
阅读目录
开始
ClownFish是什么?
比手写代码还快的执行速度
简单,一个调用完成你要的全部功能
方便,你需要的代码已经准备好了
定义数据实体类型不再是费力的体力劳动
通用,可以非常简单地实现对多种数据库的支持
灵活,SQL语句放在哪里随便你
XmlCommand是什么?
可监控,图形的工具会告诉你每个数据访问的细节
关于示例代码
最近花了二个月的业余时间重写了我以前的通用数据访问层,由于是重写,所以我给这个项目取了个新名字:ClownFish
如果需要了解ClownFish的使用方法,请点击ClownFish 使用说明
回到顶部
ClownFish是什么?
ClownFish 是我编写的一个通用数据访问层,设计它的目的是为了:
1. 方便在 .net 项目中执行数据访问任务。
2. 避免直接使用ADO.NET带来的一大堆高度类似的繁琐代码。
3. 提供出色的性能满足实际项目需要。
ClownFish 具有以下一些技术特色:
1. 高性能:比手写代码还快的执行速度。
2. 简单:执行查询、将查询结果转成实体列表、获取输出参数。 一个调用完成三个步骤。
3. 方便:提供专用的代码生成器,直接生成调用代码或者实体类型定义代码。
4. 通用:可以非常简单地实现对多种数据库的支持。
5. 灵活:支持存储过程,参数化SQL,或者将SQL语句保存在XML配置文件中。
6. 可监控:提供一个Profiler工具,让您可以随时了解详细的数据库访问情况。
ClownFish不仅继承了老版本的通用数据访问层的全部优点,而且在高性能,方便性,灵活性,以及代码可读性方面有了更出色的设计。
在最新的版本中,ClownFish不仅仅只是一个通用数据访问层,还提供了:专用的代码生成器,XmlCommand管理工具,Profiler工具,它们都会为ClownFish提供更多功能。
ClownFish 是一个可免费的数据访问组件,您可以把它应用在您的 .net 项目中,让它简化您的开发工作。
回到顶部
比手写代码还快的执行速度
提高性能是创建ClownFish项目的重要原因之一,这次优化的主要目标是:比手写代码还快的执行速度。
为了让您对ClownFish的性能留有较深刻的印象,下面我将通过一个实际案例来测试它的速度。
首先,我定义了一个实体类型:
public class OrderInfo{
public int OrderID { get; set; }
public DateTime OrderDate { get; set; }
public decimal SumMoney { get; set; }
public string Comment { get; set; }
public bool Finished { get; set; }
public int ProductID { get; set; }
public decimal UnitPrice { get; set; }
public int Quantity { get; set; }
public string ProductName { get; set; }
public int CategoryID { get; set; }
public string Unit { get; set; }
public string Remark { get; set; }
// 注意:客户信息有可能会是DBNull
public int? CustomerID { get; set; }
public string CustomerName { get; set; }
public string ContactName { get; set; }
public string Address { get; set; }
public string PostalCode { get; set; }
public string Tel { get; set; }}定义这个实体类型,我关注的是它所包含的数据成员的数量,而不是那些数据成员的含义。
我认为这个类型的数据成员数量应该还是比较接近多数实际场景的。
下面再来看看如何从数据库中加载它们:
public static class TestHelper {
public static readonly string QueryText = @"select top (@TopN) d.OrderID, d.OrderDate, d.SumMoney, d.Comment, d.Finished,dt.ProductID, dt.UnitPrice, dt.Quantity, p.ProductName, p.CategoryID, p.Unit, p.Remark,c.CustomerID, c.CustomerName, c.ContactName, c.Address, c.PostalCode, c.Telfrom Orders d inner join [Order Details] dt on d.OrderId = dt.OrderIdinner join Products p on dt.ProductId = p.ProductIdleft join Customers c on d.CustomerId = c.CustomerId"; public static List<OrderInfo> ExecuteQuery(SqlConnection conn, UiParameters uiParam)
{
SqlCommand command = new SqlCommand(QueryText, conn);
command.Parameters.Add("TopN", SqlDbType.Int).Value = uiParam.PageSize;
List<OrderInfo> list = new List<OrderInfo>(uiParam.PageSize);
