课程名称:Spark+ClickHouse实战企业级数据仓库
课程章节:初识OLAP数仓架构
主讲老师:xiaochen
课程内容:
今天的学习内容包括:
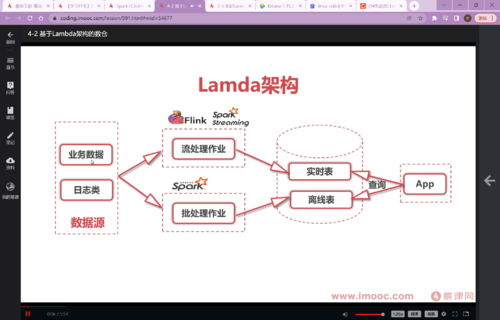
基于Lambda架构的数仓——早期数仓架构多为Lambda架构,在这种架构中,数仓会维护两条线进行计算,一条实时,一条批量。假如整个系统只有⼀个批处理层,会导致⽤户必须等待很久才能获取计算结果,⼀般有⼏个⼩时的延迟。数据分析部门只能查看前⼀天的统计分析结果,⽆法获取当前的结果,这对于实时决策来说有⼀个巨⼤的时间鸿沟,很可能导致管理者错过最佳决策时机。
基于Kappa架构的数仓——Lambda架构有其自身的缺点,要为一个功能维护两套代码,这导致功能迭代时维护复杂,这就出现了Kappa架构。没有必要维护⼀个批处理层,直接使⽤⼀个流处理层即可满⾜需求。利用kafka,不仅时消息队列,更能维护长时间的数据,当需要批处理时,只需要从更早时候进行消费,就可以替代批处理的过程。
基于OLAP架构的数仓——在这种架构中,数据输入kafka,通过spark或flink进行消费,将数据存入OLAP计算引擎,数仓的DWD、DWS、ADS层都有OLAP引擎完成,这样的架构更加轻量
课程收获:
spark|flink与OLAP数据查询引擎有所不同。OLAP查询引擎主要注重交互式查询,对单机的配置要求高,基于内存进行数据分析,适用于30分钟内的计算。而spark|flink拥有成熟的suffer和血缘机制,稳定性高,当内存不足时,可以利用磁盘进行计算,注重稳定,使用天级或更长时间的计算。
在许多项目中,不会明确的区分Lambda架构和Kappa架构,多数会混合使用。