

五折交叉验证: 把数据平均分成5等份,每次实验拿一份做测试,其余用做训练。实验5次求平均值。如上图,第一次实验拿第一份做测试集,其余作为训练集。第二次实验拿第二份做测试集,其余做训练集。依此类推~
但是,道理都挺简单的,但是代码我就不会写,比如我怎么把数据平均分成5份?我怎么保证每次实验的时候,数据都是这么划分的?本来一般的训练时,把数据按6:2:2分成训练集、验证集和测试集,在训练集上训练图像,验证集上保存最佳模型,测试集用来最后的测试。现在交叉验证没有验证集了,怎么保存模型?以下为大家一一解答。
1.把数据平均分成K等份
使用KFold类。class sklearn.model_selection.KFold(n_splits=5, *, shuffle=False, random_state=None) sklearn提供的这个函数就是用来做K折交叉验证的。 提供训练集/测试集索引以分割数据。将数据集拆分为k折(默认情况下不打乱数据。
参数介绍
- n_splits:int, 默认为
5。表示拆分成5折 - shuffle:bool, 默认为
False。切分数据集之前是否对数据进行洗牌。True洗牌,False不洗牌。 - random_state:int, 默认为
None。当shuffle为 True 时,如果random_state为None,则每次运行代码,获得的数据切分都不一样,random_state指定的时候,则每次运行代码,都能获得同样的切分数据,保证实验可重复。random_state可按自己喜好设定成整数,如random_state=42较为常用。当设定好后,就不能再更改。
使用KFold类需要先初始化,然后再调用它的方法实现数据划分。它的两个方法为:
get_n_splits(X=None, y=None, groups=None)
返回交叉验证器中的拆分迭代次数
split(X, y=None, groups=None)
生成索引,将数据拆分为训练集和测试集。X: 数组,形状为:(n_samples, n_features)
其中n_samples是样本数,n_features是特征数。y: 数组,形状为(n_samples,), default=None。可要可不要return:train和test的索引,注意返回的是每个集合的索引,而不是数据
举例1:设置shuffle=False,每次运行结果都相同
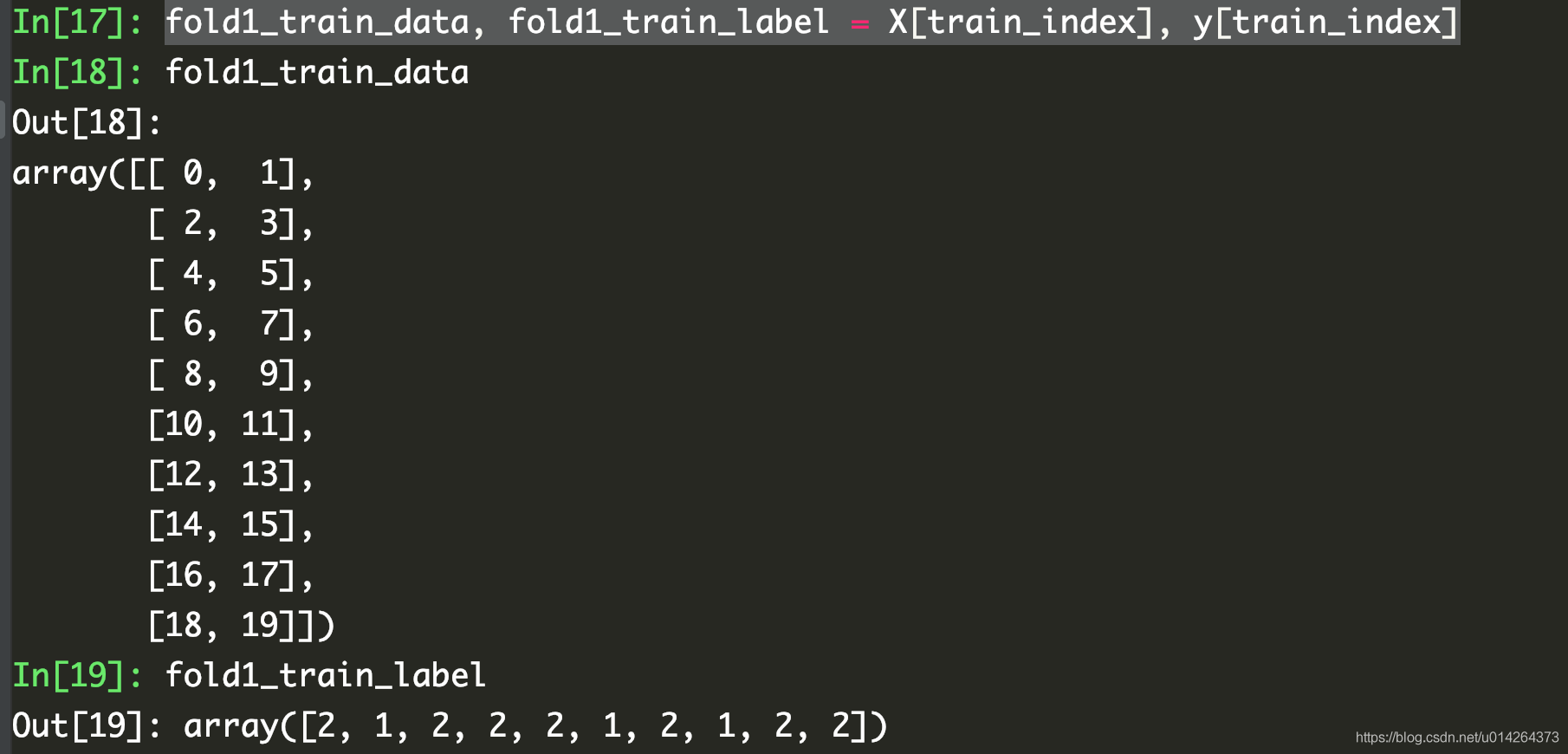
from sklearn.model_selection import KFold
import numpy as np
X = np.arange(24).reshape(12,2)
y = np.random.choice([1,2],12,p=[0.4,0.6])
kf = KFold(n_splits=5,shuffle=False) # 初始化KFold
for train_index , test_index in kf.split(X): # 调用split方法切分数据
print('train_index:%s , test_index: %s ' %(train_index,test_index))
复制代码
结果:5折数据的索引
train_index:[ 3 4 5 6 7 8 9 10 11] , test_index: [0 1 2]
train_index:[ 0 1 2 6 7 8 9 10 11] , test_index: [3 4 5]
train_index:[ 0 1 2 3 4 5 8 9 10 11] , test_index: [6 7]
train_index:[ 0 1 2 3 4 5 6 7 10 11] , test_index: [8 9]
train_index:[0 1 2 3 4 5 6 7 8 9] , test_index: [10 11]
复制代码
通过索引去获取数据和对应的标签可用:
fold1_train_data, fold1_train_label = X[train_index], y[train_index]
复制代码
举例2:设置shuffle=True,每次运行结果都不相同

