
在这里不具体介绍yolo的算法原理了,网上资源非常多,这里只谈如何去跑通yolo。那好吧,先上代码。。。
yolo3代码
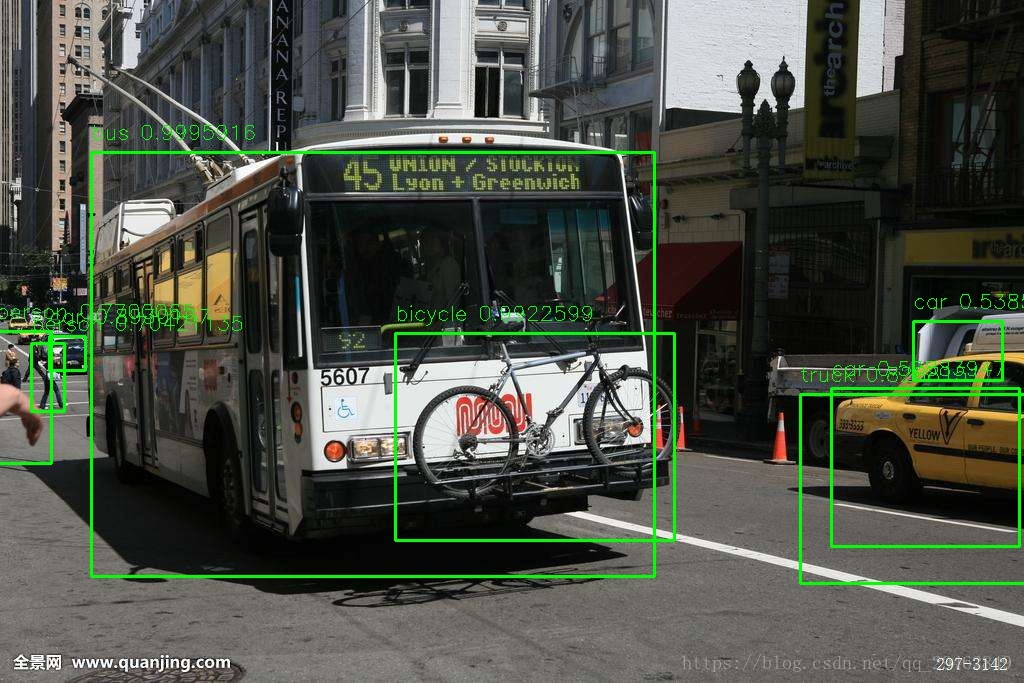
这是代码中的一部分,通过加载提前训练好的yolo3模型来进行物体检测,注意代码中加注释的地方,修改成自己路径即可。
import argparseimport osimport numpy as npfrom keras.layers import Conv2D, Input, BatchNormalization, LeakyReLU, ZeroPadding2D, UpSampling2Dfrom keras.layers.merge import add, concatenatefrom keras.models import Modelimport structimport cv2
np.set_printoptions(threshold=np.nan)
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"os.environ["CUDA_VISIBLE_DEVICES"]="0"argparser = argparse.ArgumentParser(
description='test yolov3 network with coco weights')
argparser.add_argument( '-w C:\\Users\\new\\Desktop\\yolov3.weights', '--weights',
help='path to weights file')
argparser.add_argument( '-i C:\\Users\\new\\Desktop\\dog.jpg', '--image',
help='path to image file')class WeightReader:
def __init__(self, weight_file):
#这里使加载的模型路径,关于模型,后面有下载链接
with open("C:\\Users\\new\\Desktop\\yolov3.weights", 'rb') as w_f:
major, = struct.unpack('i', w_f.read(4))
minor, = struct.unpack('i', w_f.read(4))
revision, = struct.unpack('i', w_f.read(4)) if (major*10 + minor) >= 2 and major < 1000 and minor < 1000:
w_f.read(8) else:
w_f.read(4)
transpose = (major > 1000) or (minor > 1000)
binary = w_f.read()
self.offset = 0
self.all_weights = np.frombuffer(binary, dtype='float32') def read_bytes(self, size):
self.offset = self.offset + size return self.all_weights[self.offset-size:self.offset] def load_weights(self, model):
for i in range(106): try:
conv_layer = model.get_layer('conv_' + str(i))
print("loading weights of convolution #" + str(i)) if i not in [81, 93, 105]:
norm_layer = model.get_layer('bnorm_' + str(i))
size = np.prod(norm_layer.get_weights()[0].shape)
beta = self.read_bytes(size) # bias
gamma = self.read_bytes(size) # scale
mean = self.read_bytes(size) # mean
var = self.read_bytes(size) # variance
weights = norm_layer.set_weights([gamma, beta, mean, var])
if len(conv_layer.get_weights()) > 1:
bias = self.read_bytes(np.prod(conv_layer.get_weights()[1].shape))
kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape))
kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))
kernel = kernel.transpose([2,3,1,0])
conv_layer.set_weights([kernel, bias]) else:
kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape))
kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))
kernel = kernel.transpose([2,3,1,0])
conv_layer.set_weights([kernel]) except ValueError:
print("no convolution #" + str(i))
def reset(self):
self.offset = 0class BoundBox:
def __init__(self, xmin, ymin, xmax, ymax, objness = None, classes = None):
self.xmin = xmin
self.ymin = ymin
self.xmax = xmax
self.ymax = ymax
self.objness = objness
self.classes = classes
self.label = -1
self.score = -1
def get_label(self):
if self.label == -1:
self.label = np.argmax(self.classes) return self.label def get_score(self):
if self.score == -1:
self.score = self.classes[self.get_label()] return self.scoredef _conv_block(inp, convs, skip=True):
x = inp
count = 0
for conv in convs: if count == (len(convs) - 2) and skip:
skip_connection = x
count += 1
if conv['stride'] > 1: x = ZeroPadding2D(((1,0),(1,0)))(x) # peculiar padding as darknet prefer left and top
x = Conv2D(conv['filter'],
conv['kernel'],
strides=conv['stride'],
padding='valid' if conv['stride'] > 1 else 'same', # peculiar padding as darknet prefer left and top
name='conv_' + str(conv['layer_idx']),
use_bias=False if conv['bnorm'] else True)(x) if conv['bnorm']: x = BatchNormalization(epsilon=0.001, name='bnorm_' + str(conv['layer_idx']))(x) if conv['leaky']: x = LeakyReLU(alpha=0.1, name='leaky_' + str(conv['layer_idx']))(x) return add([skip_connection, x]) if skip else xdef _interval_overlap(interval_a, interval_b):
x1, x2 = interval_a
x3, x4 = interval_b if x3 < x1: if x4 < x1: return 0
else: return min(x2,x4) - x1 else: if x2 < x3: return 0
else: return min(x2,x4) - x3
