
前言
大家好,我是小彭。
[在上一篇文章里],我们聊到了 CPU 的三级缓存结构,提到 CPU 缓存就一定会聊到 CPU 的缓存一致性问题。那么,什么是缓存一致性问题,CPU Cache 的读取和写入过程是如何执行的,MESI 缓存一致性协议又是什么?今天我们将围绕这些问题展开。
学习路线图:
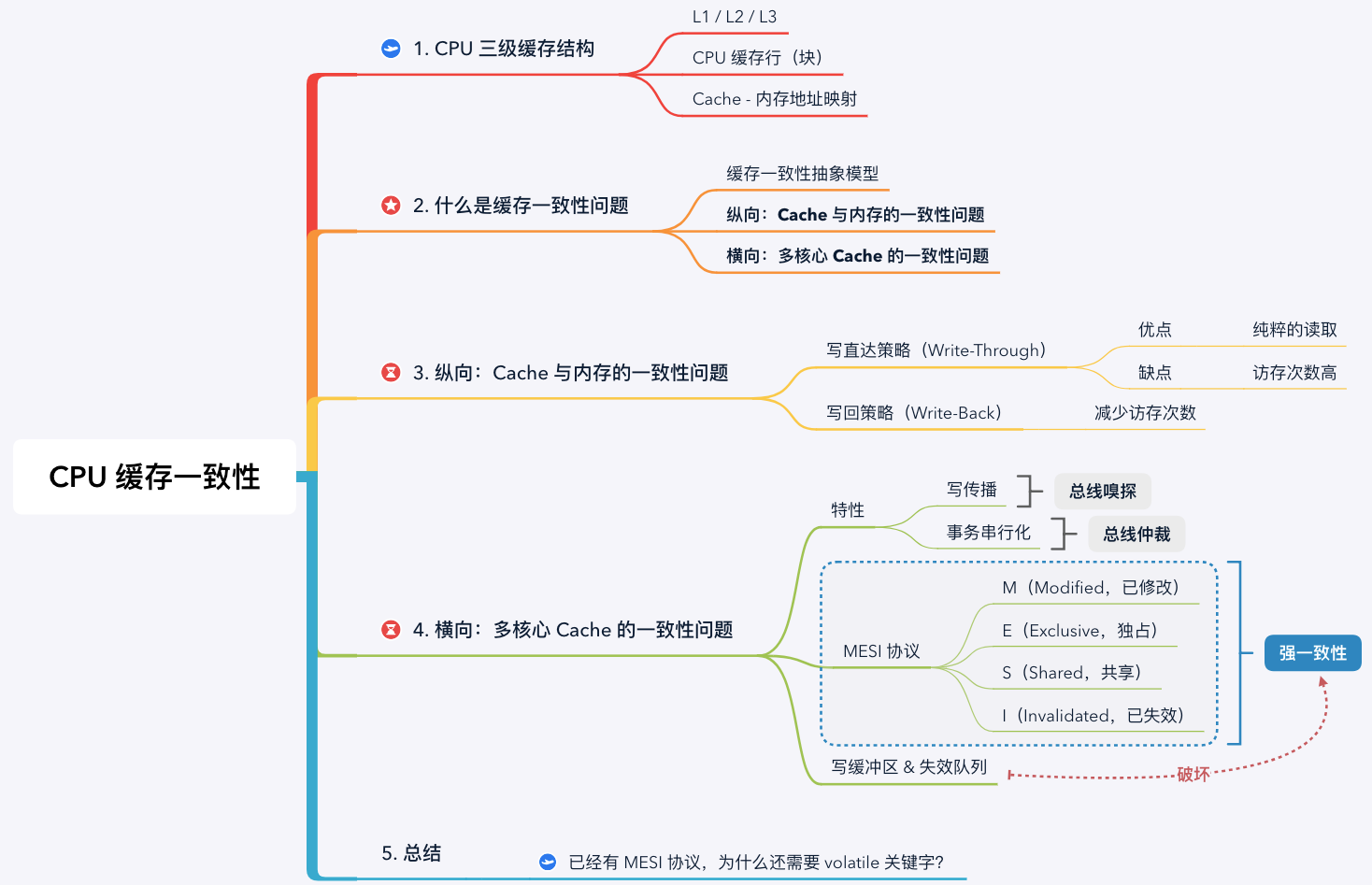
1. 回顾 CPU 三级缓存结构
由于 CPU 和内存的速度差距太大,为了拉平两者的速度差,现代计算机会在两者之间插入一块速度比内存更快的高速缓存,CPU 缓存是分级的,有 L1 / L2 / L3 三级缓存。
由于单核 CPU 的性能遇到瓶颈(主频与功耗的矛盾),芯片厂商开始在 CPU 芯片里集成多个 CPU 核心,每个核心有各自的 L1 / L2 缓存。 其中 L1 / L2 缓存是核心独占的,而 L3 缓存是多核心共享的。
基于局部性原理的应用,CPU Cache 在读取内存数据时,每次不会只读一个字或一个字节,而是一块块地读取,每一小块数据也叫 CPU 缓存行(CPU Cache Line)。 为了标识 Cache 块中的数据是否已经从内存中读取,需要在 Cache 块上增加一个 有效位(Valid bit)。
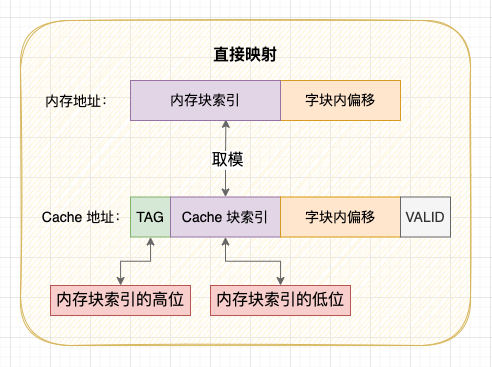
无论对 Cache 数据检查、读取还是写入,CPU 都需要知道访问的内存数据映射在 Cache 上的哪个位置,这就是 Cache - 内存地址映射问题,映射方案有直接映射、全相联映射和组相联映射 3 种方案。当缓存块满或者内存块映射的缓存块位置被占用时,就需要使用 替换策略 将旧的 Cache 块换出腾出空闲位置。
Cache - 内存的直接映射方案
基于以上结构,就会存在缓存一致性问题。
2. 什么是 CPU 缓存一致性问题?