using( SqlDataReader reader = command.ExecuteReader() ) {
while( reader.Read() )
list.Add(LoadOrderInfo(reader));
}
return list;
}
private static OrderInfo LoadOrderInfo(SqlDataReader reader)
{
OrderInfo info = new OrderInfo();
info.OrderID = (int)reader["OrderID"];
info.OrderDate = (DateTime)reader["OrderDate"];
info.SumMoney = (decimal)reader["SumMoney"];
info.Comment = (string)reader["Comment"];
info.Finished = (bool)reader["Finished"];
info.ProductID = (int)reader["ProductID"];
info.UnitPrice = (decimal)reader["UnitPrice"];
info.Quantity = (int)reader["Quantity"];
info.ProductName = (string)reader["ProductName"];
info.CategoryID = (int)reader["CategoryID"];
info.Unit = (string)reader["Unit"];
info.Remark = (string)reader["Remark"];
object customerId = reader["CustomerID"];
if( customerId != DBNull.Value ) {
info.CustomerID = (int)customerId;
info.CustomerName = (string)reader["CustomerName"];
info.ContactName = (string)reader["ContactName"];
info.Address = (string)reader["Address"];
info.PostalCode = (string)reader["PostalCode"];
info.Tel = (string)reader["Tel"];
}
return info;
}代码中,首先定义了一个参数化的SQL查询语句,然后就是纯手工的ADO.NET代码,循环调用SqlDataReader.Read()方法,再从SqlDataReader中根据字段名称获取数据写入到实体对象的属性中。
这段代码够【手工化】吧? 由于这段代码没用使用反射代码,所以如果想追求性能,我想大家都会这样写。
在我的测试程序中,上面那段代码被下面这段代码调用:
public interface IPerformanceTest : IDisposable{
List<OrderInfo> Run();}[TestMethod("手工代码,SQLSERVER", 1)]public class Test_Adonet_ShareConnection : IPerformanceTest{
private UiParameters uiParam;
private SqlConnection conn;
public Test_Adonet_ShareConnection(UiParameters param)
{
this.uiParam = param;
this.conn = new SqlConnection(Program.ConnectionString);
this.conn.Open();
}
public List<OrderInfo> Run()
{
return TestHelper.ExecuteQuery(conn, uiParam);
}
public void Dispose()
{
conn.Dispose();
}}测试代码应该没有问题吧?
再来看一下使用ClownFish的等效测试代码:
[TestMethod("ClownFish,SQLSERVER", 2)]public class Test_ClownFish_ShareConnection : IPerformanceTest{
private UiParameters uiParam;
private ClownFish.DbContext db;
public Test_ClownFish_ShareConnection(UiParameters param)
{
this.uiParam = param;
this.db = new ClownFish.DbContext(false);
}
public List<OrderInfo> Run()
{
var parameter = new { TopN = uiParam.PageSize };
return ClownFish.DbHelper.FillList<OrderInfo>(
TestHelper.QueryText, parameter, db, ClownFish.CommandKind.SqlTextWithParams);
}
public void Dispose()
{
db.Dispose();
}}比较这二段代码,不难看出:使用 ClownFish 所需的代码量要 少很多。
如果我以下面的测试参数执行性能测试:
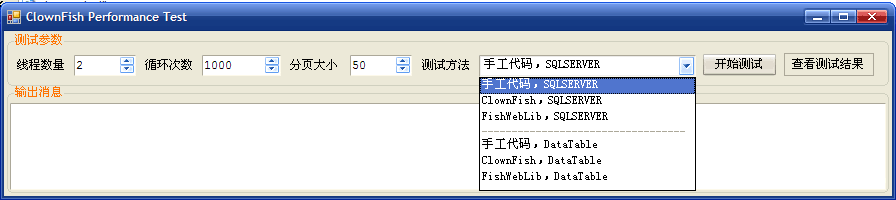
可以得到下面的测试结果:

图形反映的结果很直观:ClownFish 完成测试所需时间比手写代码要略快点。
或许有些人认为:快这么一点,意义不大!
