
复杂业务查询对于传统的关系型数据库来说是一种考验,而通过 TiKV 行存与 TiFlash 的列存结合使用就能很好地应对。本文根据 TUG 用户边城元元在 TiDB 社区技术交流石家庄站的分享整理,详细介绍了 TiKV & TiFlash 加速复杂业务查询的原理及实践方案。
背景
在互联网公司或传统公司的 CRM 系统中,最常用的功能之一客户的筛选。通过不同的角度、维度、标签的组合来框选客户,以便后续的业务操作。
这无疑是对传统关系型数据库,或者关系数据库加列存数据库的架构是一种考验,主要有下面几个痛点:
-
传统的关系型数据库无法通过加索引来优化加速查询,业务无法正常开展;
-
列存数据库需要把筛选相关数据放到列数据库,并且需要做好数据实时同步;
-
无法从数据库层面做好数据的读取,往往需要从列数据库读取数据后再到关系数据库进行数据合并后输出,性能不容乐观。
TiDB 数据库的 TiKV 和 TiFlash 的组合理论上解决了上面的几个痛点。
TiKV 行存 与 TiFlash 列存混合使用
TiDB 中 query 执行的示意图,可以看到在 TiDB 中一个 query 的执行会被分成两部分,一部分在 TiDB 执行,一部分下推给存储层( TiFlash/TiKV )执行。
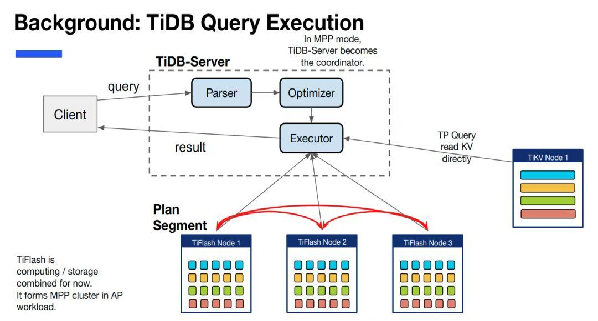
混用原理
-
TiDB 的行列混合并不是传统设计上的行存列存二选一,而是 TiDB 可以在同一张表同时拥有行存和列存,且两者永远保持数据强一致(而非最终一致)。
-
多表查询分别使用不同的引擎 TiKV 或 TiFlash。
-
TiFlash 支持 MPP 模式的查询执行,即在计算中引入跨节点的数据交换(data shuffle 过程)。
混用优化

标签系统高级筛选
通过标签(从宽表里不确定字段)和窄表特定字段组合查询客户并分页
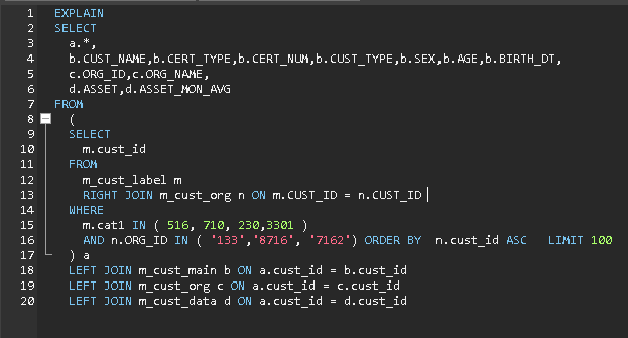
Read from TiKV
SELECT
/*+ READ_FROM_STORAGE(tikv[b], tikv[c],tikv[d]) */
a.*,
b.CUST_NAME,b.CERT_TYPE,b.CERT_NUM,b.CUST_TYPE,b.SEX,b.AGE,b.BIRTH_DT,
c.ORG_ID,c.ORG_NAME,
d.ASSET,d.ASSET_MON_AVG
FROM
(
SELECT /*+ READ_FROM_STORAGE(tikv[m],tikv[n]) */
m.cust_id
FROM
m_cust_label m
RIGHT JOIN m_cust_org n ON m.CUST_ID = n.CUST_ID
WHERE
m.cat1 IN ( 516, 710, 230,3301 )
AND n.ORG_ID IN ( '133','8716', '7162') ORDER BY n.cust_id ASC LIMIT 100
) a