CPU 缓存一致性(Cache Coherence)问题指 CPU Cache 与内存的不一致性问题。事实上, 在分析缓存一致性问题时,考虑 L1 / L2 / L3 的多级缓存没有意义, 所以我们提出缓存一致性抽象模型,只考虑核心独占的缓存。
CPU 三级缓存与抽象模型
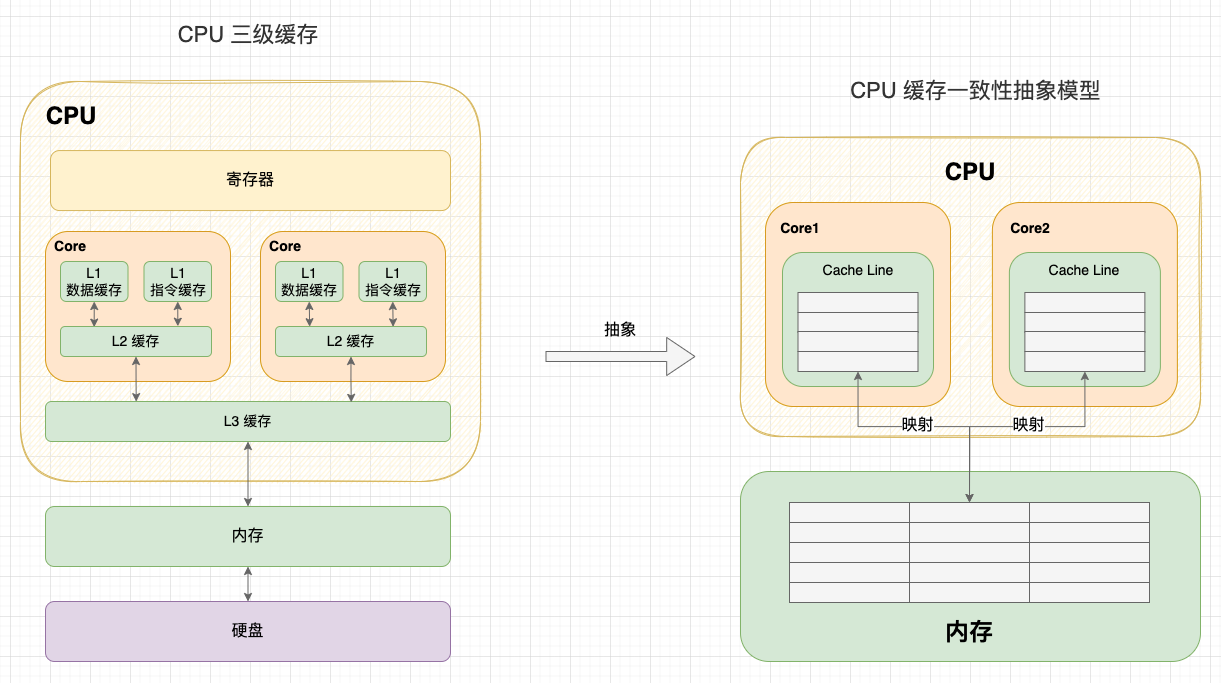
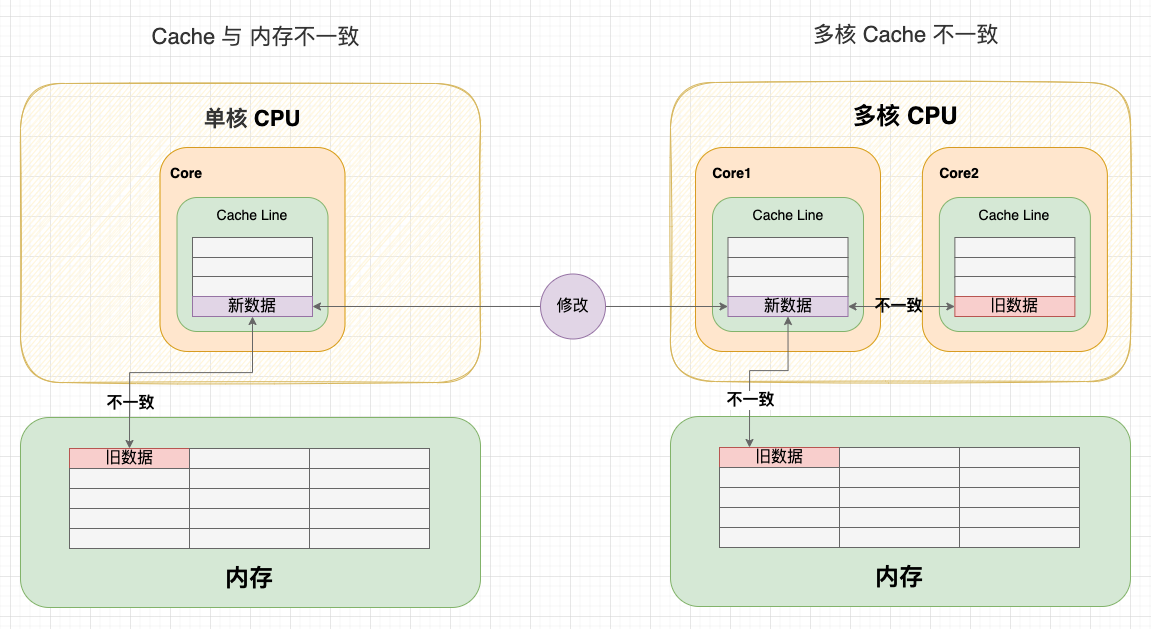
在单核 CPU 中,只需要考虑 Cache 与内存的一致性。但是在多核 CPU 中,由于每个核心都有一份独占的 Cache,就会存在一个核心修改数据后,两个核心 Cache 数据不一致的问题。因此,我认为 CPU 的缓存一致性问题应该从 2 个维度理解:
- 纵向:Cache 与内存的一致性问题: 在修改 Cache 数据后,如何同步回内存?
- 横向:多核心 Cache 的一致性问题: 在一个核心修改 Cache 数据后,如何同步给其他核心 Cache?
接下来,我们将围绕这两个问题展开。
3. 纵向:Cache 与内存的一致性问题
3.1 CPU Cache 的读取过程
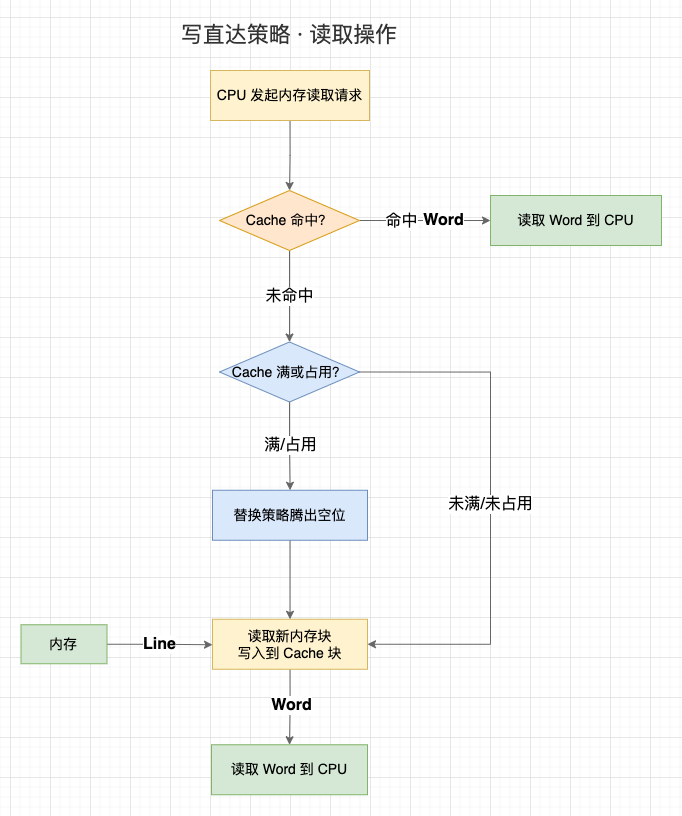
这一节,我们先来讨论 Cache 的读取过程。事实上,Cache 的读取过程会受到 Cache 的写入策略影响,我们暂且用相对简单的 “写直达策略” 的读取过程:
-
1、CPU 在访问内存地址时,会先检查该地址的数据是否已经加载到 Cache 中(Valid bit 是否为 1);
-
2、如果数据在 Cache 中,则直接读取 Cache 块上的字到 CPU 中;
-
3、如果数据不在 Cache 中:
- 3.1 如果 Cache 已装满或者 Cache 块被占用,先执行替换策略,腾出空闲位置;
- 3.2 访问内存地址,并将内存地址所处的整个内存块写入到映射的 Cache 块中;
- 3.3 读取 Cache 块上的字到 CPU 中。
读取过程(以写直达策略)
