
来自面试官一面MySQL索引的连续灵魂拷问
本期主要面试考点
面试官考点之谈谈你对索引的理解?
面试官考点之解释一下计算机层面索引快的原因?
面试官考点之为什么不使用哈希结构作为索引结构?
面试官考点之为什么不使用二叉树作为索引结构?
面试官考点之为什么不使用B-Tree,而是B+Tree?
面试官考点之索引是加速查询,那么是否应该给表尽可能建立多的索引列?
我是肥哥,一名不专业的面试官!
我是囧囧,一名积极找工作的小菜鸟,囧囧表示:面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!!

面试官考点之谈谈你对索引的理解?
谈到索引,最先联想到的大概就是字典目录,根据MySQL官方定义,索引是用来帮助MySQL高效获取数据的一种数据结构。
本质上:索引是一种有序的快速查找的数据结构,用来快速高效的查找数据。
简单来说,可以类比字典目录,火车车次表。
面试官考点之解释一下计算机层面索引快的原因?
计算机从磁盘获取数据,加载到内存期间,一般都要经历3个常规的耗时过程:
1、寻道(时间):确定要读的数据在哪个磁道耗费的时间
2、旋转延迟(时间):确定要读的数据在磁道上的哪个扇区耗费的时间
3、数据传输(时间):数据加载到内存耗费的时间
每次加载数据,我们称其为一次磁盘IO,每一次IO操作耗费时间 = 寻道 + 旋转延迟 + 数据传输(时间短暂,可以忽略不计)。
事实上实际加载数据到内存的时间非常短暂,一次IO操作主要的耗时来自寻道和旋转延迟。
总体来说,一般一次IO操作,耗时大概只有几ms。假如是4ms,虽然看起来很短暂,但是数据库百万级别的数据加载一遍,就需要4000s,对于一个系统来说,简直是毁灭级别的。
我们需要的就是减少磁盘IO的次数,这也是使用索引的意义所在!!!索引能够保证在亿级别的数据,只需要2~4次磁盘IO,这无疑是个福音!
面试官考点之为什么不使用哈希结构作为索引结构?
一般正常的业务场景中,通常查询多数是范围查询 类似:
select id, name, age from sys_user where age between 18 and 28;
哈希结构作为索引,那么存储引擎就会为每一行表记录计算出哈希值,哈希索引存储的就是HASH码;
HASH码直接随机生成,并没有规律
没有规律的HASH码,导致数据随机分布存储,这就导致即使是两个很相近的行记录,极大可能也会被分配到不同的桶(磁盘块)中。
最坏的情况下每查找一条记录,都要进行一次磁盘IO (可怕)。
优点,哈希结构这样key-val 键值对的形式对于精确查找非常敏感,对全值匹配很友好,所以单条记录查询效率非常高,时间复杂度为 1,但是我们日常业务来说,最常用的还是范围搜索,所以不哈希结构适合。
记住一点即可:Hash索引适合精确查找,全值匹配,不适合范围查找。
MySQL目前有Memory引擎和NDB引擎支持Hash索引。
面试官考点之为什么不使用二叉树作为索引结构?
首先观察一下二叉树结构
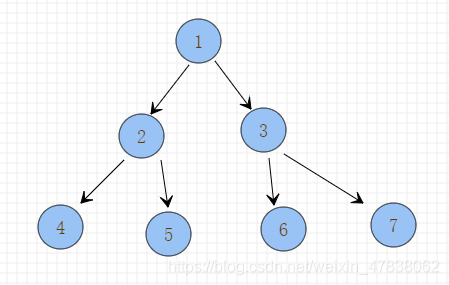
二叉树最多有两个子节点,这种结构导致树的高度会很高,增加IO次数,特殊情况下可能化为链表结构,相当于全表扫描,全量磁盘IO。
假设二叉树结构作为索引,理想情况下是一颗完全二叉树,那么具有n个节点的完全二叉树深度为log2x+1
(其中x表示不大于n的最大整数)
如果一个数据在二叉树结构的100层,那么为了查找到此数据,需要进行100次磁盘IO。更糟糕情况下,二叉树会退化成链表结构,既,斜二叉树。
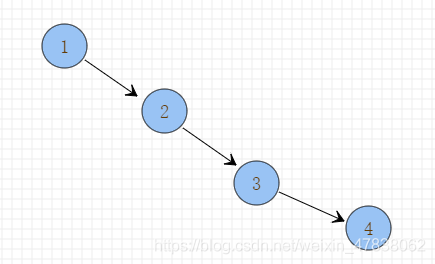
类似的平衡二叉树,高度也很高。
面试官考点之为什么不使用B-Tree,而是B+Tree?
既然二叉树结构树高度很高,导致查询时磁盘IO增加,那B-Tree 呢?B-Tree可以存储更多的数据,高度更低,为什么不选择?而是B+Tree?
B-Tree是多路平衡搜索树,相比二叉树结构,可以极大的优化磁盘IO次数,但是B-Tree每个节点中不仅包含数据的key(索引值),还有data(整行记录),使用B-Tree结构,优点是找到索引就代表找到了数据记录。
既然如此为什么不使用B-Tree结构?还是老问题,磁盘IO数!!!
我们知道MySQL读取数据是以页为单位(磁盘块),每页(或者说每个磁盘块)的存储空间是有限的
如果data 很大,将会导致每页存储的索引数量很小
所以数据表存储的数据量很大的时候同样会导致 B-Tree的深度很大,增大查询时的磁盘I/O次数,进而影响查询效率。
再说到B+Tree,B+Tree是对B-Tree 的一种优化结构,使其更适合实现外存储索引结构
1、非叶子节点只存储键值信息(索引信息)
2、所有的数据记录都按照键值大小顺序存放在同一层的叶子节点上
好处:B+Tree的非叶子节点只存储键值信息,那么每一页能存储更多的索引,树的高度被压缩到很低,磁盘IO次数更小,一般情况下2~4次IO,即可查询到想要的记录。
而且因为表数据都是顺序存储在B+Tree结构的叶子节点,所以对于范围查找很友好,效率高!
面试官考点之索引是加速查询,那么是否应该给表尽可能建立多的索引列?
虽然索引的优势是加快查询效率,减少磁盘IO次数,但是盲目创建过多索引,大大增加了维护索引的时间成本和空间成本。
首先说一下索引的好处
1、减少IO次数,提高-检索效率
2、降低数据排序成本,可以减少CPU消耗
时间成本
因为索引是有序的快速查找结构,要维护索引的这个快速查找且有序特性,需要不断的进行调整,而调整就需要时间成本。
创建索引和维护索引要耗费时间,当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
而且这种时间成本随着数据量的增加而增加!
空间成本
其次,每一个索引都是一棵B+Tree,保存索引和指向实体表的引用,需要占据空间。
如果建立的是聚簇索引,数据和主键都保存在索引文件中,则需要更大的空间成本。