但您想过没有:ClownFish PK的对象是【手工版的专用代码】啊!
其实这个测试并没有把 ClownFish 性能很好的体现出来,因为中间有SQLSERVER的执行时间,以及跨进程的调用开销。这二个因素所花的成本影响了ClownFish的性能优势。
下面,我又做了一组测试:直接从DataTable中加载数据。
我之所以选择这个测试方法,是因为它也是一种常见的使用方案:
我们可以将原始导出到XML文件中,然后使用XML文件做离线数据,这样可以减少对数据库的访问压力。
老版本的通用数据访问层也一直支持这个功能,所以这次就选择了这个测试方法。
说明:实际使用时,我会从XML读出数据到DataTable,供后面使用(转成实体类型只是其中的一种使用数据的方式)。
在测试之前,我们来看一下手工代码是什么样的:
public static class TestHelper{ // 省略前面贴过的代码 public static List<OrderInfo> LoadFromDataTable(DataTable table) { List<OrderInfo> list = new List<OrderInfo>(table.Rows.Count); foreach(DataRow dataRow in table.Rows) list.Add(LoadOrderInfo(dataRow)); return list; } private static OrderInfo LoadOrderInfo(DataRow dataRow) { OrderInfo info = new OrderInfo(); info.OrderID = (int)dataRow["OrderID"]; info.OrderDate = (DateTime)dataRow["OrderDate"]; info.SumMoney = (decimal)dataRow["SumMoney"]; info.Comment = (string)dataRow["Comment"]; info.Finished = (bool)dataRow["Finished"]; info.ProductID = (int)dataRow["ProductID"]; info.UnitPrice = (decimal)dataRow["UnitPrice"]; info.Quantity = (int)dataRow["Quantity"]; info.ProductName = (string)dataRow["ProductName"]; info.CategoryID = (int)dataRow["CategoryID"]; info.Unit = (string)dataRow["Unit"]; info.Remark = (string)dataRow["Remark"]; object customerId = dataRow["CustomerID"]; if( customerId != DBNull.Value ) { info.CustomerID = (int)customerId; info.CustomerName = (string)dataRow["CustomerName"]; info.ContactName = (string)dataRow["ContactName"]; info.Address = (string)dataRow["Address"]; info.PostalCode = (string)dataRow["PostalCode"]; info.Tel = (string)dataRow["Tel"]; } return info; } private static DataTable s_OrderInfoTable; public static DataTable GetOrderInfoTable() { // 把结果用静态变量缓存起来,避免影响测试时间 // 由于在运行测试前,会有一次单独的调用,所以并没有线程安全问题。 if( s_OrderInfoTable == null ) { s_OrderInfoTable = ClownFish.DbHelper.FillDataTable( TestHelper.QueryText, new { TopN = 50 }, ClownFish.CommandKind.SqlTextWithParams); } return s_OrderInfoTable; }}看到这个版本的LoadOrderInfo方法,您会有什么感觉?是不是很无奈?
没办法,ADO.NET就是这样设计的。写这样的代码会让人心烦(这是我的感受)!
测试调用代码:
[TestMethod("手工代码,DataTable", 5)]public class Test_Adonet_LoadDataTable : IPerformanceTest{ public Test_Adonet_LoadDataTable(UiParameters param) { } public void Dispose() { } public List<OrderInfo> Run() { return TestHelper.LoadFromDataTable(TestHelper.GetOrderInfoTable()); } }测试代码应该没有问题吧?
再来看一下使用ClownFish的等效测试代码:
[TestMethod("ClownFish,DataTable", 6)]public class Test_ClownFish_LoadDataTable : IPerformanceTest{ public Test_ClownFish_LoadDataTable(UiParameters param) { } public void Dispose() { } public List<OrderInfo> Run() { return ClownFish.DbHelper.FillListFromTable<OrderInfo>(TestHelper.GetOrderInfoTable()); } }使用 ClownFish 的代码仍然要短很多!