但是,CPU 不仅会读取 Cache 数据,还会修改 Cache 数据,这就是第 1 个一致性问题 —— 在修改 Cache 数据后,如何同步回内存?有 2 种写入策略:
3.2 写直达策略(Write-Through)
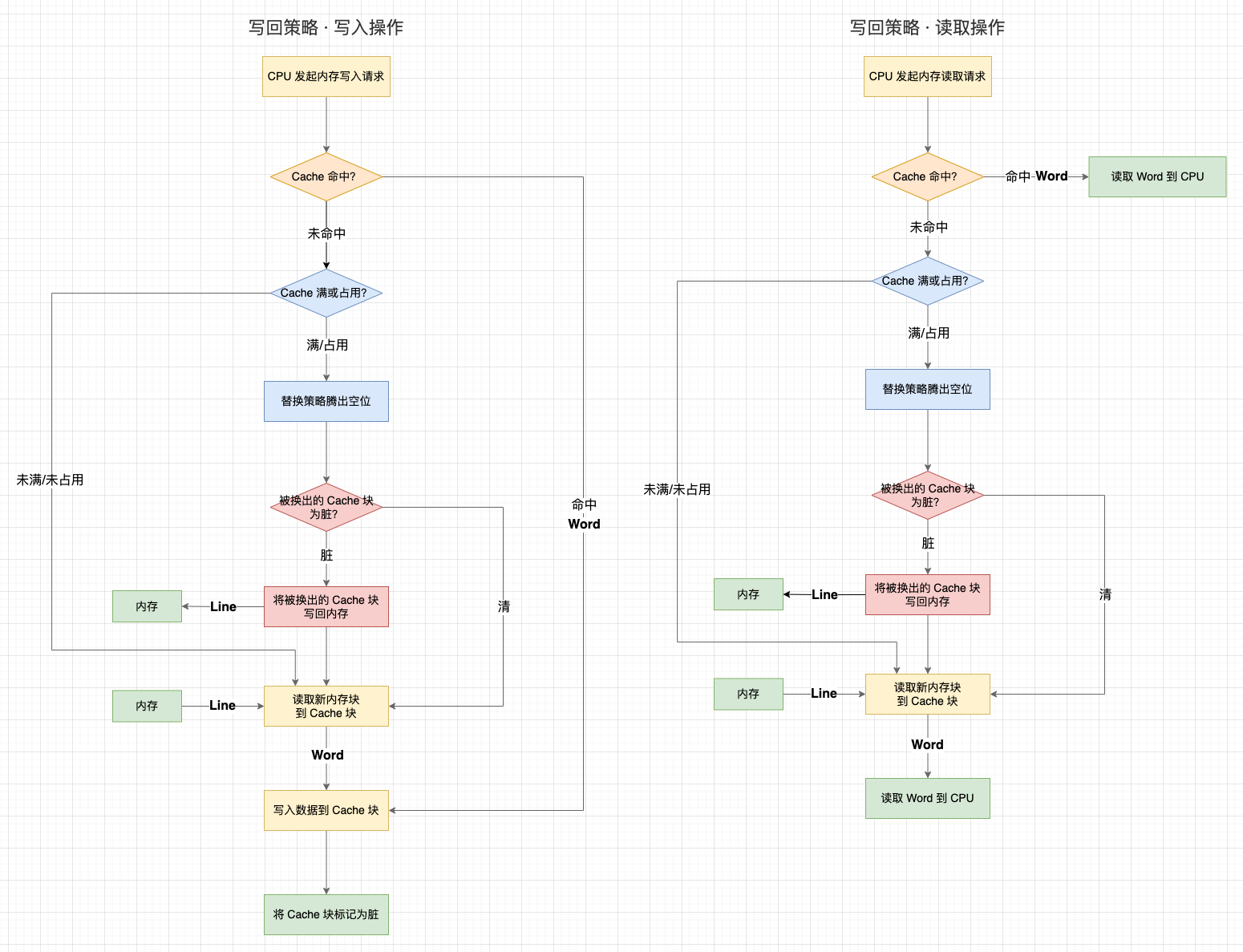
写直达策略是解决 Cache 与内存一致性最简单直接的方式: 在每次写入操作中,同时修改 Cache 数据和内存数据,始终保持 Cache 数据和内存数据一致:
- 1、如果数据不在 Cache 中,则直接将数据写入内存;
- 2、如果数据已经加载到 Cache 中,则不仅要将数据写入 Cache,还要将数据写入内存。
写直达的优点和缺点都很明显:
- 优点: 每次读取操作就是纯粹的读取,不涉及对内存的写入操作,读取速度更快;
- 缺点: 每次写入操作都需要同时写入 Cache 和写入内存,在写入操作上失去了 CPU 高速缓存的价值,需要花费更多时间。
写直达策略

3.3 写回策略(Write-Back)
既然写直达策略在每次写入操作都会写内存,那么有没有什么办法可以减少写回内存的次数呢?这就是写回策略:
-
1、写回策略会在每个 Cache 块上增加一个 “脏(Dirty)” 标记位 ,当一个 Cache 被标记为脏时,说明它的数据与内存数据是不一致的;
-
2、在写入操作时,我们只需要修改 Cache 块并将其标记为脏,而不需要写入内存;
-
3、那么,什么时候才将脏数据写回内存呢?—— 就发生在 Cache 块被替换出去的时候:
- 3.1 在写入操作中,如果目标内存块不在 Cache 中,需要先将内存块数据读取到 Cache 中。如果替换策略换出的旧 Cache 块是脏的,就会触发一次写回内存操作;
- 3.2 在读取操作中,如果目标内存块不在 Cache 中,且替换策略换出的旧 Cache 块是脏的,就会触发一次写回内存操作;
