
线程池是并发编程在生产环境最常被使用到的一个组件
核心参数
在使用好线程池之前,必须明白如何构建线程池,想要明白如何构建线程池,则必须明确构建线程池所需的 5 个参数
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor( 2/*实际运行线程数 (不管它们创建以后是不是空闲的。线程池需要保持 corePoolSize 数量的线程)*/, 3/*最多允许创建的线程数*/, 0L /* 让线程存活的时间 0为永久 */, TimeUnit.SECONDS, new ArrayBlockingQueue<>(4)/* 线程池的内部队列 */, Executors.defaultThreadFactory()/* 产生线程的方式 */, new ThreadPoolExecutor.DiscardOldestPolicy() /* 线程池满时的拒绝策略 */);
比较不容易区分的就是核心线程数(corePoolSize)跟最大线程数(maxPoolSize)
当任务提交之后,线程池判断当前线程数是否超过核心线程数,若没有超过,则创建线程运行提交的这个任务。
若超过了核心线程数,则把任务丢到阻塞队列里面,如果阻塞队列满了,就判断线程数否超过最大线程数,如果没有超过,继续创建线程执行,如果超过了,就按照饱和策略来决定如何处理这个任务。
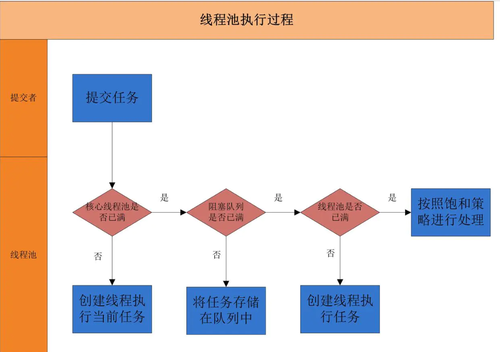
为什么需要存在一个队列来缓存任务?直接根据线程数判断线程池慢了然后执行饱和策略不行吗?
通过反问这两个问题来思考为什么线程池的设计要引入缓存队列,假设没有缓存队列的存在,一旦线程池满了,任务就被放弃或者通过退化成直接运行的方式执行,这样就特别没有弹性,线程池满的话,任务被拒绝,但是一会儿任务执行完了,线程池的线程都处于空闲状态,这势必就造成了资源利用效率低下。
另外一个引入线程池的原因需要了解线程池线程执行提交任务的原理才能知道,假设一个线程执行完某个任务之后,它是会去调用缓存队列的 take 方法来继续获取下一个任务,如果没有下一个任务,由于阻塞队列的特性,它就会一直阻塞在那边。
// java.util.concurrent.ThreadPoolExecutor#getTasktry {
// 超过keepAliveTime时间取不到数据就返回,此时线程不再运行,结束了,JVM会回收掉
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;} catch (InterruptedException retry) {
timedOut = false;}设想一下,如果不借助阻塞队列,你会如何设计线程池?任务执行完,就马上销毁线程,然后下一个任务来了,继续创建线程?那这样线程池降低线程创建销毁的目的就没法实现了。
所以这就是缓存队列存在的原因。
饱和策略
饱和策略上面提到过,当线程池线程数超过最大线程数时,线程池要如何来处理你提交的任务
目前 JDK 的 ThreadPoolExecutor 提供了四种策略
AbortPolicy:默认的饱和策略 抛出RejectedExecutionException
CallerRunsPolicy:回退到由提交者执行
DiscardPolicy:丢弃掉当前提交的任务
DiscardOldestPolicy:丢弃掉等待队列中最老的任务
这四种策略基本涵盖了大部分的使用场景,但是如果有一些比较特殊的需求,诸如这个线程池满了,我就帮你提交到另外一个线程池之类的,类似于工作窃取,都可以通过继承 RejectedExecutionHandler 来实现自己的饱和策略
线程工厂
线程工厂则是定义了线程池如何创建一个新线程,一般这个用得最多的就是用来设置线程名字。
public static final ThreadFactory SHORT_LIFE_POOL_THREAD_FACTORY = new ThreadFactory() {
private final AtomicInteger atomicInteger = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "short-life-thread-pool-" + atomicInteger.incrementAndGet());
}};线程名字是很重要的,这不仅在做线程池隔离的时候区分不用的业务,在通过日志排错里,也是很有用的。
比如对于没有链路追踪基础设施的单体应用,为了在大量的日志中找到自己所需的日志。就需要能以某种情况准确唯一标识日志,如
log.info("业务上下文-事件xxx xxxx")同时为了追踪执行流或者数据流,通常都需要在某条日志之前或之后追踪日志,此时可以使用日志纪录里的线程名称来明确整条执行链路,如下面的bussiness-task1/bussiness-task2…
2022年1月21日20:30:21 INFO --- [-] [main] wang.ismy.xxx 日志内容12022年1月21日20:30:21 INFO --- [-] [bussiness-task1] wang.ismy.xxx 日志内容22022年1月21日20:30:21 INFO --- [-] [bussiness-task2] wang.ismy.xxx 日志内容3...
