
前言
上篇文章吧啦吧啦讲了一些有的没的,现在还是回到主题写点技术相关的。本篇文章作为基础爬虫知识的最后一篇,将以爬虫程序的模块设计来完结。
在我漫(liang)长(nian)的爬虫开发生涯中,我通常将爬虫程序分为四大模块。

如图,除了代理模块是根据所需引入程序,请求、解析、储存模块是必不可少的。
代理模块
代理模块主要是构建代理IP池。在第三篇中讲过为什么需要代理IP,因为很多网站是通过请求频率来识别爬虫,即记录一个IP在一段时间内的请求次数,所以可以通过更换代理IP来提高爬取效率。
概念
什么是代理IP池?
和线程池、连接池的理念一样,预先将多个代理IP放入一个公共区域供多个爬虫使用,每次用完之后再放回。
为什么需要代理池?
正常情况下,我们在程序中是这样添加代理IP的。
proxies = {
'https': 'https://183.220.xxx.xx:80'
}
response = requests.get(url, proxies=proxies)
这样我们就只能使用一个IP,这时候可能有人就会说:

就算使用集合可以存放多个代理IP,但是如果IP失效需要删除,或者添加新的IP时,还是一样需要终止程序修改代码。我在初学编程的时候,老师就经常说这么一句话:

直到现在,这句话也时常在耳边萦绕。而代理模块就是提供了灵活增删代理IP、验证IP有效性的功能。
实现
目前,一般使用MySQL来存放代理IP。先看一下代理池的表设计。
CREATE TABLE `proxy` (
`ip` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
我的表结构设计比较简单粗暴,只有一个字段。在开发中可以根据自己的需要来进行细分。
再看一下表里面的数据: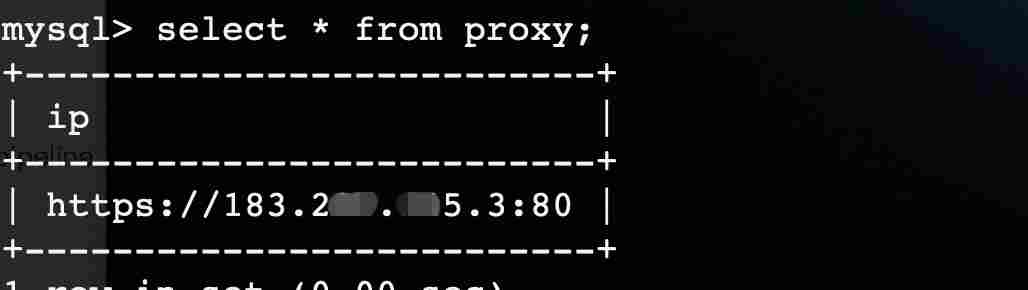
从图中看着,代理IP是由支持的协议 + IP + port组成。
最后,代理池代码奉上:
import requests
import pymysql
class proxyPool:
# 初始化数据连接
def __init__(self, host, db, user, password, port):
self.conn = pymysql.connect(host=host,