def _sigmoid(x):
return 1. / (1. + np.exp(-x))def bbox_iou(box1, box2):
intersect_w = _interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax])
intersect_h = _interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax])
intersect = intersect_w * intersect_h
w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin
w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin
union = w1*h1 + w2*h2 - intersect return float(intersect) / uniondef make_yolov3_model():
input_image = Input(shape=(None, None, 3)) # Layer 0 => 4
x = _conv_block(input_image, [{'filter': 32, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 0},
{'filter': 64, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 1},
{'filter': 32, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 2},
{'filter': 64, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 3}]) # Layer 5 => 8
x = _conv_block(x, [{'filter': 128, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 5},
{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 6},
{'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 7}]) # Layer 9 => 11
x = _conv_block(x, [{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 9},
{'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 10}]) # Layer 12 => 15
x = _conv_block(x, [{'filter': 256, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 12},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 13},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 14}]) # Layer 16 => 36
for i in range(7):
x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 16+i*3},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 17+i*3}])
skip_36 = x # Layer 37 => 40
x = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 37},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 38},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 39}]) # Layer 41 => 61
for i in range(7):
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 41+i*3},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 42+i*3}])
skip_61 = x # Layer 62 => 65
x = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 62},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 63},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 64}]) # Layer 66 => 74
for i in range(3):
x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 66+i*3},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 67+i*3}]) # Layer 75 => 79
x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 75},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 76},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 77},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 78},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 79}], skip=False) # Layer 80 => 82
yolo_82 = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 80},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 81}], skip=False) # Layer 83 => 86
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 84}], skip=False)
x = UpSampling2D(2)(x)
x = concatenate([x, skip_61]) # Layer 87 => 91
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 87},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 88},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 89},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 90},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 91}], skip=False) # Layer 92 => 94
yolo_94 = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 92},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 93}], skip=False) # Layer 95 => 98
x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 96}], skip=False)
x = UpSampling2D(2)(x)
x = concatenate([x, skip_36]) # Layer 99 => 106
yolo_106 = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 99},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 100},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 101},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 102},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 103},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 104},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 105}], skip=False)
