
@TOC
技术选型:Mysql8 + go-mysql-transfer + ElasticSearch7.13
简介
go-mysql-transfer是一款MySQL数据库实时增量同步工具。需要GO环境
能够监听MySQL二进制日志(Binlog)的变动,将变更内容形成指定格式的消息,实时发送到接收端。从而在数据库和接收端之间形成一个高性能、低延迟的增量数据同步更新管道。
工作需要研究了下阿里开源的MySQL Binlog增量订阅消费组件canal,其功能强大、运行稳定,但是有些方面不是太符合需求,主要有如下三点:
1、需要自己编写客户端来消费canal解析到的数据
2、server-client模式,需要同时部署server和client两个组件,我们的项目中有6个业务数据库要实时同步到redis,意味着要多部署12个组件,硬件和运维成本都会增加。
3、从server端到client端需要经过一次网络传输和序列化反序列化操作,然后再同步到接收端,感觉没有直接怼到接收端更高效。
前提条件
-
MySQL 服务器需要开启 row 模式的 binlog。
-
因为要使用 mysqldump 命令,因此该进程的所在的服务器需要部署这一工具。
-
这一工具使用 GoLang 开发,需要 Go 1.9+ 的环境进行构建。
-
新版(7.13+)的本地es必须关闭安全模式才可以
yml配置文件添加
xpack.security.enabled: false -
可用的 MySQL、Elasticsearch 以及 Kibana 实例。权限需要大一些。
- mysql binlog必须是ROW模式
- 要同步的mysql数据表必须包含主键,否则直接忽略,这是因为如果数据表没有主键,UPDATE和DELETE操作就会因为在ES中找不到对应的document而无法进行同步
- 不支持程序运行过程中修改表结构
- 要赋予用于连接mysql的账户RELOAD权限以及REPLICATION权限, SUPER权限
GRANT REPLICATION SLAVE ON *.* TO 'elastic'@'IP'; GRANT RELOAD ON *.* TO 'elastic'@'IP'; UPDATE mysql.user SET Super_Priv='Y' WHERE user='elastic' AND host='IP';
特性
1、简单,不依赖其它组件,一键部署
2、集成多种接收端,如:Redis、MongoDB、Elasticsearch、RocketMQ、Kafka、RabbitMQ、HTTP API等,无需编写客户端,开箱即用
3、内置丰富的数据解析、消息生成规则,支持模板语法
4、支持Lua脚本扩展,可处理复杂逻辑,如:数据的转换、清洗、打宽
5、集成Prometheus客户端,支持监控、告警
6、集成Web Admin监控页面
7、支持高可用集群部署
8、数据同步失败重试
9、支持全量数据初始化
与同类工具比较
| 特色 | Canal | mysql_stream | go-mysql-transfer | Maxwell |
|---|---|---|---|---|
| 开发语言 | Java | Python | Golang | Java |
| 高可用 | 支持 | 支持 | 支持 | 支持 |
| 接收端 | 编码定制 | Kafka等(MQ) | Redis、MongoDB、Elasticsearch、RabbitMQ、Kafka、RocketMQ、HTTP API 等 | Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件等 |
| 全量数据初始化 | 不支持 | 支持 | 支持 | 支持 |
| 数据格式 | 编码定制 | Json(固定格式) | Json(规则配置) 模板语法 Lua脚本 | JSON |
| 性能(4-8TPS) |
实现原理
1、go-mysql-transfer将自己伪装成MySQL的Slave,
2、向Master发送dump协议获取binlog,解析binlog并生成消息
3、将生成的消息实时、批量发送给接收端
如下图所示:
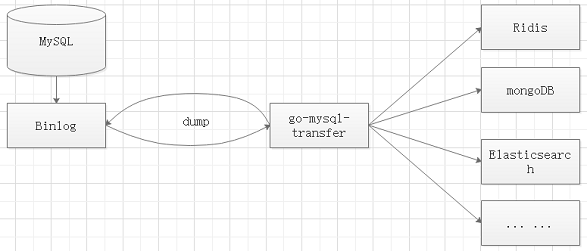
go-mysql部署运行
开启MySQL的binlog
修改app.yml
命令行运行
Windows直接运行 go-mysql-transfer.exe
Linux执行 nohup go-mysql-transfer &
监控
go-mysql-transfer支持两种监控模式,Prometheus和内置的Web Admin
相关配置:
# web admin相关配置
enable_web_admin: true #是否启用web admin,默认false
web_admin_port: 8060 #web监控端口,默认8060
直接访问127.0.0.1:8060 可以看到监控界面同步数据到Elasticsearch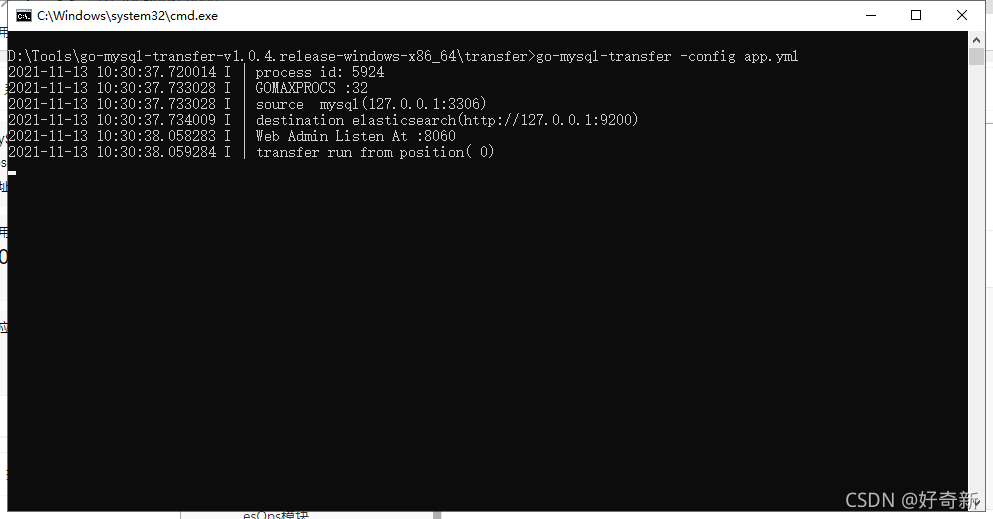
同步数据到Elasticsearch
配置文件——相关配置如下:
# app.yml
#目标类型