可以看到,写回策略只有当一个 Cache 数据将被替换出去时判断数据的状态,“清(未修改过,数据与内存一致)” 的 Cache 块不需要写回内存,“脏” 的 Cache 块才需要写回内存。这个策略能够减少写回内存的次数,性能会比写直达更高。当然,写回策略在读取的时候,有可能不是纯粹的读取了,因为还可能会触发一次脏 Cache 块的写入。
这里还有一个设计: 在目标内存块不在 Cache 中时,写直达策略会直接写入内存。而写回策略会先把数据读取到 Cache 中再修改 Cache 数据,这似乎有点多余?其实还是为了减少写回内存的次数。虽然在未命中时会增加一次读取操作,但后续重复的写入都能命中缓存。否则,只要一直不读取数据,写回策略的每次写入操作还是需要写入内存。
写回策略
通过写直达或写回策略,我们已经能够解决 “在修改 Cache 数据后,如何同步回内存” 的问题。接下来,我们来讨论第 2 个缓存一致性问题 —— 在一个核心修改 Cache 数据后,如何同步给其他核心 Cache?
4. 横向:多核心 Cache 的一致性问题
在单核 CPU 中,我们通过写直达策略或写回策略保持了Cache 与内存的一致性。但是在多核 CPU 中,由于每个核心都有一份独占的 Cache,就会存在一个核心修改数据后,两个核心 Cache 不一致的问题。
举个例子:
-
1、Core 1 和 Core 2 读取了同一个内存块的数据,在两个 Core 都缓存了一份内存块的副本。此时,Cache 和内存块是一致的;
-
2、Core 1 执行内存写入操作:
-
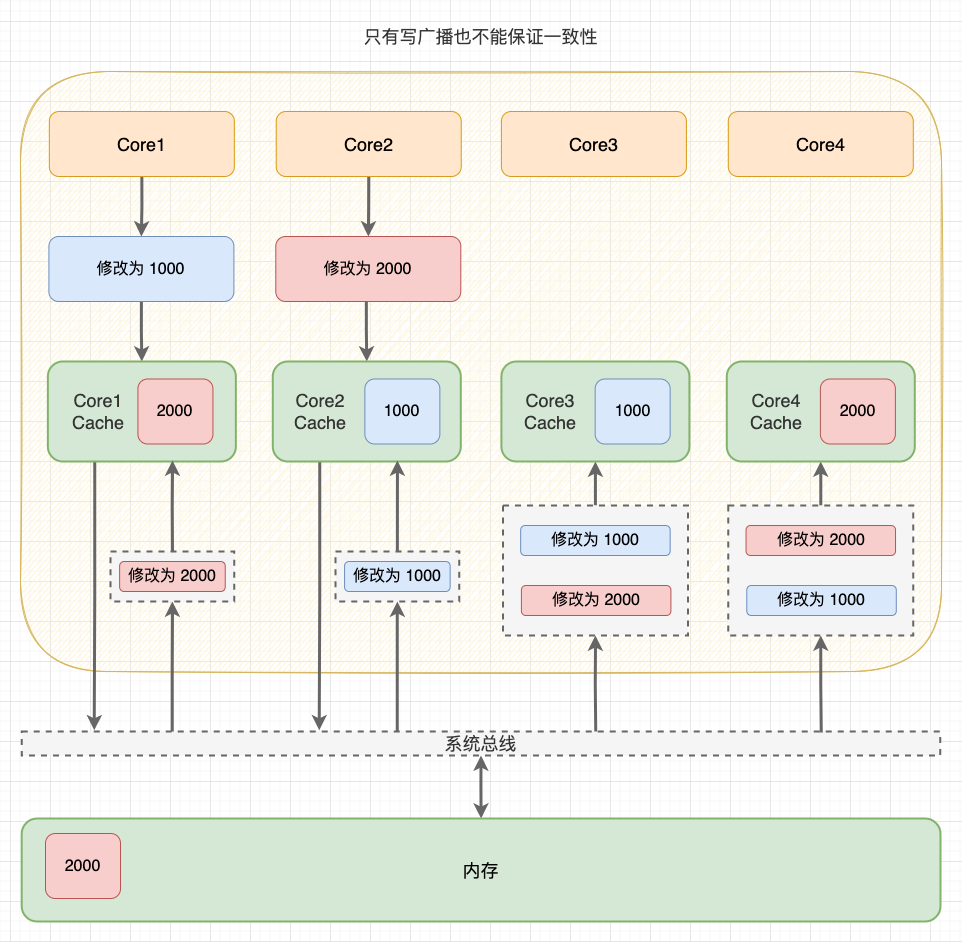
2.1 在写直达策略中,新数据会直接写回内存,此时,Cache 和内存块一致。但由于之前 Core 2 已经读过这块数据,所以 Core 2 缓存的数据还是旧的。此时,Core 1 和 Core 2 不一致;
-
2.2 在写回策略中,新数据会延迟写回内存,此时 Cache 和内存块不一致。不管 Core 2 之前有没有读过这块数据,Core 2 的数据都是旧的。此时,Core 1 和 Core 2 不一致。
-
-
3、由于 Core 2 无法感知到 Core 1 的写入操作,如果继续使用过时的数据,就会出现逻辑问题。