database=db,
user=user,
password=password,
port=port,
charset='utf8')
# 从数据库获取ip
def get_ip(self):
cursor = self.conn.cursor()
cursor.execute('select ip from proxy order by rand() limit 1')
ip = cursor.fetchone()
# 如果代理ip表中有数据,则进行判断,没有则返回空
if ip:
judge = self.judge_ip(ip[0])
# 如果ip可用直接将其放回,不可用再重新调用此方法从数据库获取一个IP
if judge:
return ip[0]
else:
self.get_ip()
else:
return ''
# 判断ip是否可用
def judge_ip(self, ip):
http_url = 'https://www.baidu.com'
try:
proxy_dict = {
"http": ip,
}
response = requests.get(http_url, proxies=proxy_dict)
except Exception:
self.delete_ip(ip)
return False
else:
code = response.status_code
if code in (200, 299):
return True
else:
self.delete_ip(ip)
return False
# 从数据库中删除无效的ip
def delete_ip(self, ip):
delete_sql = f"delete from proxy where ip='{ip}'"
cursor = self.conn.cursor()
cursor.execute(delete_sql)
self.conn.commit()
代理池工作流程主要分为两部分:
- 从数据中获取IP。如果数据库没有可用IP,则表示不使用代理,返回空;如果有IP,则进入下一步
- 对IP进行有效性验证。如果IP无效,删除IP并重复第一步;如果IP有效,则返回IP