LEFT JOIN m_cust_main b ON a.cust_id = b.cust_id
LEFT JOIN m_cust_org c ON a.cust_id = c.cust_id
LEFT JOIN m_cust_data d ON a.cust_id = d.cust_id ;
4G,2c 虚拟机 300 万数据,首次执行 48 s 二次执行 0.7s
Read From TiKV & TiFlash
SELECT
/*+ READ_FROM_STORAGE(tikv[b], tikv[c],tikv[d]) */
a.*,
b.CUST_NAME,b.CERT_TYPE,b.CERT_NUM,b.CUST_TYPE,b.SEX,b.AGE,b.BIRTH_DT,
c.ORG_ID,c.ORG_NAME,
d.ASSET,d.ASSET_MON_AVG
FROM
(
SELECT /*+ READ_FROM_STORAGE(tiflash[m],tikv[n]) */
m.cust_id
FROM
m_cust_label m
RIGHT JOIN m_cust_org n ON m.CUST_ID = n.CUST_ID
WHERE
m.cat1 IN ( 516, 710, 230,3301 )
AND n.ORG_ID IN ( '133','8716', '7162') ORDER BY n.cust_id ASC LIMIT 100
) a
LEFT JOIN m_cust_main b ON a.cust_id = b.cust_id
LEFT JOIN m_cust_org c ON a.cust_id = c.cust_id
LEFT JOIN m_cust_data d ON a.cust_id = d.cust_id
4G,2c 虚拟机 300 万数据,首次执行 3s 二次执行 0.3s
TiFlash & MPP
控制是否选择 MPP 模式
变量 tidb_allow_mpp 控制 TiDB 能否选择 MPP 模式执行查询。变量 tidb_enforce_mpp 控制是否忽略优化器代价估算,强制使用 TiFlash 的 MPP 模式执行查询。
这两个变量所有取值对应的结果如下:
| tidb_allow_mpp=off | tidb_allow_mpp=on(默认) | |
|---|---|---|
| tidb_enforce_mpp=off(默认) | 不使用 MPP 模式。 | 优化器根据代价估算选择。(默认) |
| tidb_enforce_mpp=on | 不使用 MPP 模式。 | TiDB 无视代价估算,选择 MPP 模式。 |
set @@session.tidb_allow_mpp=1;
set @@session.tidb_enforce_mpp=1;
SELECT
/*+ READ_FROM_STORAGE(tikv[b], tikv[c],tikv[d]) */
a.*,
b.CUST_NAME,b.CERT_TYPE,b.CERT_NUM,b.CUST_TYPE,b.SEX,b.AGE,b.BIRTH_DT,