target: elasticsearch
#elasticsearch连接配置
es_addrs: 127.0.0.1:9200 #连接地址,多个用逗号分隔
es_version: 7 # Elasticsearch版本,支持6和7、默认为7
#es_password: # 用户名
#es_version: # 密码
目前支持Elasticsearch6、Elasticsearch7两个版本
基于规则同步
相关配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
#column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
#Elasticsearch相关
es_index: user_index #Index名称,可以为空,默认使用表(Table)名称
#es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
# -
# column: REMARK #数据库列名称
# field: remark #映射后的ES字段名称
# type: text #ES字段类型
# analyzer: ik_smart #ES分词器,type为text此项有意义
# #format: #日期格式,type为date此项有意义
# -
# column: USER_NAME #数据库列名称
# field: account #映射后的ES字段名称
# type: keyword #ES字段类型
规则示例
t_user表,数据如下:
示例一
使用上述配置
自动创建的Mapping,如下:
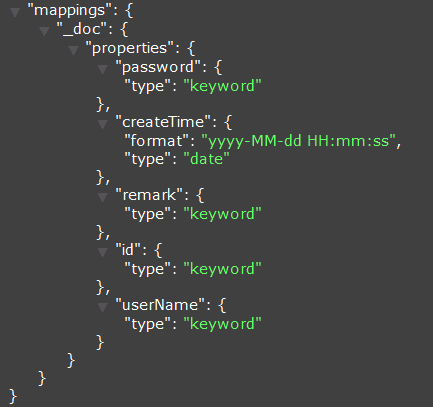
同步到Elasticsearch的数据如下:
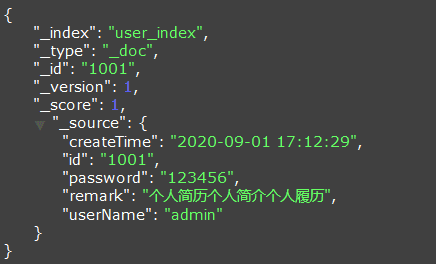
示例二
配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
#Elasticsearch相关
es_index: user_index #Index名称,可以为空,默认使用表(Table)名称
es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
-
column: REMARK #数据库列名称
field: remark #映射后的ES字段名称
type: text #ES字段类型
analyzer: ik_smart #ES分词器,type为text此项有意义
#format: #日期格式,type为date此项有意义
-
column: USER_NAME #数据库列名称
field: account #映射后的ES字段名称
type: keyword #ES字段类型
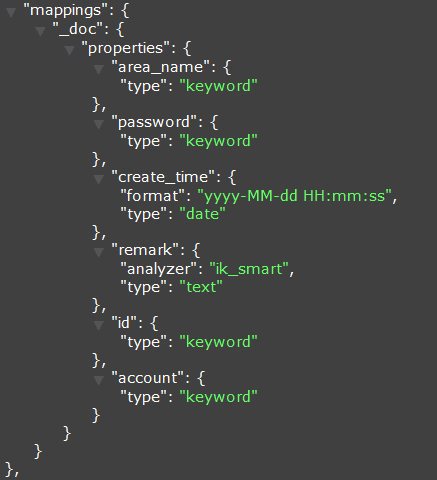
es_mappings配置项表示定义索引的mappings(映射关系),不定义es_mappings则使用列类型自动创建索引的mappings(映射关系)。
创建的Mapping,如下:
同步到Elasticsearch的数据如下: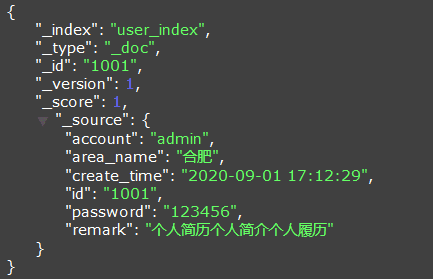
基于Lua脚本同步
使用Lua脚本可以实现更复杂的数据处理逻辑,go-mysql-transfer支持Lua5.1语法
Lua示例
t_user表,数据如下:

示例一
引入Lua脚本:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
order_by_column: id #排序字段,存量数据同步时不能为空
lua_file_path: lua/t_user_es.lua #lua脚本文件
es_index: user_index #Elasticsearch Index名称,可以为空,默认使用表(Table)名称
es_mappings: #索引映射,可以为空,为空时根据数据类型自行推导ES推导
-
field: id #映射后的ES字段名称
type: keyword #ES字段类型
-
field: userName #映射后的ES字段名称
type: keyword #ES字段类型
-
field: password #映射后的ES字段名称
type: keyword #ES字段类型
-
field: createTime #映射后的ES字段名称
type: date #ES字段类型
format: yyyy-MM-dd HH:mm:ss #日期格式,type为date此项有意义
-
field: remark #映射后的ES字段名称
type: text #ES字段类型
analyzer: ik_smart #ES分词器,type为text此项有意义
-
field: source #映射后的ES字段名称
type: keyword #ES字段类型
其中,
es_mappings 表示索引的mappings(映射关系),不定义es_mappings则根据字段的值自动创建mappings(映射关系)。根据es_mappings 生成的mappings如下:

