
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:items的定义和使用
主讲老师:bobby
课程内容:
今天学习的内容包括:items的定义和使用
课程收获:
1.Item创建
1.Item作用
提供了额外的保护机制来避免拼写错误导致的未定义字段错误
可以更为方便的操作和保存item中的数据,以及满足scrapy其他相关功能的支持
2.代码
import scrapy class ArticleSpiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() # 网页URL不定长,则通过MD5生成id,使得URL地址存储为定长字符 front_image_url = scrapy.Field() front_image_path = scrapy.Field() # 保存图片本地地址 praise_nums = scrapy.Field() comment_nums = scrapy.Field() view_nums = scrapy.Field() tags = scrapy.Field() content = scrapy.Field()
3.jobbole.py中使用自定义的Item
1.代码截图


2.查看Item对象的值
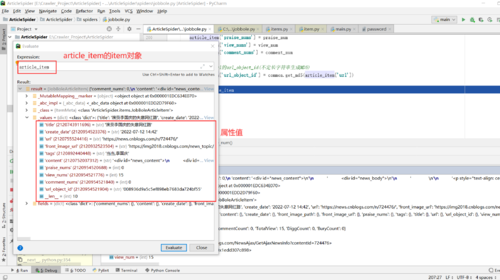
4.yield Item——Scrapy自动将Item交给对应的Pipeline进行数据处理和保存