应用场景
针对核心线程数及最大线程数还有队列的设置,有一些场景化的配置可以参考:
coreSize == maxSize
让线程一下子增加到 maxSize,并且不要回收线程,防止线程回收,避免不断增加回收的损耗
maxSize 无界 + SynchronousQueue
当任务被消费时,才会返回,这样请求就能够知道当前请求是已经在被消费了,如果是其他的队列的话,我们只知道任务已经被提交成功了,但无法知道当前任务是在被消费中,还是正在队列中堆积,比较消耗资源,大量请求到来时,我们会新建大量的线程来处理请求
maxSize 有界 + Queue 无界
对实时性要求不大,但流量忽高忽低的场景下,可以使用这种方式,当流量高峰时,大量的请求被阻塞在队列中,对于请求的实时性难以保证
maxSize 有界 + Queue 有界
把队列从无界修改成有界,只要排队的任务在要求的时间内,能够完成任务即可
动态线程池
对于我们创建线程池,除了核心线程数及最大线程数,其他另外的参数基本可以固定,但这两个参数对于不同的业务场景、不同的机器配置是不尽相同的
在《Java 并发编程实战》 里面提到了可以根据 CPU 核心数及业务是 IO 密集型还是 CPU 密集型来设置这样的一个参数,还提出了一个公式
Ncpu = CPU数量 Ucpu = 预期CPU使用率 W/C = 等待时间/计算时间
最优大小等于 Ncpu * Ucpu * (1 + W/C)
但这个公式过于理想,在真实的生产环境中,这些时间不仅很难计算,而且 IO 密集型还是 CPU 密集型也不是一刀就能划分开的, 更多地是靠场景根据经验来设置各个参数 或是根据监控来动态调整参数以观察效果
所以可以通过动态设置线程池的参数来动态调整它以适应业务
executor.setCorePoolSize(64);executor.setMaximumPoolSize(128);
但是这里比较特殊的就是缓存队列的设置,JDK自带的阻塞队列一般就是创建后就不能再更改大小,可以通过继承阻塞队列实现,并提供相对应的扩缩容 API 来实现
线上遇到的一些问题
阿里规范中提到了缓存队列一定要用有界队列,否则在生产速度跟不上消费速度的情况下,就会有可能造成资源耗尽应用挂掉的风险,这个问题由于众所周知,所以并没有出现过
在生产环境中,关于线程池,主要出现了这么几个
任务饥饿
某个业务拥有大量短而多的任务,和另外一个需要有时效性的任务公用了一个线程池,结果就导致了时效性任务一直在队列排队,虽然最终也会轮到它执行,但已经过了有效的时间,任务也就变得没有意义。
这个问题其实还是因为没有做好线程池隔离,不同类型的任务混杂在同一个线程池是有风险的,但又若一个业务对应一个线程池成本又似乎太高,所以业界通用的做法有:
读写隔离:查询和写入不公用线程池,如果公用的话,当查询量很大时,写入的请求可能会到队列中去排队,无法及时被处理
读共享,写隔离:每个写入业务场景都独自使用自己的线程池,绝不共用,这样在业务治理、限流、熔断方面都比较容易 多个查询业务场景是可以公用线程池的
execute&submit
这个问题是使用了submit时,当执行的任务出现异常,在日志文件却没有发现相关异常栈
主要原因是 submit 会将 Runnable 包装成 FutureTask
FutureTask 这个类当执行代码发生异常,是不会 输出异常栈的,而是会把异常记录一下,供 FutureTask 的客户代码获取错误信息
// FutureTasktry {
result = c.call();
ran = true;} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);}// 客户代码task.get() // 结果或者异常



