

声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
-
目标:加速乐加密逆向
-
网站:
aHR0cHM6Ly93d3cubXBzLmdvdi5jbi9pbmRleC5odG1s -
逆向难点:OB 混淆、动态加密算法、多层 Cookie 获取
加速乐
加速乐是知道创宇推出的一款网站CDN加速、网站安全防护平台。
加速乐的特点是访问网站一般有三次请求:
-
第一次请求网站,网站返回的响应状态码为 521,响应返回的为经过 AAEncode 混淆的 JS 代码;
-
第二次请求网站,网站同样返回的响应状态码为 521,响应返回的为经过 OB 混淆的 JS 代码;
-
第三次请求网站,网站返回的响应状态码 200,即可正常访问到网页内容。
逆向思路
根据我们上面讲的加速乐的特点,我们想要获取到真实的 HTML 页面,需要经过以下三个步骤:
-
第一次请求网站,服务器返回的 Set-Cookie 中携带 jsluid_s 参数,将获取到的响应内容解密拿到第一次 jsl_clearance_s 参数的值;
-
携带第一次请求网站获取到的 Cookie 值再次访问网站,将获取到的响应内容解混淆逆向拿到第二次 jsl_clearance_s 参数的值;
-
使用携带 jsluid_s 和 jsl_clearance_s 参数的 Cookie 再次访问网站,获取到真实的 HTML 页面内容,继而采集数据。
抓包分析
进入网站,打开开发者人员工具进行抓包,在 Network 中我们可以看到,请求页面发生了三次响应 index.html,且前两次返回状态码为 521,符合加速乐的特点:
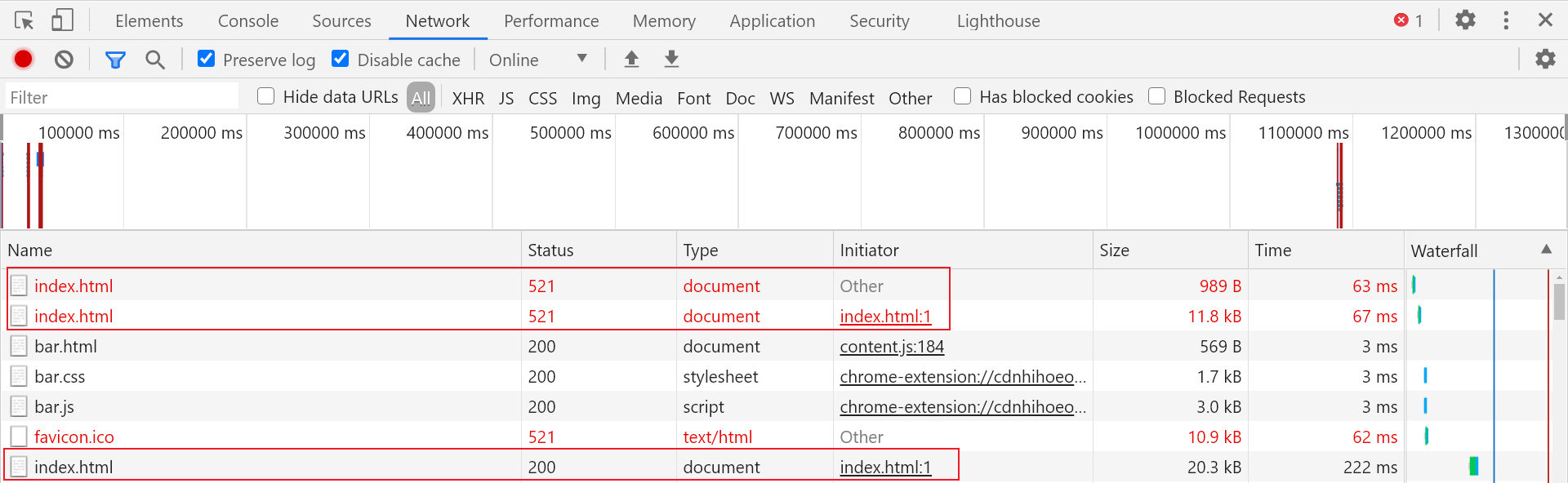
第一层 Cookie 获取
直接查看 response 显示无响应内容,我们通过 Fiddler 对网站进行抓包,可以看到第一个 index.html 返回的响应内容经过 AAEncode 加密,大致内容如下,可以看到一堆颜表情符号,还挺有意思的:
document.cookie 里的颜表情串实际上是第一次 __jsl_clearance_s 的值,可以直接通过正则提取到加密内容后,使用execjs.eval()方法即可得到解密后的值:
import re
import execjs
AAEncode_text = “”“以上内容”""