多核 Cache 不一致

可以看到:由于两个核心的工作是独立的,在一个核心上的修改行为不会被其它核心感知到,所以不管 CPU 使用写直达策略还是写回策略,都会出现缓存不一致问题。 所以,我们需要一种机制,将多个核心的工作联合起来,共同保证多个核心下的 Cache 一致性,这就是缓存一致性机制。
4.1 写传播 & 事务串行化
缓存一致性机制需要解决的问题就是 2 点:
-
特性 1 - 写传播(Write Propagation): 每个 CPU 核心的写入操作,需要传播到其他 CPU 核心;
-
特性 2 - 事务串行化(Transaction Serialization): 各个 CPU 核心所有写入操作的顺序,在所有 CPU 核心看起来是一致。
第 1 个特性解决了 “感知” 问题,如果一个核心修改了数据,就需要同步给其它核心,很好理解。但只做到同步还不够,如果各个核心收到的同步信号顺序不一致,那最终的同步结果也会不一致。
举个例子:假如 CPU 有 4 个核心,Core 1 将共享数据修改为 1000,随后 Core 2 将共享数据修改为 2000。在写传播下,“修改为 1000” 和 “修改为 2000” 两个事务会同步到 Core 3 和 Core 4。但是,如果没有事务串行化,不同核心收到的事务顺序可能是不同的,最终数据还是不一致。
非事务串行化
4.2 总线嗅探 & 总线仲裁
写传播和事务串行化在 CPU 中是如何实现的呢?—— 此处隆重请出计算机总线系统。
-
写传播 - 总线嗅探: 总线除了能在一个主模块和一个从模块之间传输数据,还支持一个主模块对多个从模块写入数据,这种操作就是广播。要实现写传播,其实就是将所有的读写操作广播到所有 CPU 核心,而其它 CPU 核心时刻监听总线上的广播,再修改本地的数据;
-
事务串行化 - 总线仲裁: 总线的独占性要求同一时刻最多只有一个主模块占用总线,天然地会将所有核心对内存的读写操作串行化。如果多个核心同时发起总线事务,此时总线仲裁单元会对竞争做出仲裁,未获胜的事务只能等待获胜的事务处理完成后才能执行。