下面继续使用前面的测试参数来运行测试程序,得到以下测试结果:
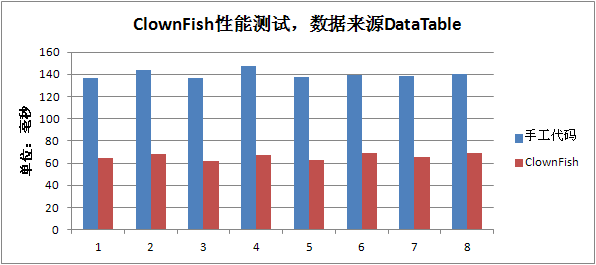
Excel图形直观反映出 ClownFish 的速度要 比手工代码 快一倍 还不止。
看完这二个测试,ClownFish 有没有给您留下二个印象?
1. 代码量很少。
2. 性能很好。
回到顶部
简单,一个调用完成你要的全部功能
调用下面这个存储过程,您需要多少行C#代码?
create procedure InsertProduct( @ProductName nvarchar(50), @CategoryID int, @Unit nvarchar(10), @UnitPrice money, @Quantity int, @Remark nvarchar(max), @ProductID int output) asbegininsert into Products (ProductName, CategoryID, Unit, UnitPrice, Quantity, Remark) values( @ProductName, @CategoryID, @Unit, @UnitPrice, @Quantity, @Remark);set @ProductID = scope_identity();end
在这里,我不想再想写那种手工版本的ADO.NET代码,我懒得写。
来看一下我从示例代码中摘选出来的调用代码吧:
Product product = CreateTestProduct();// 插入一条新记录DbHelper.ExecuteNonQuery("InsertProduct", product);sb.AppendFormat("InsertProduct OK, ProductId is : {0}\r\n", product.ProductID);看到了吧,其实只有一行代码(中间那行)。
再来看一个有分页的吧:
create procedure GetProductByCategoryId( @CategoryID int, @PageIndex int = 0, @PageSize int = 20, @TotalRecords int output)asbegin declare @ResultTable table( RowIndex int, ProductID int, ProductName nvarchar(50), CategoryID int, Unit nvarchar(10), UnitPrice money, Quantity int); insert into @ResultTableselect row_number() over (order by ProductID asc) as RowIndex, p.ProductID, p.ProductName, p.CategoryID, p.Unit, p.UnitPrice, p.Quantityfrom Products as pwhere CategoryID = @CategoryID; select @TotalRecords = count(*) from @ResultTable; select *from @ResultTablewhere RowIndex > (@PageSize * @PageIndex) and RowIndex <= (@PageSize * (@PageIndex+1)); end;
相应的调用代码:
// 查询一个分页列表var parameters = new GetProductByCategoryIdParameters { CategoryID = 1, PageIndex = 0, PageSize = 3, TotalRecords = 0};List<Product> list = DbHelper.FillList<Product>("GetProductByCategoryId", parameters);sb.AppendFormat("存在 {0} 条符合条件的记录。条件:CategoryID = {1}\r\n", parameters.TotalRecords, parameters.CategoryID);还是 一个调用 就能完成全部的数据库访问工作。
老版本的通用数据访问层有这样一个设计目标:
调用存储过程,不管输入参数多么复杂,不管有多少输出参数,包含转换结果集到实体列表,只需要一行C#代码。
这一优点在ClownFish中得到了继承:简单,一个调用完成你要的全部功能。
回到顶部
方便,你需要的代码已经准备好了
看到前面的那段演示代码,你会不会想:我还要定义一个GetProductByCategoryIdParameters类型啊,太麻烦了!