举例3:设置shuffle=True和random_state=整数,每次运行结果相同

因此,实际使用的时候建议采用案例3这种方式,即可保证实验可重复,有增加了数据的随机性。
举例4: 真实案例数据划分
我有一些nii.gz的三维数据用来做分割,图像和label分别放在不同的文件夹。如:
└── 根目录
└── image
│ ├── 1.nii.gz
│ │── 2.nii.gz
│ └── 3.nii.gz
│
── label
│ ├── 1.nii.gz
│ │── 2.nii.gz
│ └── 3.nii.gz
复制代码
images1 = sorted(glob.glob(os.path.join(data_root, 'ImagePatch', 'l*.nii.gz')))
labels1 = sorted(glob.glob(os.path.join(data_root, 'Mask01Patch', 'l*.nii.gz')))
images2 = sorted(glob.glob(os.path.join(data_root, 'ImagePatch', 'r*.nii.gz')))
labels2 = sorted(glob.glob(os.path.join(data_root, 'Mask01Patch', 'r*.nii.gz')))
data_dicts1 = [{'image': image_name, 'label': label_name}
for image_name, label_name in zip(images1, labels1)]
data_dicts2 = [{'image': image_name, 'label': label_name}
for image_name, label_name in zip(images2, labels2)]
all_files = data_dicts1 + data_dicts2
# 把image和label创建成字典,统一放在列表里
复制代码

all_files是一个包含所有数据的列表,但列表里的每一个数据又是一个字典,分别当image和label的数据地址。
我们对all_files的数据进行五折交叉验证:
floder = KFold(n_splits=5, random_state=42, shuffle=True)
train_files = [] # 存放5折的训练集划分
test_files = [] # # 存放5折的测试集集划分
for k, (Trindex, Tsindex) in enumerate(floder.split(all_files)):
train_files.append(np.array(all_files)[Trindex].tolist())
test_files.append(np.array(all_files)[Tsindex].tolist())
# 把划分写入csv,检验每次是否相同
df = pd.DataFrame(data=train_files, index=['0', '1', '2', '3', '4'])
df.to_csv('./data/Kfold/train_patch.csv')
df1 = pd.DataFrame(data=test_files, index=['0', '1', '2', '3', '4'])
df1.to_csv('./data/Kfold/test_patch.csv')
复制代码
我们把数据集的划分保存到csv里面,以防止代码改动丢失了原本的划分方法。
数据集划分好了,就可以进行训练和测试了。每一次拿划分好的一折数据就行。
# 五折分开train, 每次拿一折train 和 test
train(train_files[0], test_files[0])
test(test_files[0])
复制代码
在train和test方法里面,肯定要写好对应的dataloder, 因为我们刚只是把数据的名字进行了划分,并没有加载数据集。
通常的做法里,会循环5次,运行一次代码,把五折的结果都做出来。但是我们这种写法的好处在于,你想训练第几折,就把索引值改一下就是,不需要一下子全部训练完。只要你不动代码,你一年后再训练,数据集的划分都不会变。变了也不怕,我们把划分已经保存成csv了。
当然,这只是一种写法,如果有更好的方案,欢迎留言探讨~~
2.没有验证集了,怎么保存最佳模型
这是我之前一直好奇的问题。因为,如果不做交叉验证,那么我会根据测试集上的指标保存最佳模型。比如以下代码是在验证集上完成的。
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
save_dir = 'checkpoints/checkpoint_04264/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_path = save_dir + str(epoch + 1) + "best_metric_model.pth"
torch.save(model.state_dict(), save_path)
print('saved new best metric model')
复制代码
但是,现在,没有验证集了,我是根据训练集上的指标保存模型呢,还是根据测试集上的指标?这个问题,没有统一答案,两者做法都有。正因为没有统一答案,那我们可以选择对自己最有利的答案啊😜。比如,写论文的时候,根据测试集上的结果保存模型,那肯定得到的结果更好啊。
而且,还有一个小tips, 用交叉验证的得到的结果通常比按6:2:2划分训练集验证集测试集上的结果要好。想想是为什么😉
作者:zh智慧
链接:https://juejin.cn/post/6956209296564584462
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