提示: 写传播还有 “基于目录(Directory-base)” 的实现方案。
基于总线嗅探和总线仲裁,现代 CPU 逐渐形成了各种缓存一致性协议,例如 MESI 协议。
4.3 MESI 协议
MESI 协议其实是 CPU Cache 的有限状态机,一共有 4 个状态(MESI 就是状态的首字母):
- M(Modified,已修改): 表明 Cache 块被修改过,但未同步回内存;
- E(Exclusive,独占): 表明 Cache 块被当前核心独占,而其它核心的同一个 Cache 块会失效;
- S(Shared,共享): 表明 Cache 块被多个核心持有且都是有效的;
- I(Invalidated,已失效): 表明 Cache 块的数据是过时的。
在 “独占” 和 “共享” 状态下,Cache 块的数据是 “清” 的,任何读取操作可以直接使用 Cache 数据;
在 “已失效” 和 “已修改” 状态下,Cache 块的数据是 “脏” 的,它们和内存的数据都可能不一致。在读取或写入 “已失效” 数据时,需要先将其它核心 “已修改” 的数据写回内存,再从内存读取;
在 “共享” 和 “已失效” 状态,核心没有获得 Cache 块的独占权(锁)。在修改数据时不能直接修改,而是要先向所有核心广播 RFO(Request For Ownership)请求 ,将其它核心的 Cache 置为 “已失效”,等到获得回应 ACK 后才算获得 Cache 块的独占权。这个独占权这有点类似于开发语言层面的锁概念,在修改资源之前,需要先获取资源的锁;
在 “已修改” 和 “独占” 状态下,核心已经获得了 Cache 块的独占权(锁)。在修改数据时不需要向总线发送广播,能够减轻总线的通信压力。
事实上,完整的 MESI 协议更复杂,但我们没必要记得这么细。我们只需要记住最关键的 2 点:
-
关键 1 - 阻止同时有多个核心修改的共享数据: 当一个 CPU 核心要求修改数据时,会先广播 RFO 请求获得 Cache 块的所有权,并将其它 CPU 核心中对应的 Cache 块置为已失效状态;
