学习课程:Python全能工程师2022版
章节名称:第21周 数据分析进阶:统计分析与机器学习
讲师:DeltaF
课程内容:
SciPy
SciPy是一个开源的Python算法库和数学工具包。
SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
pip install scipy
import scipy
scipy.optimize.curve_fit() #拟合曲线
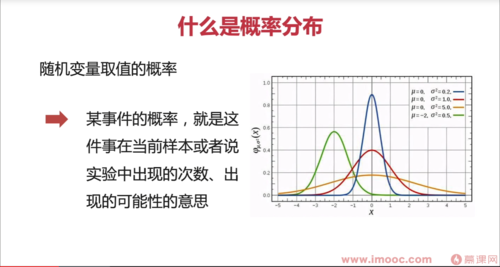
随机变量

概率分布
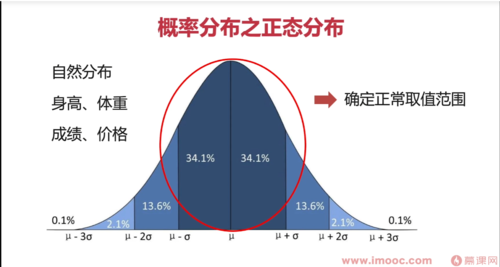
正态分布
自然分布大都呈现正态分布,比如身高、体重、成绩、价格
import scipy.stats as st
st.norm.rvs(loc=0,scale=1,size=1000)
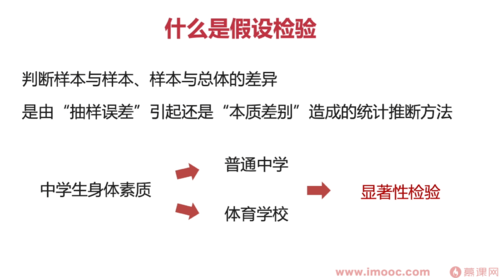
统计推断

假设检验
显著性检验

单样本t检验
问题:样本均值与标准t分布是否存在显著性差异
假设(α=0.05)
H0:不存在显著差异
H1:存在小助兴差异
Scikit-Learn
scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和
Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
sklearn有一个完整而丰富的官网,里面讲解了基于sklearn对所有算法的实现和简单应用。然而,这个官网是全英文的,并且现在没有特别理想的中文接口,市面上也没有针对sklearn非常好的书。
官方文档:https://scikit-learn.org/stable/index.html
pip install sklearn
非监督学习:KMeans
聚类算法,是无监督学习的代表算法之一,其目的是将数据划分成有意义或有用的组(或簇)
作为聚类算法的典型代表,KMeans可以说是最简单的聚类算法没有之一
KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的数
据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
簇中所有数据的均值通常被称为这个簇的“质心”(centroids)。在一个二维平面中,一簇数据点的质心的
横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高
维空间。
学习收获:
1、对SciPy和Scikit-Learn这2个python包有了进一步理解
2、了解了一些统计学原理