真是那样吗? 请看下面的截图:
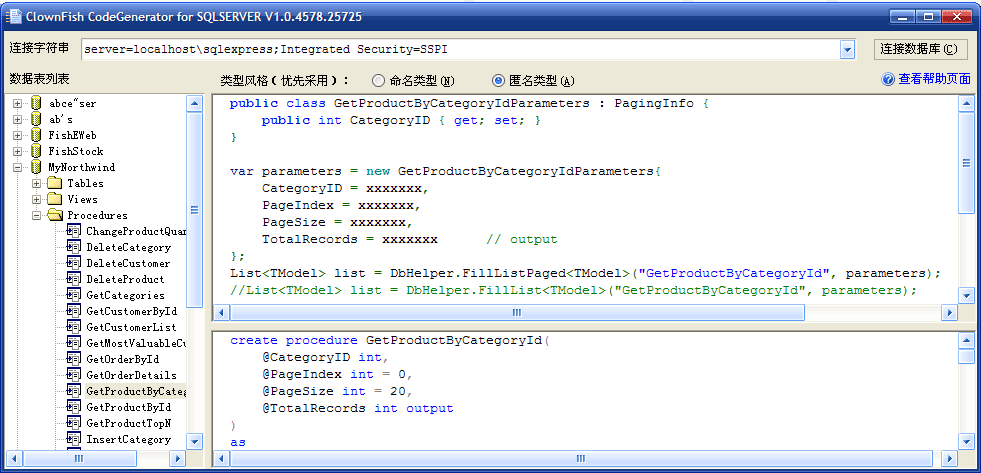
注意:ClownFish并非仅仅支持存储过程,后面将要介绍的XmlCommand也有同样好的支持。
在工具中,不仅可以直接查看存储过程代码,还能生成调用代码。
工具生成二个调用代码,你可以选择其中的一个(因为我不知道你需要哪个)。
说明:调用GetProductByCategoryId需要定义一个类型是因为它包含了输出参数,如果没有输出参数,工具会生成匿名类型:
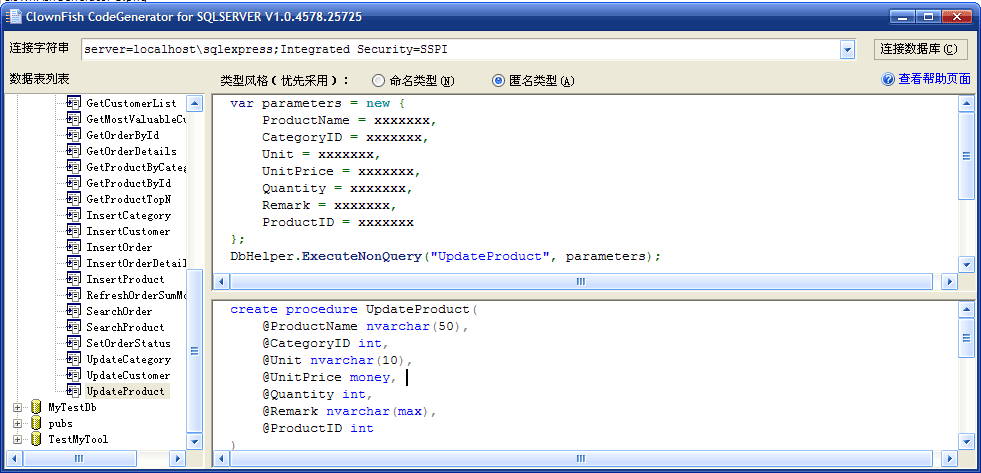
接下来的事情我想大家都知道该怎么做:把工具生成的代码COPY到项目中,修改一下调用参数就好了。
回到顶部
定义数据实体类型不再是费力的体力劳动
对于喜欢使用数据实体类型的人来说,手工定义这些类型是件费力且枯燥的体力劳动。
现在好了,ClownFish 的生成器可以减轻你的工作负担:

还记得本文一开始的那个OrderInfo类型吗,它是根据一个查询语句生成的:

说明:根据查询生成的类型,工具不知道如何命名,需要你在使用时改名。
ClownFish 不仅仅能生成数据实体类型,还能生成对应的增删改命令及其对应的命令参数:
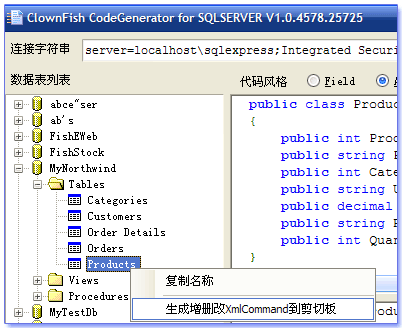
这里涉及到另一个名词:XmlCommand。它是什么,我后面再说。
这个截图是想告诉你:以后不必再为增删改命令以及那些命令参数烦恼了。
执行图片中那个菜单操作,然后再到ClownFish的另一个辅助工具(XmlCommandTool)去粘贴就可以了。
回到顶部
通用,可以非常简单地实现对多种数据库的支持
ClownFish已经从前辈版本中继承了对多数据库种类的支持。
本文的结尾处,我提供了可供下载的完整示例,其中就包含有:SQLSERVER, MySql, ACCESS的示例代码。以下是其中一个示例的截图:

ClownFish 支持多种数据库的原因在于:
ClownFish 在内部使用了DbConnection, DbCommand, DbTransaction这些抽象类型。
ClownFish 提供的API是不区分数据库种类的,您在注册连接时,指定什么类型,就是什么类型。
因此,如果您使用存储过程,或者XmlCommand的话,完全可以做到:一份C#代码同时支持多种数据库的。
回到顶部
灵活,SQL语句放在哪里随便你
对于数据库的访问方式目前有以下5种方案:
1. 有些人喜欢使用存储过程。
2. 有些人不喜欢存储过程也不喜欢把SQL语句放在C#代码中。
3. 有些人会在C#中嵌入参数化的SQL语句。
4. 有些人就是喜欢在C#代码中拼接SQL语句。
5. 还有些人不写SQL语句而在使用ORM工具。