-
关键 2 - 延迟回写: 只有在需要的时候才将数据写回内存,当一个 CPU 核心要求访问已失效状态的 Cache 块时,会先要求其它核心先将数据写回内存,再从内存读取。
提示: MESI 协议在 MSI 的基础上增加了 E(独占)状态,以减少只有一份缓存的写操作造成的总线通信。
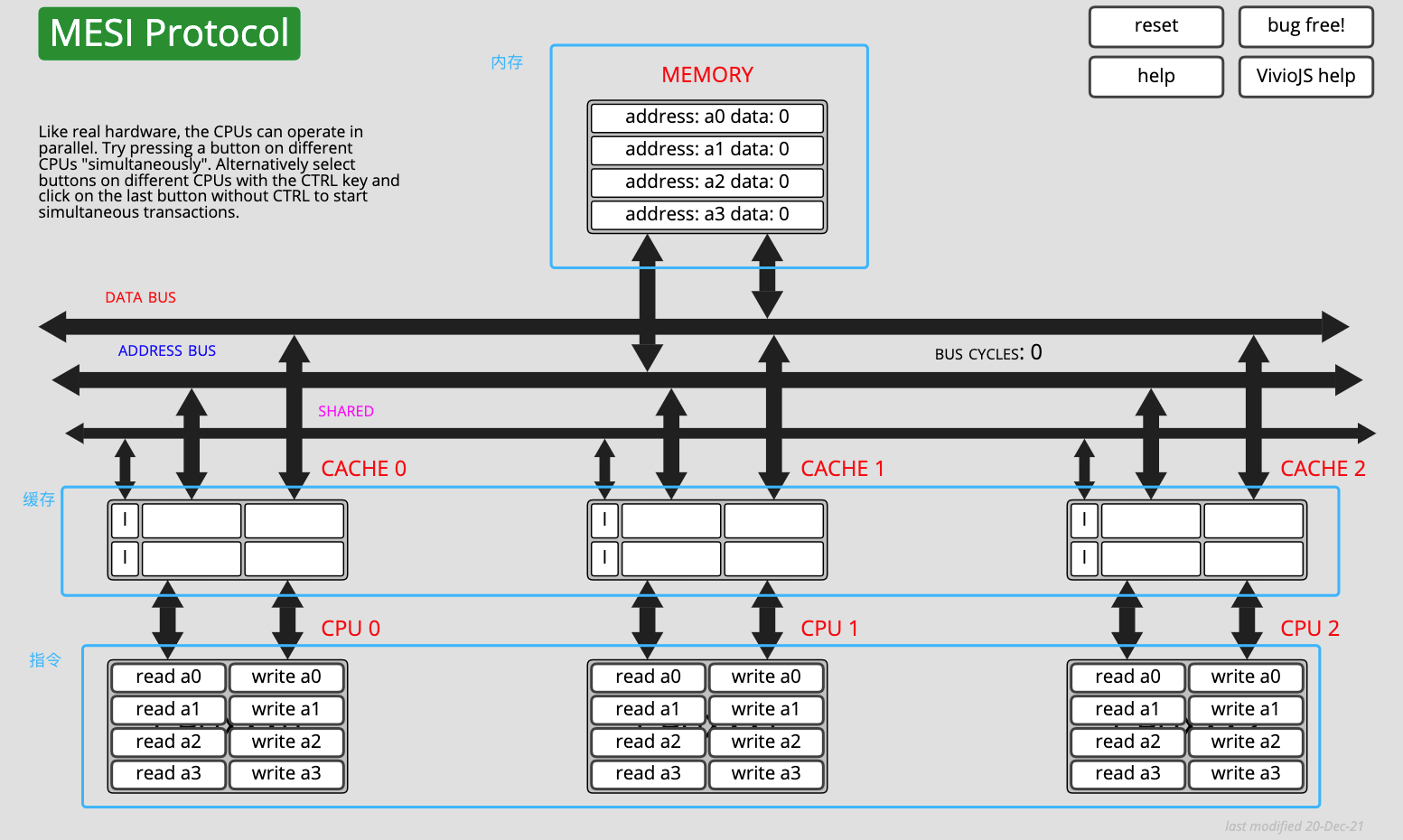
MESI 协议有一个非常 nice 的在线体验网站,你可以对照文章内容,在网站上操作指令区,并观察内存和缓存的数据和状态变化。网站地址:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESI.htm
MESI 协议在线模拟
4.4 写缓冲区 & 失效队列
MESI 协议保证了 Cache 的一致性,但完全地遵循协议会影响性能。 因此,现代的 CPU 会在增加写缓冲区和失效队列将 MESI 协议的请求异步化,以提高并行度:
- 写缓冲区(Store Buffer)
由于在写入操作之前,CPU 核心 1 需要先广播 RFO 请求获得独占权,在其它核心回应 ACK 之前,当前核心只能空等待,这对 CPU 资源是一种浪费。因此,现代 CPU 会采用 “写缓冲区” 机制:写入指令放到写缓冲区后并发送 RFO 请求后,CPU 就可以去执行其它任务,等收到 ACK 后再将写入操作写到 Cache 上。
- 失效队列(Invalidation Queue)
由于其他核心在收到 RFO 请求时,需要及时回应 ACK。但如果核心很忙不能及时回复,就会造成发送 RFO 请求的核心在等待 ACK。因此,现代 CPU 会采用 “失效队列” 机制:先把其它核心发过来的 RFO 请求放到失效队列,然后直接返回 ACK,等当前核心处理完任务后再去处理失效队列中的失效请求。
写缓冲区 & 失效队列

事实上,写缓冲区和失效队列破坏了 Cache 的一致性。 举个例子:初始状态变量 a 和变量 b 都是 0,现在 Core1 和 Core2 分别执行这两段指令,最终 x 和 y 的结果是什么?
