课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:scrapy配置图片下载
主讲老师:bobby
课程内容:
今天学习的内容包括:scrapy配置图片下载
课程收获:
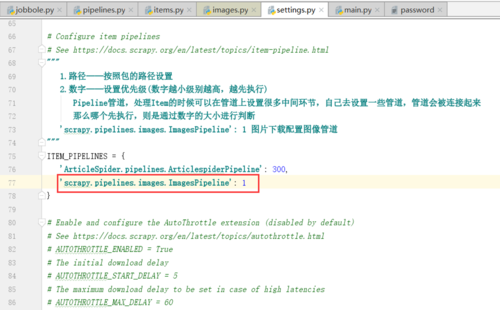
1.图片下载相关配置(settings.py)
1.settings.py中配置图像管道
要启用媒体管道,必须首先将其添加到项目中 ITEM_PIPELINES 设置。
对于图像管道,请使用:ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1}
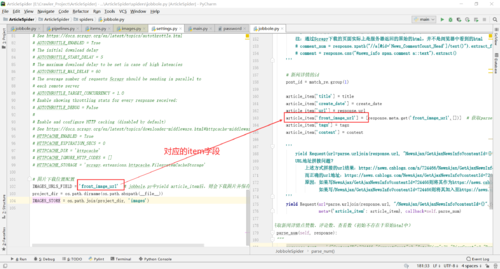
2.配置图片本地存储地址
然后,将目标存储设置配置为用于存储下载的图像的有效值。否则,管道将保持禁用状态,即使将其包含在 ITEM_PIPELINES 设置。
project_dir = os.path.dirname(os.path.abspath(__file__))
IMAGES_STORE = os.path.join(project_dir, 'images')

3.配置下载item中的哪个字段的url地址
IMAGES_URLS_FIELD = 'front_image_url' #j obbole.py中yieldarticle_item后,则会下载图片并保存至images文件夹下
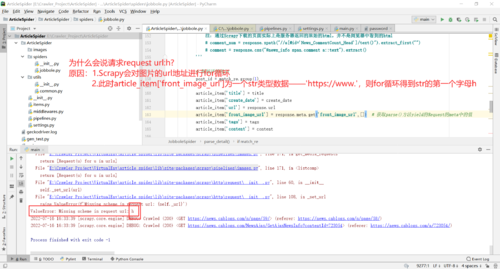
2.图片下载
1.下载图片时出现ValueError: Missing scheme in request url: h错误

原因:item中的item['front_image_url']数据应该是list类型的数据而非str类型数据

2.图片下载成功

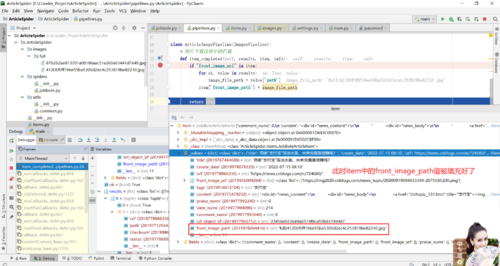
3.自定义图片下载管道
1.代码
# 能够定义Item并设置值,然后使得Scrapy自动将值放到Pipeline中,Pipeline中专门做数据的保存处理 class ArticlespiderPipeline: def process_item(self, item, spider): return item # 图片下载过程中的拦截 class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if "front_image_url" in item: image_file_path = "" for ok, value in results: image_file_path = value['path'] item['front_image_path'] = image_file_path return item

2.查看results的值
value['path']的值为图片存储在本地的值


注:自动将填补item['front_image_path']的值