
课程名称:Java生产环境下性能监控与调优详解
课程讲师:若鱼1919
课程内容:
JVM参数类型:
标准参数:
help,cp,server。client,classpath,showversion
X参数
-Xint:解释执行
-Xcomp:第一次使用就编译成本地代码
-Xmixed:混合模式,JVM自己决定是否编译成本地代码
XX参数:
主要用于JVM调优和Debug
分类:
1.boolean类型
格式:-XX[+/-]<name> 表示启用或者禁用name属性
2.非boolean类型
格式:-XX<name>=<value> 表示name的值为value
-Xms相当于-XX:InitailHeapSize
-Xmx相当于-XX:MaxHeapSize
-Xss相当于-XX:ThreadStackSize
查看JVM运行时参数
-XX:+PrintFlagsInitial
-XX:+PrintFlagsFinal
-XX:+UnlockExperimentalVMOptions解锁实验参数
-XX:+UnlockDiagnosticVMOptions 解锁诊断参数
-XX:+PrintCommandLineFlags 打印命令行参数
= 默认值
:=被用户或者JVM修改后
jps用户查看java进程
jinfo查看Java进程的配置信息
jstat查看JVM统计信息(类装载,垃圾回收,JIT编译)
jstat -class | -complier |-gc|-printcompliation
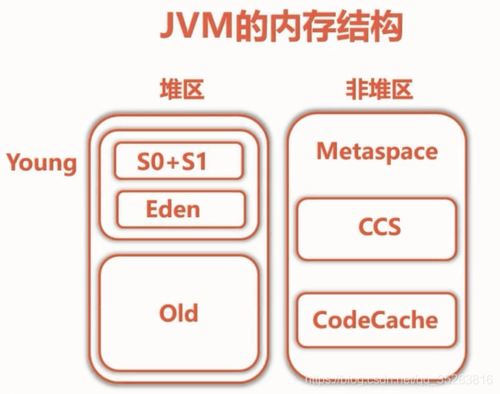
CCS:短指针启用,压缩类空间,32位指针的Class
CodeCache:JIT代码信息,JNI代码
Metaspace=Class,Package,Method,Field,字节码,常量池,符号引用等等
导出内存映像文件
内存溢出自动导出 -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=./
使用jmap命令手动导出
Jstack与线程状态
JVM的内存结构
1.运行时数据区
程序计数器:JVM支持多线程同时运行,每一个线程都有自己的PC Register,线程正在执行的方法叫做当前方法,如果是Java代码,PC Register里存放的就是当前正在执行的指令的地址,如果是C代码,则为空。
虚拟机栈:是线程私有的,生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每一个方法执行的同时都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法从调用到执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
堆:是Java虚拟机管理内存最大的一块。堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。在此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。java堆可以处于物理上不连续的内存空间,只要在逻辑上连续的即可。
方法区:是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但它却有一个别名叫做非堆。
运行时常量池:是方法区的一部分。Class文件中除了类的版本,字段,方法,接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量中存放。
本地方法栈:为虚拟机使用到的Native方法服务。
常见垃圾回收算法
思想:枚举根节点,做可达性分析
根节点:类加载器,Thread,虚拟机栈的本地变量表,static成员,常用引用,本地方法栈的变量等
标记清除
1.算法:算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有
2.缺点:效率不高,标记和清除的效率不高。产生碎片,碎片太多会导致提前GC。
复制
1.算法:它将可用内存按容量划分为大小相等的两块,每次使用其中一块。当这一块的内存用完了,就将还存活的对象复制到另一块上面,然后再把已经使用过的内存空间一次清理掉。
2.优缺点:
实现简单,运行高效,但是空间利用率低。
标记整理
1.算法:标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
2.优缺点:没有了内存碎片,但是整理内存比较耗时。
分带垃圾回收
1.young区用复制算法
2.Old区用标记清除或者标记整理
对象分配
1.对象优先在Eden区分配
2.大对象直接进入老年代:-XX:PretenureSizeThreshold
3.长期存活对象进入老年代:-XX:MaxTenuringThreshold -XX:+PrintTenuringDistribution -XX:TargetSurvivorRatio
垃圾收集器
串行收集器Serial:Serial,Serial Old,用于嵌入式,执行串行收集器程序会停顿
-XX:+UseSerialGC -XX:+UseSerialOldGC
并行收集器Parallel:Parallel Scavenge,Parallel Old,吞吐量
-XX:UseParallelGC,-XX:+UseParallelOldGC
-XX:+UseParallelGC 手动开启,Server默认开启