content_first = re.findall(‘cookie=(.*?);location’, AAEncode_text)[0]
jsl_clearance_s = execjs.eval(content_first).split(’;’)[0]
print(jsl_clearance_s)
__jsl_clearance_s=1658906704.109|-1|7n4kX8Rwzc8wTjrbHmWHj9GXCtI%3D
第二层 Cookie 获取
抓包到的第二个 index.html 返回的是经过 OB 混淆的 JS 文件,我们需要对其进行调试分析,但是直接在网页中通过 search 搜索很难找到该 JS 文件的位置,这里推荐两种方式对其进行定位:
1. 文件替换
右键点击抓包到的第二个状态码为 521 的 index.html 文件,然后按照以下方式将其保存到本地:
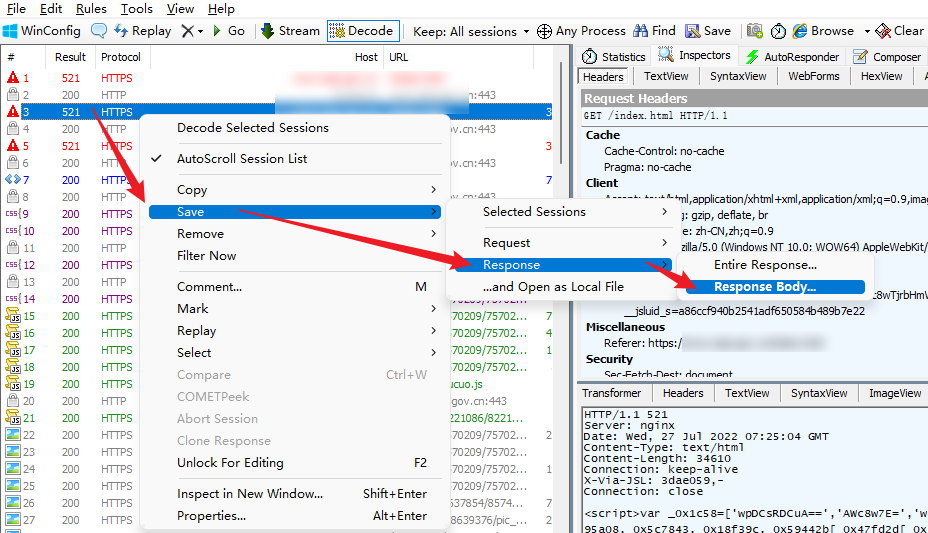
保存到本地后会发现 JS 文件被压缩了不利于观察,可以通过以下网站中的 JS 格式化工具将其格式化:https://spidertools.cn/#/formatJS,将格式化后的代码粘贴到编辑器中进行处理,可能需要一些微调,例如首尾 Script 标签前后会多出空格,在 < script > 后添加debugger;如下所示:
params = json.loads(go_params)
return params
def get_third_cookie():
with open(‘jsl.js’, ‘r’, encoding=‘utf-8’) as f:
jsl_js = f.read()
params = get_second_cookie()
# 传入字典
third_cookie = execjs.compile(jsl_js).call(‘cookies’, params)
cookies.update(third_cookie)
def main():
get_first_cookie()
get_third_cookie()
resp_third = requests.get(url=url, headers=headers, cookies=cookies)
resp_third.encoding = 'utf-8’
print(resp_third.text)
if name == ‘main’:
main()




