInt()
// 1、直接到终点
nodes[targetL] = Math.min(nodes[targetL]!!, minDis + Math.min(nodes[targetL]!!, (target[1] - minNodeY) + (target[0] - minNodeX)))
// 2、先经过特殊路径(minNode -> 特殊路径的起点 -> 特殊路径的终点)
for (road in specialRoads) {
val specialTo = road[2] * U + road[3]
if (specialTo == minNode) continue // 重复路径
val specialDis = minDis + Math.abs(road[0] - minNodeX) + Math.abs(road[1] - minNodeY) + road[4]
if (specialDis < nodes.getOrDefault(specialTo, INF)) {
nodes[specialTo] = specialDis
}
}
}
return -1 // 必然有解
}
}
复杂度分析:
- 时间复杂度:O(n2)O(n^2)O(n2) 其中 n 是 specialRoads 特殊路径数组的长度;
- 空间复杂度:O(n)O(n)O(n) 标记数组空间。
题解三(Dijkstra + 最小堆)
附赠一份 Dijkstra + 最小堆的代码:
class Solution {
fun minimumCost(start: IntArray, target: IntArray, specialRoads: Array<IntArray>): Int {
// 单源正权最短路
val U = 100000L // 数值上界 + 1
val INF = 0x3F3F3F3F
val startL = start[0] * U + start[1]
val targetL = target[0] * U + target[1]
if (startL == targetL) return 0
// 1、节点与最短路长度
val nodes = HashMap<Long, Int>()
// 起点节点与终点节点
nodes[targetL] = INF
nodes[startL] = 0 // 起点可能为终点,如果开头不做特判需要注意顺序
// 2、最小堆
val heap = PriorityQueue<Long>() { l1, l2 ->
nodes.getOrDefault(l1, INF) - nodes.getOrDefault(l2, INF)
}
heap.offer(startL)
heap.offer(targetL)
// 3、Dijkstra
while (!heap.isEmpty()) {
// 候选集中最短路长度最短的节点
val minNode = heap.poll()
val minDis = nodes[minNode]!!
// println("minNode=$minNode, minDis=$minDis")
// 找到目标点的最短路长度
if (minNode == targetL) return minDis
val minNodeX = (minNode / U).toInt()
val minNodeY = (minNode % U).toInt()
// 1、直接到终点
val newDirectToTarget = minDis + Math.min(nodes[targetL]!!, (target[1] - minNodeY) + (target[0] - minNodeX))
if (newDirectToTarget < nodes[targetL]!!) {
nodes[targetL] = newDirectToTarget
heap.offer(targetL)
}
// 2、先经过特殊路径(minNode -> 特殊路径的起点 -> 特殊路径的终点)
for (road in specialRoads) {
val specialTo = road[2] * U + road[3]
if (specialTo == minNode) continue // 重复路径
val specialDis = minDis + Math.abs(road[0] - minNodeX) + Math.abs(road[1] - minNodeY) + road[4]
if (specialDis < nodes.getOrDefault(specialTo, INF)) {
nodes[specialTo] = specialDis
heap.offer(specialTo)
}
}
}
return -1 // 必然有解
}
}
复杂度分析:
- 时间复杂度:KaTeX parse error: Expected 'EOF', got '·' at position 4: O(m·̲lgn) 其中 n 是 specialRoads 特殊路径数组的长度,m 是边数,由于这道题是完全图,所以有 m = n^2;
- 空间复杂度:O(n)O(n)O(n) 标记数组空间。
Q4. 字典序最小的美丽字符串(Hard)
https://leetcode.cn/problems/lexicographically-smallest-beautiful-string/
题目描述
如果一个字符串满足以下条件,则称其为 美丽字符串 :
- 它由英语小写字母表的前
k个字母组成。 - 它不包含任何长度为
2或更长的回文子字符串。
给你一个长度为 n 的美丽字符串 s 和一个正整数 k 。
请你找出并返回一个长度为 n 的美丽字符串,该字符串还满足:在字典序大于 s 的所有美丽字符串中字典序最小。如果不存在这样的字符串,则返回一个空字符串。
对于长度相同的两个字符串 a 和 b ,如果字符串 a 在与字符串 b 不同的第一个位置上的字符字典序更大,则字符串 a 的字典序大于字符串 b 。
- 例如,
"abcd"的字典序比"abcc"更大,因为在不同的第一个位置(第四个字符)上d的字典序大于c。
示例 1:
输入:s = "abcz", k = 26
输出:"abda"
解释:字符串 "abda" 既是美丽字符串,又满足字典序大于 "abcz" 。
可以证明不存在字符串同时满足字典序大于 "abcz"、美丽字符串、字典序小于 "abda" 这三个条件。
示例 2:
输入:s = "dc", k = 4
输出:""
解释:可以证明,不存在既是美丽字符串,又字典序大于 "dc" 的字符串。
提示:
1 <= n == s.length <= 1054 <= k <= 26s是一个美丽字符串
问题结构化
1、概括问题目标
构造一个满足条件的目标字符串,命名为「美丽字符串」。
2、分析问题要件
- 字符集:题目要求目标字符串仅能使用小写字母表的前 k 个字母,例如 k = 4 只能使用 {a, b, c, d};
- 美丽字符串(限制回文):题目要求目标字符串不包含长度大于 1 的回文子串;
- 字典序更大:题目要求目标字符串的字典序大于字符串 s;
- 字典序最小:题目要求返回字典序最小的方案;
3、观察数据特征
- 数据量:数据量的上界是 10^5,这要求算法的时间复杂度不能高于 O(n^2);
- 输入字符串 s 本身就是「美丽字符串」。
4、观察测试用例
以 s = “abcz”, k = 26 为例:
- 修改 ‘z’:无法修改 ’z’ 获得字典序更高的字母;
- 修改 ‘c’:可以修改 ‘c’ 为 ’d’ 得到 “abdz”,且构成「美丽字符串」;
- 修改 ‘a’ 或 ’b’:也可以构造「美丽字符串」,但字典序不会优于 “abdz”。
5、提高抽象程度
- 权重:字典序的规则中,字符串越靠前的位置对排序的影响权重越大,例如序列 ”ba“ 的字典序大于 ”az“;
- 提升:为了构造字典序更大的「美丽字符串」,我们需要将字符串中的某个字母修改为字母序更大的字母,例如将 ‘a’ 提升到 ‘b’ 或 ‘z’;
- 下一个排列:题目要求目标字符串的字典序大于字符串 s,又是所有方案中字典序最小的,问题模型类似经典题目「31. 下一个排列」,可以借鉴;
- 是否为决策问题:由于每次提升操作有多种位置选择,因此这是个决策问题,准确来说是一个构造问题。
- 总结:这是一个构造问题,要求构造满足条件的「下一个美丽字符串」。
6、具体化解决手段
如何构造满足条件的「下一个美丽字符串」?