Lua脚本:
local ops = require("esOps") --加载elasticsearch操作模块
local row = ops.rawRow() --当前数据库的一行数据,table类型,key为列名称
local action = ops.rawAction() --当前数据库事件,包括:insert、update、delete
local id = row["ID"] --获取ID列的值
local userName = row["USER_NAME"] --获取USER_NAME列的值
local password = row["PASSWORD"] --获取USER_NAME列的值
local createTime = row["CREATE_TIME"] --获取CREATE_TIME列的值
local remark = row["REMARK"] --获取REMARK列的值
local result = {} -- 定义一个table,作为结果集
result["id"] = id
result["userName"] = userName
result["password"] = password
result["createTime"] = createTime
result["remark"] = remark
result["source"] = "binlog" -- 数据来源
if action == "insert" then -- 只监听新增事件
ops.INSERT("t_user",id,result) -- 新增,参数1为index名称,string类型;参数2为要插入的数据主键;参数3为要插入的数据,tablele类型或者json字符串
end
同步到Elasticsearch的数据如下:
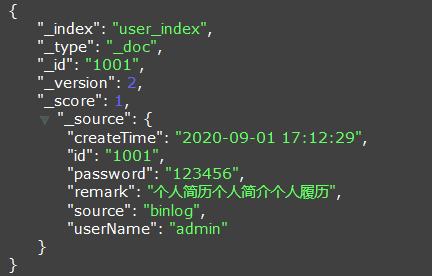
示例二
引入Lua脚本:
schema: eseap #数据库名称
table: t_user #表名称
lua_file_path: lua/t_user_es2.lua #lua脚本文件
未明确定义index名称、mappings,es会根据值自动创建一个名为t_user的index。
使用如下脚本:
local ops = require("esOps") --加载elasticsearch操作模块
local row = ops.rawRow() --当前数据库的一行数据,table类型,key为列名称
local action = ops.rawAction() --当前数据库事件,包括:insert、update、delete
local id = row["ID"] --获取ID列的值
local userName = row["USER_NAME"] --获取USER_NAME列的值
local password = row["PASSWORD"] --获取USER_NAME列的值
local createTime = row["CREATE_TIME"] --获取CREATE_TIME列的值
local result = {} -- 定义一个table,作为结果集
result["id"] = id
result["userName"] = userName
result["password"] = password
result["createTime"] = createTime
result["remark"] = remark
result["source"] = "binlog" -- 数据来源
if action == "insert" then -- 只监听新增事件
ops.INSERT("t_user",id,result) -- 新增,参数1为index名称,string类型;参数2为要插入的数据主键;参数3为要插入的数据,tablele类型或者json字符串
end
同步到Elasticsearch的数据如下:
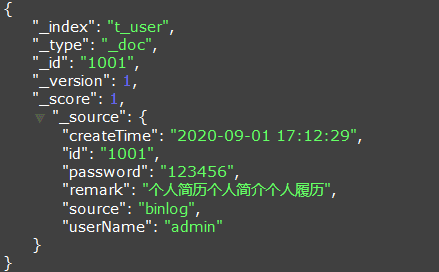
esOps模块
提供的方法如下:
- INSERT: 插入操作,如:ops.INSERT(index,id,result)。参数index为索引名称,字符串类型;参数index为要插入数据的主键;参数result为要插入的数据,可以为table类型或者json字符串
- UPDATE: 修改操作,如:ops.UPDATE(index,id,result)。参数index为索引名称,字符串类型;参数index为要修改数据的主键;参数result为要修改的数据,可以为table类型或者json字符串
- DELETE: 删除操作,如:ops.DELETE(index,id)。参数index为索引名称,字符串类型;参数id为要删除的数据主键,类型不限;
同步数据到RocketMQ
RocketMQ配置
相关配置如下:
# app.yml
target: rocketmq #目标类型
#rocketmq连接配置
rocketmq_name_servers: 127.0.0.1:9876 #rocketmq命名服务地址,多个用逗号分隔