model = Model(input_image, [yolo_82, yolo_94, yolo_106])
return modeldef preprocess_input(image, net_h, net_w):
new_h, new_w, _ = image.shape # determine the new size of the image
if (float(net_w)/new_w) < (float(net_h)/new_h):
new_h = (new_h * net_w)/new_w
new_w = net_w else:
new_w = (new_w * net_h)/new_h
new_h = net_h # resize the image to the new size
resized = cv2.resize(image[:,:,::-1]/255., (int(new_w), int(new_h))) # embed the image into the standard letter box
new_image = np.ones((net_h, net_w, 3)) * 0.5
new_image[int((net_h-new_h)//2):int((net_h+new_h)//2), int((net_w-new_w)//2):int((net_w+new_w)//2), :] = resized
new_image = np.expand_dims(new_image, 0) return new_imagedef decode_netout(netout, anchors, obj_thresh, nms_thresh, net_h, net_w):
grid_h, grid_w = netout.shape[:2]
nb_box = 3
netout = netout.reshape((grid_h, grid_w, nb_box, -1))
nb_class = netout.shape[-1] - 5
boxes = []
netout[..., :2] = _sigmoid(netout[..., :2])
netout[..., 4:] = _sigmoid(netout[..., 4:])
netout[..., 5:] = netout[..., 4][..., np.newaxis] * netout[..., 5:]
netout[..., 5:] *= netout[..., 5:] > obj_thresh for i in range(grid_h*grid_w):
row = i / grid_w
col = i % grid_w for b in range(nb_box): # 4th element is objectness score
objectness = netout[int(row)][int(col)][b][4] #objectness = netout[..., :4]
if(objectness.all() <= obj_thresh): continue
# first 4 elements are x, y, w, and h
x, y, w, h = netout[int(row)][int(col)][b][:4]
x = (col + x) / grid_w # center position, unit: image width
y = (row + y) / grid_h # center position, unit: image height
w = anchors[2 * b + 0] * np.exp(w) / net_w # unit: image width
h = anchors[2 * b + 1] * np.exp(h) / net_h # unit: image height
# last elements are class probabilities
classes = netout[int(row)][col][b][5:]
box = BoundBox(x-w/2, y-h/2, x+w/2, y+h/2, objectness, classes) #box = BoundBox(x-w/2, y-h/2, x+w/2, y+h/2, None, classes)
boxes.append(box) return boxesdef correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w):
if (float(net_w)/image_w) < (float(net_h)/image_h):
new_w = net_w
new_h = (image_h*net_w)/image_w else:
new_h = net_w
new_w = (image_w*net_h)/image_h for i in range(len(boxes)):
x_offset, x_scale = (net_w - new_w)/2./net_w, float(new_w)/net_w
y_offset, y_scale = (net_h - new_h)/2./net_h, float(new_h)/net_h
boxes[i].xmin = int((boxes[i].xmin - x_offset) / x_scale * image_w)
boxes[i].xmax = int((boxes[i].xmax - x_offset) / x_scale * image_w)
boxes[i].ymin = int((boxes[i].ymin - y_offset) / y_scale * image_h)
boxes[i].ymax = int((boxes[i].ymax - y_offset) / y_scale * image_h)def do_nms(boxes, nms_thresh):
if len(boxes) > 0:
nb_class = len(boxes[0].classes) else: return
for c in range(nb_class):
sorted_indices = np.argsort([-box.classes[c] for box in boxes]) for i in range(len(sorted_indices)):
index_i = sorted_indices[i] if boxes[index_i].classes[c] == 0: continue
for j in range(i+1, len(sorted_indices)):
index_j = sorted_indices[j] if bbox_iou(boxes[index_i], boxes[index_j]) >= nms_thresh:
boxes[index_j].classes[c] = 0def draw_boxes(image, boxes, labels, obj_thresh):
for box in boxes:
label_str = ''
label = -1
for i in range(len(labels)): if box.classes[i] > obj_thresh:
label_str += labels[i]
label = i
print(labels[i] + ': ' + str(box.classes[i]*100) + '%') if label >= 0:
cv2.rectangle(image, (box.xmin,box.ymin), (box.xmax,box.ymax), (0,255,0), 2)
cv2.putText(image,
label_str + ' ' + str(box.get_score()),
(box.xmin, box.ymin - 13),
cv2.FONT_HERSHEY_SIMPLEX,
1e-3 * image.shape[0],
(0,255,0), 1) return image
def _main_(args):
weights_path = args.weights
image_path ='C:\\Users\\new\\Desktop\\detect_image'
# set some parameters
net_h, net_w = 416, 416
obj_thresh, nms_thresh = 0.5, 0.45