由于题目要求构造字典序最小的方案,那么将 s[i] 提升为字母序更大的下一个字母是最优的,例如将 ’a’ 提升到 ‘b’ 优于提升到 ‘z’。除非在 s[i] 已经是字典序最大的字母 ‘z’ 时,我们需要提升它的前一个字母 s[i - 1],例如将 ”az“ 提升为 ”bz“ 优于 “cz”。
构造「下一个美丽字符串」需要提升字母序,那么如何决策替换策略?
由于字符串中越靠前的位置的权重越高,容易想到的贪心策略是从后往前提升字符。如果提升 s[n - 1] 能够构造「美丽字符串」,那么直接提升 s[n - 1] 即可,否则需要提升更靠前的 s[n - 2]。
当我们确定提升 s[i] 的有效性后,继续向前提升没有意义,而由于 s[i] 的字母序本身已经更大了,且 s[i] 的权重在 [i, n) 区间里是最高的,因此后面不管怎么填字典序都是更大的。那么,为了获得字典序最小的「下一个美丽字符串」,我们可以贪心地将后续字符降低到字母序最低的字母,例如 ”abcz“ 提升到 ”abdz” 后,将 ‘z’ 降低到 ‘a’。
这个思考过程,与「下一个排列」问题是比较相似的。在「下一个排列」问题中,我们交换尽可能靠后的一个正序对,由于剩下的序列不管怎么填都是更大的排列,所以我们直接对后续字母做正序排列可以得到最小的字典序。
如何验证提升的有效性(提升字母序后会可能引入新的回文信息)?
在「观察数据特征」中得知,输入字符串 s 本身就是「美丽字符串」,而且我们是从后向前提升字符,那么提升 s[i] 只可能构造出长度为 2 或长度为 3 的回文子串,我们需要以 i 为中心向左右扩展,验证是否有回文串信息。结合上一个问题,由于我们在提升 s[i] 后还需要降低后序位置的字母序,所以我们只需要向左边扩展验证有效性。
至此,我们可以确定整体框架,分为 2 个阶段:
阶段一:
提升 s[n - 1]
while (i 从后往前遍历) {
for (c in s[i] + 1 until 'a' + k) { // 枚举字符集
if (存在回文信息) continue
s[i] = c // 确定有效性
// 记录下标 i
}
// 无法提升 s[i],尝试提升 s[i - 1]
}
阶段二:
// 将 [i + 1, n) 降低为最小字符
for(j in i + 1 until n) {
for (c in 'a' until 'a' + k) { // 枚举字符集
if (存在回文信息)continue
s[j] = c
break
}
}
答疑:
- 为什么阶段二没有处理无法构造的情况?
由于题目提示 k 的取值范围是大于等于 4 的,也就是字符集的大小最小为 4,而验证「有效性」只需要观察位置 i 的前两个位置。那么在长度为 3 的子区间 [i-2, i] 中,我们总能够从大小为 4 的字符集中,选择出一个不会构造出回文信息的子串。因此,阶段二是必然可构造的。甚至来说,题目将 k 的取值范围修改到 [3, 26],我们的算法也是成立的。
题解(贪心)
class Solution {
fun smallestBeautifulString(s: String, k: Int): String {
val n = s.length
val U = 'a' + k
val sArray = s.toCharArray()
var pos = -1
outer@ for (i in n - 1 downTo 0) {
// 尝试提升字母序
for (c in sArray[i] + 1 until U) {
// 验证有效性(只需要验证左边)
if ((i > 0 && c == sArray[i - 1]) || (i > 1 && c == sArray[i - 2])) continue
sArray[i] = c
pos = i
break@outer
}
}
// 无法构造
if (pos < 0) return ""
for (i in pos + 1 until n) {
for (c in 'a' until U) {
// 验证有效性(只需要验证左边)
if ((i > 0 && c == sArray[i - 1]) || (i > 1 && c == sArray[i - 2])) continue
sArray[i] = c
break
}
}
return String(sArray)
}
}
复杂度分析:
- 时间复杂度:O(n)O(n)O(n) 其中 n 为字符串 s 的长度,每个位置最多被访问 2 次,而每个位置的提升操作最多执行 2 次,降低操作最多执行 2 次;
- 空间复杂度:O(1)O(1)O(1) 不考虑结果数组。