当然了,还有些人同时混合使用多种方案。
我不知道您属于哪一类,如果是最后一类,那么我只能说:ClownFish不适合你。
除此之外,ClownFish完全可以满足您的需要。
对于前4类方式,ClownFish在内部定义一个枚举来表示:
/// <summary>/// 表示要执行什么类型的命令/// </summary>public enum CommandKind{ /// <summary> /// 表示要执行一个存储过程或者是一个XmlCommand /// </summary> SpOrXml, /// <summary> /// 表示要执行一个存储过程 /// </summary> StoreProcedure, /// <summary> /// 表示要执行一个XmlCommand /// </summary> XmlCommand, /// <summary> /// 表示要执行一条没有参数的SQL语句 /// </summary> SqlTextNoParams, /// <summary> /// 表示要执行一条包含参数的SQL语句 /// </summary> SqlTextWithParams}ClownFish提供了一个工具类:DbHelper,可以让您方便地访问数据库,它的许多数据库访问方法可以指定一个CommandKind枚举表示要执行的命令类型:
public static class DbHelper{ public static int ExecuteNonQuery( string nameOrSql, object inputParams); public static int ExecuteNonQuery( string nameOrSql, object inputParams, CommandKind cmdKind); public static int ExecuteNonQuery( string nameOrSql, object inputParams, DbContext dbContext); public static int ExecuteNonQuery( string nameOrSql, object inputParams, DbContext dbContext, CommandKind cmdKind); // 其它的数据库访问方法就不一一列出了,可以查阅API文档。}DbHelper的所有数据库访问方法都提供与以上类似的4个重载方法。
那些方法中,第一个参数可以传入一个SQL语句,或者一个存储过程的名字,或者一个XmlCommand的名称。
参数 cmdKind 的意义就是解释第一个参数的含义。
回到顶部
XmlCommand是什么?