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", \ "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", \ "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", \ "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", \ "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", \ "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", \ "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", \ "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", \ "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", \ "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # make the yolov3 model to predict 80 classes on COCO
yolov3 = make_yolov3_model() # load the weights trained on COCO into the model
weight_reader = WeightReader(weights_path)
weight_reader.load_weights(yolov3) #这里是待检测的图像
# preprocess the image
image = cv2.imread("C:\\Users\\new\\Desktop\\11.jpg")
image_h, image_w, _ = image.shape
new_image = preprocess_input(image, net_h, net_w) # run the prediction
yolos = yolov3.predict(new_image)
boxes = [] for i in range(len(yolos)): # decode the output of the network
boxes += decode_netout(yolos[i][0], anchors[i], obj_thresh, nms_thresh, net_h, net_w) # correct the sizes of the bounding boxes
correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w) # suppress non-maximal boxes
do_nms(boxes, nms_thresh)
# draw bounding boxes on the image using labels
draw_boxes(image, boxes, labels, obj_thresh)
cv2.namedWindow('image',0)
cv2.imshow('image',image)
cv2.waitKey(0)
# write the image with bounding boxes to file
cv2.imwrite('C:\\Users\\new\\Desktop\\detect_image\\detection.jpg',image) #cv2.imwrite(image_path[:-4] + '_detected' + image_path[-4:], (image).astype('uint8')) if __name__ == '__main__':
args = argparser.parse_args()
_main_(args)


训练之前的配置
这里采用小浣熊的图像进行训练,从coco数据集上可以下载,小浣熊数据,下载好之后通过代码里面的config_raccoon.json来配置数据,如下所示:主要是训练数据的路径以及一些超参数!
{
"model" : {
"min_input_size": 352,
"max_input_size": 448,
"anchors": [17,18, 28,24, 36,34, 42,44, 56,51, 72,66, 90,95, 92,154, 139,281],
"labels": ["raccoon"] },
"train": {
"train_image_folder": "C:\\Users\\new\\Desktop\\raccoon_dataset-master\\images\\",
"train_annot_folder": "C:\\Users\\new\\Desktop\\raccoon_dataset-master\\annotations\\",
"cache_name": "raccoon_train.pkl",
"train_times": 1,
"batch_size": 1,
"learning_rate": 1e-4,
"nb_epochs": 20,
"warmup_epochs": 3,
"ignore_thresh": 0.5,
"gpus": "0,1",
"grid_scales": [1,1,1],
"obj_scale": 5,
"noobj_scale": 1,
"xywh_scale": 1,
"class_scale": 1,
"tensorboard_dir": "log_raccoon",
"saved_weights_name": "raccoon.h5",
"debug": true
},
"valid": {
"valid_image_folder": "",
"valid_annot_folder": "",
"cache_name": "",
"valid_times": 1
}}在该文件中配置好之后到源代码里的gen_anchors中进行配置,这一步主要是上面.json的配置,很简单的!
接下来就是对train.py文件进行配置,同样也是.json文件的配置。以下就是训练数据的代码:train.py
#! /usr/bin/env pythonimport argparseimport osimport numpy as npimport jsonfrom voc import parse_voc_annotationfrom yolo import create_yolov3_model, dummy_lossfrom generator import BatchGeneratorfrom utils.utils import normalize, evaluate, makedirsfrom keras.callbacks import EarlyStopping, ReduceLROnPlateaufrom keras.optimizers import Adamfrom callbacks import CustomModelCheckpoint, CustomTensorBoardfrom utils.multi_gpu_model import multi_gpu_modelimport tensorflow as tf#import kerasfrom keras.models import load_modeldef create_training_instances(
train_annot_folder,
train_image_folder,
train_cache,
valid_annot_folder,
valid_image_folder,
valid_cache,
labels,
):
# parse annotations of the training set
train_ints, train_labels = parse_voc_annotation(train_annot_folder, train_image_folder, train_cache, labels) # parse annotations of the validation set, if any, otherwise split the training set
if os.path.exists(valid_annot_folder):
valid_ints, valid_labels = parse_voc_annotation(valid_annot_folder, valid_image_folder, valid_cache, labels) else:
print("valid_annot_folder not exists. Spliting the trainining set.")