#rocketmq_group_name: transfer_test_group #rocketmq group name,默认为空
#rocketmq_instance_name: transfer_test_group_ins #rocketmq instance name,默认为空
#rocketmq_access_key: RocketMQ #访问控制 accessKey,默认为空
#rocketmq_secret_key: 12345678 #访问控制 secretKey,默认为空
基于规则同步
相关配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
#column_lower_case:false #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#column_mappings: CARD_NO=sfz #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
#default_column_values: source=binlog,area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: json #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}|{{.REAL_NAME}}|{{if eq .STATUS 0}}停用{{else}}启用{{end}}'
#rocketmq相关
rocketmq_topic: transfer_test_topic #rocketmq topic,可以为空,默认使用表名称
#reserve_raw_data: false #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
其中,
value_encoder表示值编码格式,支持json、kv-commas、v-commas三种格式,不填写默认为json,具体如下表:
| 格式 | 说明 | 举例 |
|---|---|---|
| json | json | {“id”: “1001”,“userName”: “admin”,“password”: “123456”, “createTime”: “2020-07-20 14:29:19”} |
| kv-commas | key-value逗号分隔 | id=1001,userName=admin,password=123456,createTime=2020-07-20 14:29:19 |
| v-commas | value逗号分隔 | 1001,admin,123456,2020-07-20 14:29:19 |
value_formatter表示值的格式化表达式,具体模板语法参见"表达式模板"章节,当value_formatter不为空时value_encoder无效。
reserve_raw_data表示是否保留update之前的数据,即保留修改之前的老数据,默认不保留
示例
t_user表,数据如下:
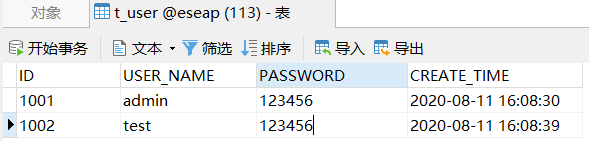
在RocketMQ中创建名称为transfer_test_topic的topic,注意topic名称一定要和rule规则中rocketmq_topic配置项的值一致
示例一
使用上述配置
insert事件,同步到RocketMQ的数据如下:
update事件,同步到RocketMQ的数据如下:
reserve_raw_data设置为true,update事件,同步到RocketMQ的数据如下:
其中,raw属性为update之前的旧数据
delete事件,同步到RocketMQ的数据如下:
示例二
配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: json #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}|{{.REAL_NAME}}|{{if eq .STATUS 0}}停用{{else}}启用{{end}}'
#rocketmq相关
rocketmq_topic: transfer_test_topic #rocketmq topic,可以为空,默认使用表名称
#reserve_raw_data: false #保留update之前的数据,针对rocketmq、kafka、rabbitmq有用;默认为false
其中,
column_mappings表示对列名称进行重新映射
insert事件,同步到RocketMQ的数据如下:
其中,属性名称USER_NAME变为了account
示例三
配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
#order_by_column: id #排序字段,存量数据同步时不能为空
column_lower_case: true #列名称转为小写,默认为false
#column_upper_case:false#列名称转为大写,默认为false