前面已经多次提到了XmlCommand,这里来解释一下XmlCommand是什么。
上一小节中的那些数据访问方法中,有一类较为特殊:不使用存储过程,也不把SQL语句混在C#代码中。
对于这种方案,就需要把SQL语句放在配置文件中。
或许有些人知道:我是喜欢用存储过程的。我之所以喜欢存储过程,是因为存储过程的代码与项目代码是独立的,我可以单独修改存储过程。而且,我还喜欢参数化的查询,反对使用拼接SQL语句。我认为我是将数据库做为我的SQL语句保存容器在使用,存储过程只是这一种方式而已(因为它有参数管理功能)。
除了存储过程之外,使用配置文件也能完成同样功能:1. SQL语句的保存容器,2. 提供参数管理功能。
虽然ClownFish的前辈版本也可以支持这种方案,但是却没有定义一种配置文件的存放格式,因此,需要自己设计配置文件格式,以及提供自己的简化包装方法。对于这种方案来说,本身是没有任何技术难度的,只是需要定义一种配置文件的存放格式。现在,ClownFish已经正式提供这种支持,并提供了一个管理工具。
我把保存在配置文件中的SQL语句称为 XmlCommand ,一个XML文件中可以保存多个XmlCommand,每个XmlCommand都有一个名称以便在运行时区分。下面是一个XmlCommand的代码片段:
<XmlCommand Name="UpdateProduct"> <Parameters> <Parameter Name="@ProductName" Type="String" Size="50" /> <Parameter Name="@CategoryID" Type="Int32" /> <Parameter Name="@Unit" Type="String" Size="10" /> <Parameter Name="@UnitPrice" Type="Currency" /> <Parameter Name="@Quantity" Type="Int32" /> <Parameter Name="@Remark" Type="String" Size="-1" /> <Parameter Name="@ProductID" Type="Int32" /> </Parameters> <CommandText><![CDATA[update Products set ProductName = @ProductName, CategoryID = @CategoryID, Unit = @Unit, UnitPrice = @UnitPrice, Quantity = @Quantity, Remark = @Remark where ProductID = @ProductID;]]></CommandText> </XmlCommand>
看到这段代码,您会不会想:维护它们是不是很麻烦?
其实不是的,ClownFish提供了一个工具,可以轻松地管理它们:

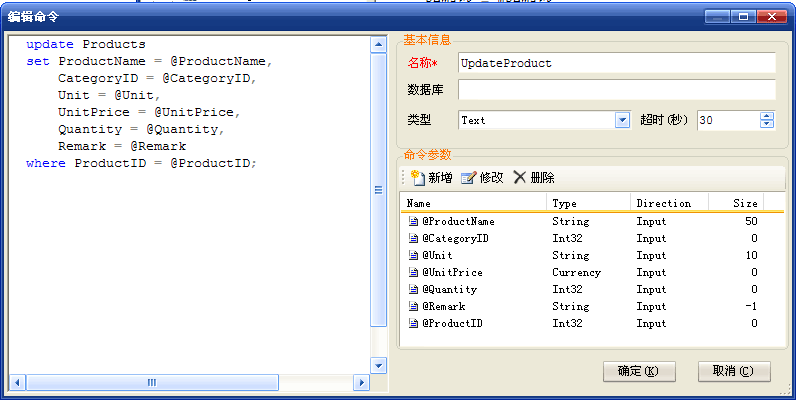
在这个对话框中,每个XmlCommand的属性都提供了控件编辑功能,完全不需要手工维护那段XML文本。
双击某个XmlCommand节点,还可以查看调用代码:

工具生成的调用代码会告诉你那个XmlCommnad有多少个参数,您根本不用记住它们。
还有一点:
XmlCommand的XML文件可以是多个,可以按照不同的业务逻辑来组织它们,例如:

对于一个ASP.NET项目来说,ClownFish 还会监视这个已加载的目录,如果目录中的配置文件有修改,会自动重新加载。
回到顶部
可监控,图形的工具会告诉你每个数据访问的细节
由于ClownFish是个数据访问层,因此,它知道每次执行数据库操作的所有信息。所以,我提供了一个监控工具,用于查看解详细的数据库访问情况。

上图反映了在执行MySql,Access的访问情况。
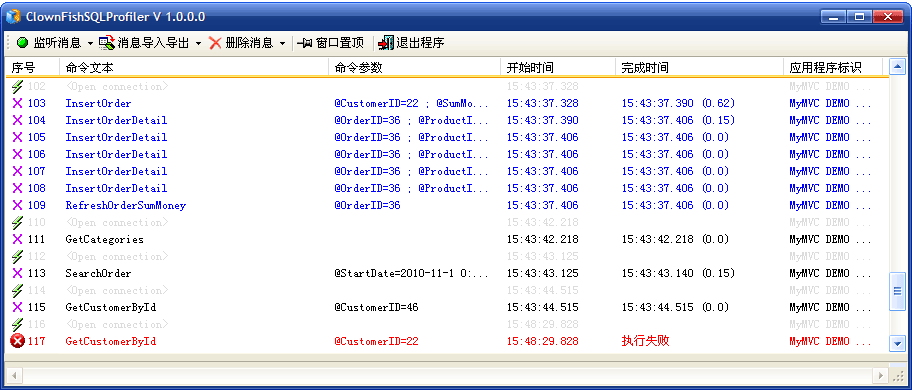
上图反映了事务的执行情况,以及某个语句执行失败的情况。
根据工具窗口,我们可以直观的查看到每个连接中执行了多少次命令,它们是否属于同一个事务,它们的类型是存储过程,XmlCommand,SQL语句,全都一目了然。而且,还可以知道每个命令的执行参数是什么:

或许有些人看了这个工具后,会认为它是多余的,他总认为有个【SQL Server Profiler】,其它的东西都是没有意义的。
我不知道他有没有想过:用SQL Server Profiler去监视一个局域网的SQL Server实例,你还能分辨哪些操作是由你引发的吗??