-XX:ParallelGCThreads=<N>多少个GC线程 CPU>8 N=5/8 Cpu<8 N=CPU
并行收集器的自适应
-XX:MaxGCPauseMills=<N>
-XX:GCTimeRatio=<N>
-Xmx<N>
动态内存调整
-XX:YoungGenerationSizeIncrement=Y
-XX;TenuredGenerationSizeIncrement=T
-XX:AdaptiveSizeDecrementScaleFactor=D
Server模式下的默认收集器
并发收集器Concurrent:CMS,G1,停顿时间
JDK1.8包含两个CMS和G1收集器
CMS:XX:+UseConcMarkSweepGC -XX:UseParNewGC
CMS垃圾收集过程
1.CMS initial mark:初试标记Root,STW
2.CMS concurrent mark:并发标记
3.CMS-concurrent-preclean:并发预清理
4.CMS remark:重新标记,STW
5.CMS concurrent sweep:并发清除
6.CMS-concurrent-reset:并发重置
缺点:占用CPU,浮动垃圾,空间碎片
相关参数:-XX:ConcGCThreads:并发线程数
-XX:+UseCMSCompactAtFullCollection:FULL GC 之后压缩
-XX:CMSFullGCsBeforeCompaction:多少次FullGC之后压缩一次
-XX:CMSInitiatingOccupancyFraction:Old区存活对象达到多少出发FullGC
-XX:+UseCMSInitiatingOccupancyOnly:是否动态调整
-XX:+CMSScavengeBeforeRemark:FullGC之前先做YGC
-XX:+CMSClassUnloadingEnabled:启用回收Perm区
iCMS:适合于单核或者双核
G1:-XX:+UseG1GC(推荐)(新生代和老生代收集器)
如果对象超过region大小的一半,就要放到H区
Region:
STAB:Snapshot-At-The-Beginning,它是通过Root Tracing得到的,GC开始时候存活对象的快照
Rset:记录了其他Region中对象引用本Region中对象的关系,属于points-into结构
Young GC:1.新对象进入Eden区
2.存活对象拷贝到Syrvivor区
3.存活时间达到年龄阈值,对象晋升Old区
MixedGC;不是FullGC,回收所有的Young和部分Old
InitiatingHeapOccupancyPercent:堆占有率达到这个数值则触发global concurrent marking ,默认45%
G1HeapWastePercent:在global concurrent marking结束之后,可以知道区有多少空间要被回收,在每次 YGC之后和再次发生Mixed GC之前,会检查垃圾占比是否达到此参数,只有达到 了,下次才会发生Mixed GC
G1MixedGCLiveThresholdPercent:Old区的region被回收的时候存活对象占比
G1MixedGCCountTarget:一次global concurrent marking之后,最多执行Mixed GC次数
G1OldCSetRegionThresholdPercent:一次Mixed GC中能被选入CSET的最多old区的region数量
常用参数:1.-XX:+UseG1GC 开启G1
2.-XX:G1HeapRegionSize=n,region的大小,1-32M,最多2048个
3.-XX:MaxGCPauseMills=200 最大停顿时间
4.-XX:ParallelGCThreads=n SWT线程数
5.-XX:ConcGCThreads=n; 并发线程数=1/4*并行
6.-XX:G1ReservePercent=10保留防止to Space溢出
7.-XX:G1NewSizePercent,-XX:G1MaxNewSizePercent
最佳实践:1.年轻代大小:避免使用-Xmn,-XX:NewRatio等显示设置Young区大小,会覆盖暂停时间目标
2.暂停时间目标:暂停时间不要太严苛,其吞吐量目标是90%的应用程序时间和10%的垃圾回收时间,太严苛会影响吞吐量
是否需要切换到G1:
1.50%以上堆被存活对象占用
2.对象分配和晋升速度变化非常大
3.垃圾回收时间特别长,超过了一秒
并行:指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。适合科学计算,后台处理等弱交互场景
并发:指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),垃圾收集线程执行的时候不会停顿用户程序的执行。适合对响应时间有要求的场景,如Web
停顿时间:垃圾收集器做垃圾回收中断应用执行的时间 XX:MaxGCPauseMills
吞吐量:花在垃圾收集的时间和花在应用时间的占比。XX:GCTimeRatio=<n>,垃圾时间收集占1/1+n
如何选择垃圾回收器
1.优先调整堆的大小让服务器自己来选择
2.如果内存小于100M,使用串行收集器
3.如果是单核,并且没有停顿要求,串行或者JVM'自己来选择
4.如果允许停顿时间超过一秒,选择并行或者JVM自己选
5.如果响应时间最重要,并且不能超过一秒,使用并发收集器