c.ORG_ID,c.ORG_NAME,
d.ASSET,d.ASSET_MON_AVG
FROM
(
SELECT /*+ READ_FROM_STORAGE(tiflash[m],tiflash[n]) */
m.cust_id
FROM
m_cust_label m
RIGHT JOIN m_cust_org n ON m.CUST_ID = n.CUST_ID
WHERE
m.cat1 IN ( 516, 710, 230,3301 )
AND n.ORG_ID IN ( '133','8716', '7162') ORDER BY n.cust_id ASC LIMIT 100
) a
LEFT JOIN m_cust_main b ON a.cust_id = b.cust_id
LEFT JOIN m_cust_org c ON a.cust_id = c.cust_id
LEFT JOIN m_cust_data d ON a.cust_id = d.cust_id
使用 MPP 模式来执行查询后基本秒开,4G 2c 虚拟机 300 万数据,首次执行 1s 二次执行 0.15s
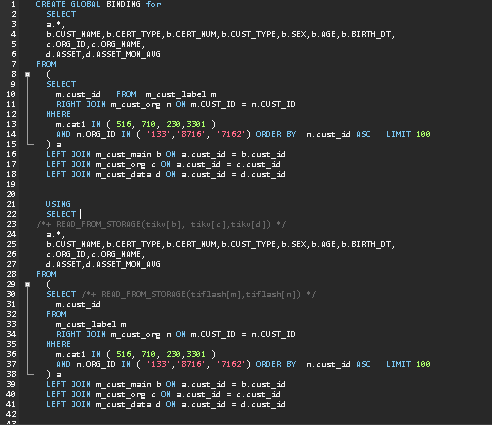
2.4 SPM 固定执行计划
CREATE GLOBAL|SESSION BINDING for <BindableStmt > USING <BindableStmt2>
SHOW GLOBAL|SESSION BINDINGS ; -- 查看绑定计划explain format = 'verbose' <BindableStmt2>;
show warnings; -- 通过执行 show warnings 了解该 SQL 语句使用了哪一条 binding
固定特定查询走 TiFlash 列存查询。
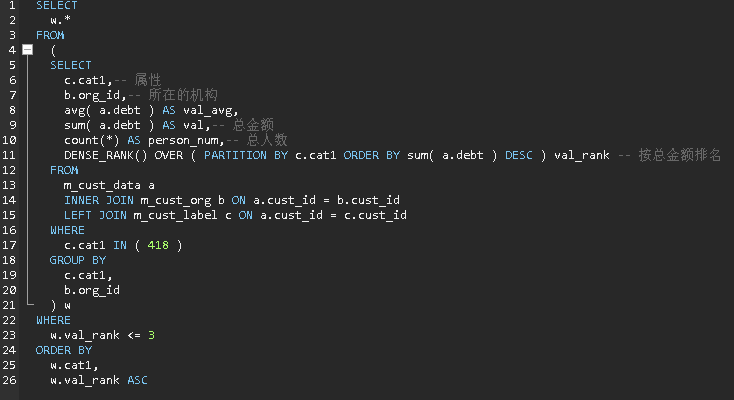
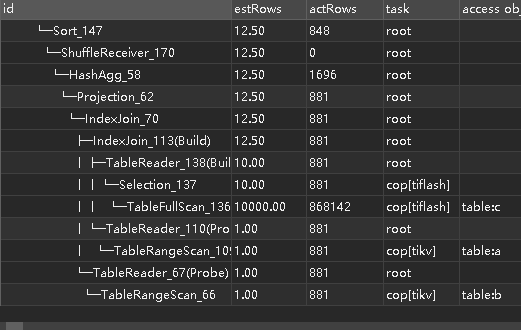
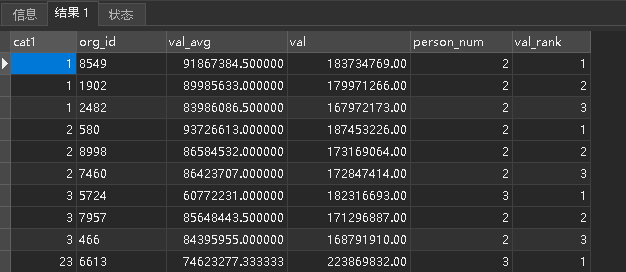
标签下价值机构排名
根据选中的属性(多值)
使用这些值最多的排名前 3 的机构,并统计出总额
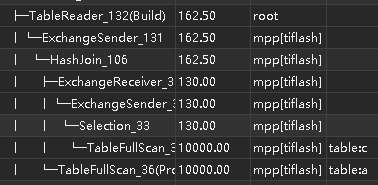
执行计划
table:c 走 TiFlash ;table:a, table:b 走 TiKV ,同时使用了列存和行存的优势。
总结
使用 TiKV 和 TiFlash 可以加速复杂查询,下面简单增加了使用使用场景。
| 组件 | 适用场景说明 |
|---|---|
| TiKV | 检索条件固定,且有索引 |
| TiFlash | 检索条件不固定,无法加索引 |
| TiKV + TiFlash | 部分表检索条件不固定,部分表有索引 |
如果有描述不当的地方欢迎评论指正!
谢谢 PingCAP 社区的大力支持!