Core1 指令
a = 1; // A1
x = b; // A2
Core2 指令
b = 2; // B1
y = a; // B2
我们知道在未同步的情况下,这段程序可能会有多种执行顺序。不管怎么执行,只要 2 号指令是在 1 号指令后执行的,至少 x 或 y 至少一个有值。但是在写缓冲区和失效队列的影响下,程序还有以意料之外的方式执行:
| 执行顺序(先不考虑 CPU 超前流水线控制) | 结果 |
|---|---|
| A1 → A2 → B1 → B2 | x = 0, y = 1 |
| A1 → B1 → A1 → B2 | x = 2, y = 1 |
| B1 → B2 → A1 → A2 | x = 1, y = 0 |
| B1 → A1 → B2 → A2 | x = 2, y = 1 |
| A2 → B1 → B2 → A1(A1 与 A2 重排) | x = 0, y = 0 |
| Core2 也会出现相同的情况,不再赘述 | x = 0, y = 0 |

上图。
写缓冲区造成指令重排
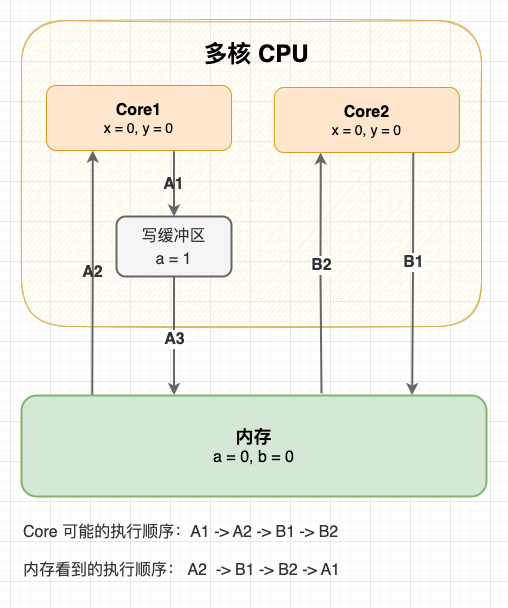
可以看到:从内存的视角看,直到 Core1 执行 A3 来刷新写缓冲区,写操作 A1 才算真正执行了。虽然 Core 的执行顺序是 A1 → A2 → B1 → B2,但内存看到的顺序却是 A2 → B1 → B2 → A1,变量 a 写入没有同步给对变量 a 的读取,Cache 的一致性被破坏了。
5. 总结
-
1、在 CPU Cache 的三级缓存中,会存在 2 个缓存一致性问题:
- 纵向 - Cache 与内存的一致性问题: 在修改 Cache 数据后,如何同步回内存?
- 横向 - 多核心 Cache 的一致性问题: 在一个核心修改 Cache 数据后,如何同步给其他核心 Cache?
-
2、Cache 与内存的一致性问题有 2 个策略:
- 写直达策略: 始终保持 Cache 数据和内存数据一致,在每次写入操作中都会写入内存;
- 写回策略: 只有在脏 Cache 块被替换出去的时候写回内存,减少写回内存的次数;
-
3、多核心 Cache 一致性问题需要满足 2 点特性:
- 写传播(总线嗅探): 每个 CPU 核心的写入操作,需要传播到其他 CPU 核心;
- 事务串行化(总线仲裁): 各个 CPU 核心所有写入操作的顺序,在所有 CPU 核心看起来是一致。
-
4、MESI 协议能够满足以上 2 点特性,通过 “已修改、独占、共享、已失效” 4 个状态实现了 CPU Cache 的一致性;
-
5、现代 CPU 为了提高并行度,会在增加 写缓冲区 & 失效队列 将 MESI 协议的请求异步化, 从内存的视角看就是指令重排,破坏了 CPU Cache 的一致性。
今天,我们主要讨论了 CPU 的缓存一致性问题与对应的缓存一致性协议。这里有一个问题:既然 CPU 已经实现了 MESI 协议,已经在硬件层面实现了写传播和事务串行化,为什么 Java 语言层面还需要定义 volatile 关键字呢?岂不是多此一举?
你可能会说因为写缓冲区和失效队列破坏了 Cache 一致性。好,那不考虑这个因素的话,还需要定义 volatile 关键字吗?这个问题我们在 [下一篇文章]展开讨论,请关注。