train_valid_split = int(0.8*len(train_ints))
np.random.seed(0)
np.random.shuffle(train_ints)
np.random.seed()
valid_ints = train_ints[train_valid_split:]
train_ints = train_ints[:train_valid_split] # compare the seen labels with the given labels in config.json
if len(labels) > 0:
overlap_labels = set(labels).intersection(set(train_labels.keys()))
print('Seen labels: \t' + str(train_labels) + '\n')
print('Given labels: \t' + str(labels)) # return None, None, None if some given label is not in the dataset
if len(overlap_labels) < len(labels):
print('Some labels have no annotations! Please revise the list of labels in the config.json.') return None, None, None
else:
print('No labels are provided. Train on all seen labels.')
print(train_labels)
labels = train_labels.keys()
max_box_per_image = max([len(inst['object']) for inst in (train_ints + valid_ints)]) return train_ints, valid_ints, sorted(labels), max_box_per_imagedef create_callbacks(saved_weights_name, tensorboard_logs, model_to_save):
makedirs(tensorboard_logs)
early_stop = EarlyStopping(
monitor = 'loss',
min_delta = 0.01,
patience = 5,
mode = 'min',
verbose = 1
)
checkpoint = CustomModelCheckpoint(
model_to_save = model_to_save,
filepath = saved_weights_name,# + '{epoch:02d}.h5',
monitor = 'loss',
verbose = 1,
save_best_only = True,
mode = 'min',
period = 1
)
reduce_on_plateau = ReduceLROnPlateau(
monitor = 'loss',
factor = 0.1,
patience = 2,
verbose = 1,
mode = 'min',
epsilon = 0.01,
cooldown = 0,
min_lr = 0
)
tensorboard = CustomTensorBoard(
log_dir = tensorboard_logs,
write_graph = True,
write_images = True,
)
return [early_stop, checkpoint, reduce_on_plateau, tensorboard]def create_model(
nb_class,
anchors,
max_box_per_image,
max_grid, batch_size,
warmup_batches,
ignore_thresh,
multi_gpu,
saved_weights_name,
lr,
grid_scales,
obj_scale,
noobj_scale,
xywh_scale,
class_scale
):
if multi_gpu > 1: with tf.device('/cpu:0'):
template_model, infer_model = create_yolov3_model(
nb_class = nb_class,
anchors = anchors,
max_box_per_image = max_box_per_image,
max_grid = max_grid,
batch_size = batch_size//multi_gpu,
warmup_batches = warmup_batches,
ignore_thresh = ignore_thresh,
grid_scales = grid_scales,
obj_scale = obj_scale,
noobj_scale = noobj_scale,
xywh_scale = xywh_scale,
class_scale = class_scale
) else:
template_model, infer_model = create_yolov3_model(
nb_class = nb_class,
anchors = anchors,
max_box_per_image = max_box_per_image,
max_grid = max_grid,
batch_size = batch_size,
warmup_batches = warmup_batches,
ignore_thresh = ignore_thresh,
grid_scales = grid_scales,
obj_scale = obj_scale,
noobj_scale = noobj_scale,
xywh_scale = xywh_scale,
class_scale = class_scale
)
# load the pretrained weight if exists, otherwise load the backend weight only
if os.path.exists(saved_weights_name):
print("\nLoading pretrained weights.\n")
template_model.load_weights(saved_weights_name) else: #这里的backend.h5是预训练过的模型,需要自己训练或者下载别人的[训练好的权重](https://1drv.ms/u/s!ApLdDEW3ut5fgQXa7GzSlG-mdza6)
template_model.load_weights("backend.h5", by_name=True)
#这里需要下载好的.h5
if multi_gpu > 1:
train_model = multi_gpu_model(template_model, gpus=multi_gpu) else:
train_model = template_model
optimizer = Adam(lr=lr, clipnorm=0.001)
train_model.compile(loss=dummy_loss, optimizer=optimizer)
return train_model, infer_modeldef _main_(args):
config_path = "./zoo/config_raccoon.json"
with open(config_path) as config_buffer:
config = json.loads(config_buffer.read()) ###############################
# Parse the annotations
###############################
train_ints, valid_ints, labels, max_box_per_image = create_training_instances(
config['train']['train_annot_folder'],
config['train']['train_image_folder'],
config['train']['cache_name'],
config['valid']['valid_annot_folder'],
config['valid']['valid_image_folder'],
