①课程介绍
课程名称:Python3入门机器学习 经典算法与应用 入行人工智能
课程章节:8-6;8-7;8-8
主讲老师:liuyubobobo
内容导读
- 第一部分 交叉验证的原理
- 第二部分 交叉验证的使用场景
- 第三部分 交叉验证的使用方法
②课程详细
第一部分 交叉验证的原理
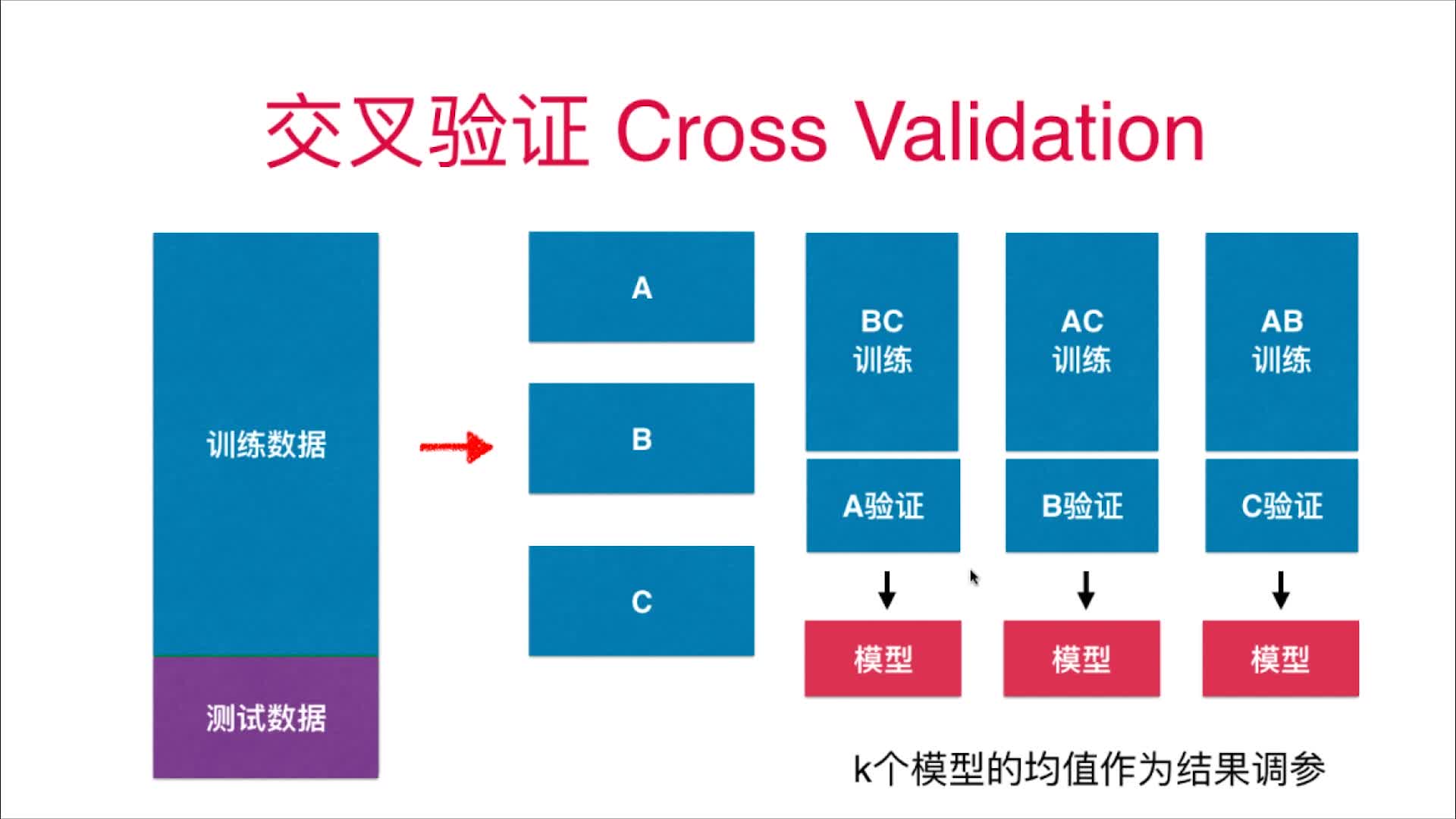
交叉验证是通过对数据进行拆分,分成多少分,分别进行训练和验证,这样既避免了极端数据的影响,又能使你的准确率更加可信。
第二部分 交叉验证的使用场景

交叉验证通常使用在数据特别地极端,比如数据波动大,有异常点等情况,将数据分为K分进行交叉验证,能在一定程度上缓解极端数据的影响,得到更加可信的准确率
第三部分 交叉验证的使用方法
导入包
import numpy as np
from sklearn import datasets
导入手写字体数据
digits = datasets.load_digits()
X = digits.data
y = digits.target
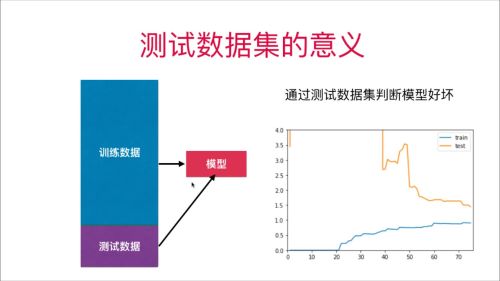
先使用train_test_split的方法进行数据分割,用测试数据集和实验数据集进行测试
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.4, random_state=666)
使用for循环的方式来找到最好的模型
from sklearn.neighbors import KNeighborsClassifier
best_score, best_k, best_p = 0, 0, 0
for k in range(2, 11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_score, best_k, best_p = score, p, k
print('best_socre=',best_score)
print('best_k=',best_k)
print('best_p=',best_p)
best_socre= 0.9860917941585535
best_k= 2
best_p= 3
接下来使用的是交叉验证的方式来测试准确率
导入交叉验证的函数并调用
from sklearn.model_selection import cross_val_score
knn_clf = KNeighborsClassifier()
cross_val_score(knn_clf, X_train, y_train)
#选择多少分 cv = 5分为5份
array([0.99537037, 0.98148148, 0.97685185, 0.97674419, 0.97209302])
cross_val_score(knn_clf, X_train, y_train)
knn_clf为创建的对象,后面添加数据,在进行交叉验证,这就是交叉验证的调用方式,现在默认CV=5也就是循环五次
③课程思考
- 对于数据分布有偏差,可以应用交叉验证,多次分割数据分别测试准确性,来测试多次准确性的平均值。
- 交叉验证比普通的慢很多倍,但是它有他的优势,他得出的准确率具有很高的可信度。
④课程截图