#column_underscore_to_camel: true #列名称下划线转驼峰,默认为false
# 包含的列,多值逗号分隔,如:id,name,age,area_id 为空时表示包含全部列
#include_columns: ID,USER_NAME,PASSWORD
#exclude_columns: BIRTHDAY,MOBIE # 排除掉的列,多值逗号分隔,如:id,name,age,area_id 默认为空
#column_mappings: USER_NAME=account #列名称映射,多个映射关系用逗号分隔,如:USER_NAME=account 表示将字段名USER_NAME映射为account
default_column_values: area_name=合肥 #默认的列-值,多个用逗号分隔,如:source=binlog,area_name=合肥
#date_formatter: yyyy-MM-dd #date类型格式化, 不填写默认yyyy-MM-dd
#datetime_formatter: yyyy-MM-dd HH:mm:ss #datetime、timestamp类型格式化,不填写默认yyyy-MM-dd HH:mm:ss
value_encoder: v-commas #值编码,支持json、kv-commas、v-commas;默认为json
#value_formatter: '{{.ID}}|{{.USER_NAME}}' # 值格式化表达式,如:{{.ID}}|{{.USER_NAME}},{{.ID}}表示ID字段的值、{{.USER_NAME}}表示USER_NAME字段的值
#rocketmq相关
rocketmq_topic: transfer_test_topic #rocketmq topic,可以为空,默认使用表名称
其中,
value_encoder表示消息编码方式
insert事件,同步到RocketMQ的数据如下:
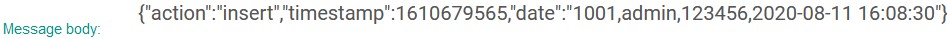
同步数据到Redis
同步数据到MongoDB
同步数据到RocketMQ
同步数据到Kafka
同步数据到RabbitMQ
全量数据导入
Lua脚本
Lua 是一种轻量小巧的脚本语言, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。开发者只需要花费少量时间就能大致掌握Lua的语法,照虎画猫写出可用的脚本。
基于Lua的高扩展性,可以实现更为复杂的数据解析、消息生成逻辑,定制需要的数据格式。
性能
总结
- go-mysql-elasticsearch 实现增量|全量 数据同步
- go-mysql-elasticsearch可以实现同步insert、update、delete操作
- go-mysql-elasticsearch 稳定性差点,出现过无法同步成功的情况,没有详细日志,不便于排查
常见问题
如何重置同步位置(Position)
1、停掉go-mysql-transfer应用
2、在数据库执行 show master status语句,会看到结果如下:
| File | Position | Binlog-Do-DB | Binlog-Ignore-DB |
|---|---|---|---|
| mysql-bin.000025 | 993779648 |
3、使用File和Position列的值
执行命令: ./go-mysql-transfer -config app.yml -position mysql-bin.000025 993779648
4、重启应用: ./go-mysql-transfer -config app.yml
如何同步多张表
使用yml的数组语法:
#一组连词线开头的行,构成一个数组
animal:
- Cat
- Dog
- Goldfish
go-mysql-transfer支持单库多表,也支持多库多表,配置如下:
rule:
-
schema: eseap #数据库名称
table: t_user #表名称
column_underscore_to_camel: true
value_encoder: json
redis_structure: string
redis_key_prefix: USER_
-
schema: eseap #数据库名称
table: t_sign #表名称
column_underscore_to_camel: true
value_encoder: json
redis_structure: string
redis_key_prefix: SIGN_
-
schema: gojob #数据库名称
table: t_triggered #表名称
column_underscore_to_camel: true
value_encoder: json
redis_structure: string
redis_key_prefix: TRIGGERED_
t_user表和t_sign表属于eseap数据库,t_triggered表属于gojob数据库