config['valid']['cache_name'],
config['model']['labels']
)
print('\nTraining on: \t' + str(labels) + '\n') ###############################
# Create the generators
###############################
train_generator = BatchGenerator(
instances = train_ints,
anchors = config['model']['anchors'],
labels = labels,
downsample = 32, # ratio between network input's size and network output's size, 32 for YOLOv3
max_box_per_image = max_box_per_image,
batch_size = config['train']['batch_size'],
min_net_size = config['model']['min_input_size'],
max_net_size = config['model']['max_input_size'],
shuffle = True,
jitter = 0.3,
norm = normalize
)
valid_generator = BatchGenerator(
instances = valid_ints,
anchors = config['model']['anchors'],
labels = labels,
downsample = 32, # ratio between network input's size and network output's size, 32 for YOLOv3
max_box_per_image = max_box_per_image,
batch_size = config['train']['batch_size'],
min_net_size = config['model']['min_input_size'],
max_net_size = config['model']['max_input_size'],
shuffle = True,
jitter = 0.0,
norm = normalize
) ###############################
# Create the model
###############################
if os.path.exists(config['train']['saved_weights_name']):
config['train']['warmup_epochs'] = 0
warmup_batches = config['train']['warmup_epochs'] * (config['train']['train_times']*len(train_generator))
os.environ['CUDA_VISIBLE_DEVICES'] = config['train']['gpus']
multi_gpu = len(config['train']['gpus'].split(','))
train_model, infer_model = create_model(
nb_class = len(labels),
anchors = config['model']['anchors'],
max_box_per_image = max_box_per_image,
max_grid = [config['model']['max_input_size'], config['model']['max_input_size']],
batch_size = config['train']['batch_size'],
warmup_batches = warmup_batches,
ignore_thresh = config['train']['ignore_thresh'],
multi_gpu = multi_gpu,
saved_weights_name = config['train']['saved_weights_name'],
lr = config['train']['learning_rate'],
grid_scales = config['train']['grid_scales'],
obj_scale = config['train']['obj_scale'],
noobj_scale = config['train']['noobj_scale'],
xywh_scale = config['train']['xywh_scale'],
class_scale = config['train']['class_scale'],
) ###############################
# Kick off the training
###############################
callbacks = create_callbacks(config['train']['saved_weights_name'], config['train']['tensorboard_dir'], infer_model)
train_model.fit_generator(
generator = train_generator,
steps_per_epoch = len(train_generator) * config['train']['train_times'],
epochs = config['train']['nb_epochs'] + config['train']['warmup_epochs'],
verbose = 2 if config['train']['debug'] else 1,
callbacks = callbacks,
workers = 4,
max_queue_size = 8
) # make a GPU version of infer_model for evaluation
if multi_gpu > 1:
infer_model = load_model(config['train']['saved_weights_name']) ###############################
# Run the evaluation
###############################
# compute mAP for all the classes
average_precisions = evaluate(infer_model, valid_generator) # print the score
for label, average_precision in average_precisions.items():
print(labels[label] + ': {:.4f}'.format(average_precision))
print('mAP: {:.4f}'.format(sum(average_precisions.values()) / len(average_precisions)))
if __name__ == '__main__':
argparser = argparse.ArgumentParser(description='train and evaluate YOLO_v3 model on any dataset')
argparser.add_argument('-c ', '--conf', help='path to configuration file')
args = argparser.parse_args()
_main_(args)测试结果
由于是在raccoon数据集上进行训练(后面有数据集下载链接),在这里只对小浣熊进行测试,通过源代码中的predict.py文件进行测试,测试结果如下:



注意
由于图像比较大,自己的笔记本在训练的时候总是显示显存不够,所以最好找个显卡比较好的电脑!!!
源代码链接
keras-yolo3-master源代码 ,yolo3模型,训练好的权重backend.h5,可以直接运行,基于tensorflow-1.2.0 +keras 2.1.2。注意:以上代码只是源代码中的yolo3_one_to_detect_them_all.py和train.py文件,代码中还有评估evaluate过程。