我的工具则不同,它是配合我的数据访问层一起工作的,由我的数据访问层告诉工具当前用户触发了什么数据库的操作。
因此在分析本机程序访问数据库时,可以很直观的知道:
您的某个操作引发了什么样的数据库调用,以及调用的各种细节参数。
更何况我的工具不止针对SQL Server有效,理论上,.net支持的,我的数据访问层应该都支持。
前面也说了,它是配合我的数据访问层一起工作的,
所以,只要是使用ClownFish,哪怕是访问Access数据库,也能有这样的监控效果。(前面有图片证明)
回到顶部
关于示例代码
为了能让更多的人选择ClownFish,这次我为大家准备了大量的示例代码。

1. ClownFishDEMO是一个综合示例,网站型项目。运行效果图:
2. MultiAccountDEMO是一个多帐套的演示网站。演示了一套代码处理多帐套的功能。
3. PerformanceTestApp是前面介绍的性能测试项目,你也可以将其它的数据访问层加入其中,一起做性能测试。
不仅仅是以上三个项目演示了如何使用ClownFish,我还为以前的 MyMVC框架 的示例程序增加了数据库访问功能(以前只支持XML文件)。
现在,MyMVC框架 的演示程序也能通过ClownFish来访问SQLSERVER。
可以修改 MyMVC框架 演示网站中的web.config来切换数据访问方法:
<appSettings> <!--DataSoureceKind 表示不同的数据访问方式,目前支持三个可选的配置值(注意大小写): 1. XmlFile ,表示使用XML文件中的数据,此选项为默认值。 2. XmlCommand ,表示使用配置文件中的SQL命令去访问SQLSERVER 3. StoreProcedure ,表示调用SQLSERVER中的存储过程去访问数据库 你可以修改下面的配置,并结合ClownFishSQLProfiler.exe工具去观察它们的差别。 --> <add key="DataSoureceKind" value="XmlFile" /></appSettings>
考虑到有些人在配置SQLSERVER时,会遇到一些问题,MyMVC框架的演示程序仍然默认使用XML文件,而不是SQLSERVER数据库。
但是,由于ClownFish是一个数据访问层,它的示例只能访问数据库了。
如果不知道如何配置示例,请参考我的博客:如何在IIS6,7中部署ASP.NET网站
还有一件让我忧虑的事情:示例中还演示了 MySql的访问!
我建议:如果你平时不使用MySql,那么就跳过示例中的MySql演示部分吧。
最后建议:在下载示例代码后,首先打开 Readme.txt 文件看一下,谢谢!
如果需要了解ClownFish的使用方法,请点击ClownFish 使用说明
点击此处下载示例代码(ClownFishDEMO)
点击此处下载示例代码(MyMVC)
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】按钮。
如果,您希望更容易地发现我的新博客,不妨点击一下右下角的【关注 Fish Li】。
因为,我的写作热情也离不开您的肯定支持。
感谢您的阅读,如果您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是Fish Li 。