使用
代理池最终的目的还是提供有效代理IP。玩的比较花的可以将代理池与爬虫程序分离,将代理池独立成一个web接口,通过url来获取代理IP,需要使用Flask或者Django来搭建一个web服务。
我一般就是直接放在爬虫程序中。样例代码如下:
pool = proxyPool('47.102.xxx.xxx', 'test', 'root', 'root', 3306)
proxy_ip = pool.get_ip()
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
proxies = {
'http': proxy_ip
}
if proxy_ip:
response = requests.get(url, proxies=proxies)
else:
response = requests.get(url)
print(response.text)
代理IP的来源
这个之前也讲过,代理IP可以付费购买或者从网上使用免费的。因为免费IP存活率低,所以代理池主要是面向于免费IP。
一般都是单独开发一个爬虫程序来爬取免费的IP,并放入到数据库中,然后验证可用性。
请求/解析模块
在前几篇写的爬虫样例中,都是对单个url进行的爬取。而爬虫程序往往都是以网站为单位进行的爬取。归根结底,都是基于请求模块和解析模块来设计实现的。
如果想爬取整个网站,首先必须确定一个网站入口,即爬虫程序第一个访问的url。然后接着对返回的网页进行解析,获取数据或者获取下一层url继续请求。
这里就拿腾讯视频举个栗子,我们来**爬取动漫的信息*。
1. 选择网站入口
分析需求,选取网站入口。此时,需要明确的是:动漫频道url就是网站入口。
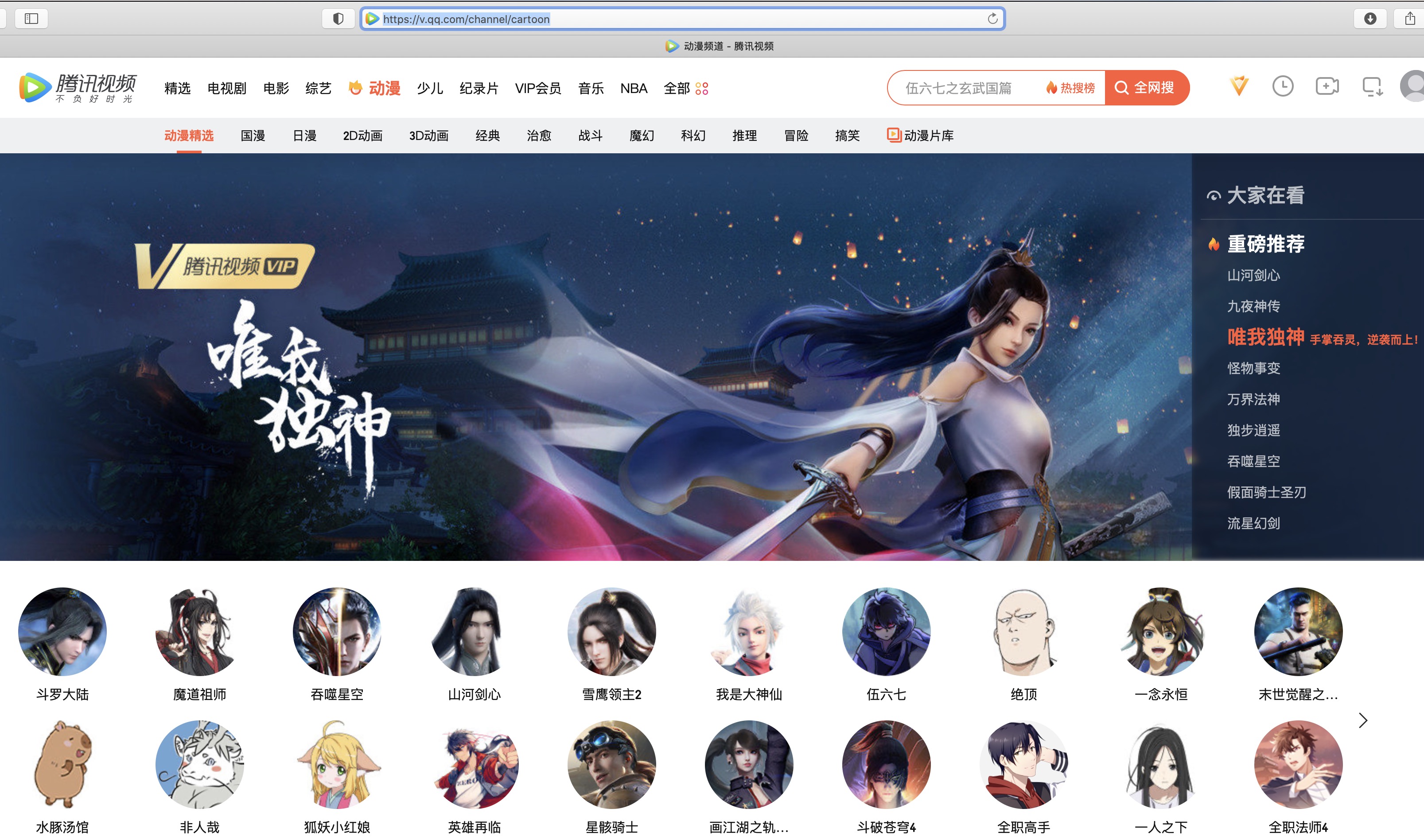
我们对网站入口,即动漫频道进行请求后,解析返回的网页内容。我们从页面中可以发现,动漫频道下有国漫、日漫、战斗等分类。
查看网页源码:
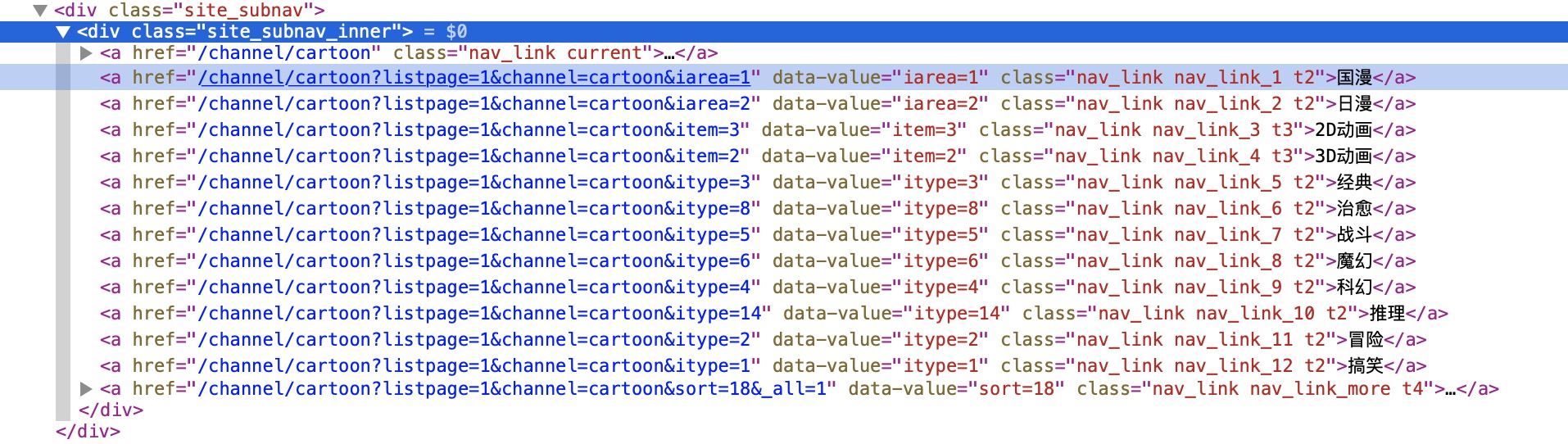
如上图,我们可以从动漫首页解析出来各个_分类的url_。
2.分类请求
在获取到各个分类的url之后,继续发起请求。这里首先对国漫的url进行请求,返回的网页内容如下:
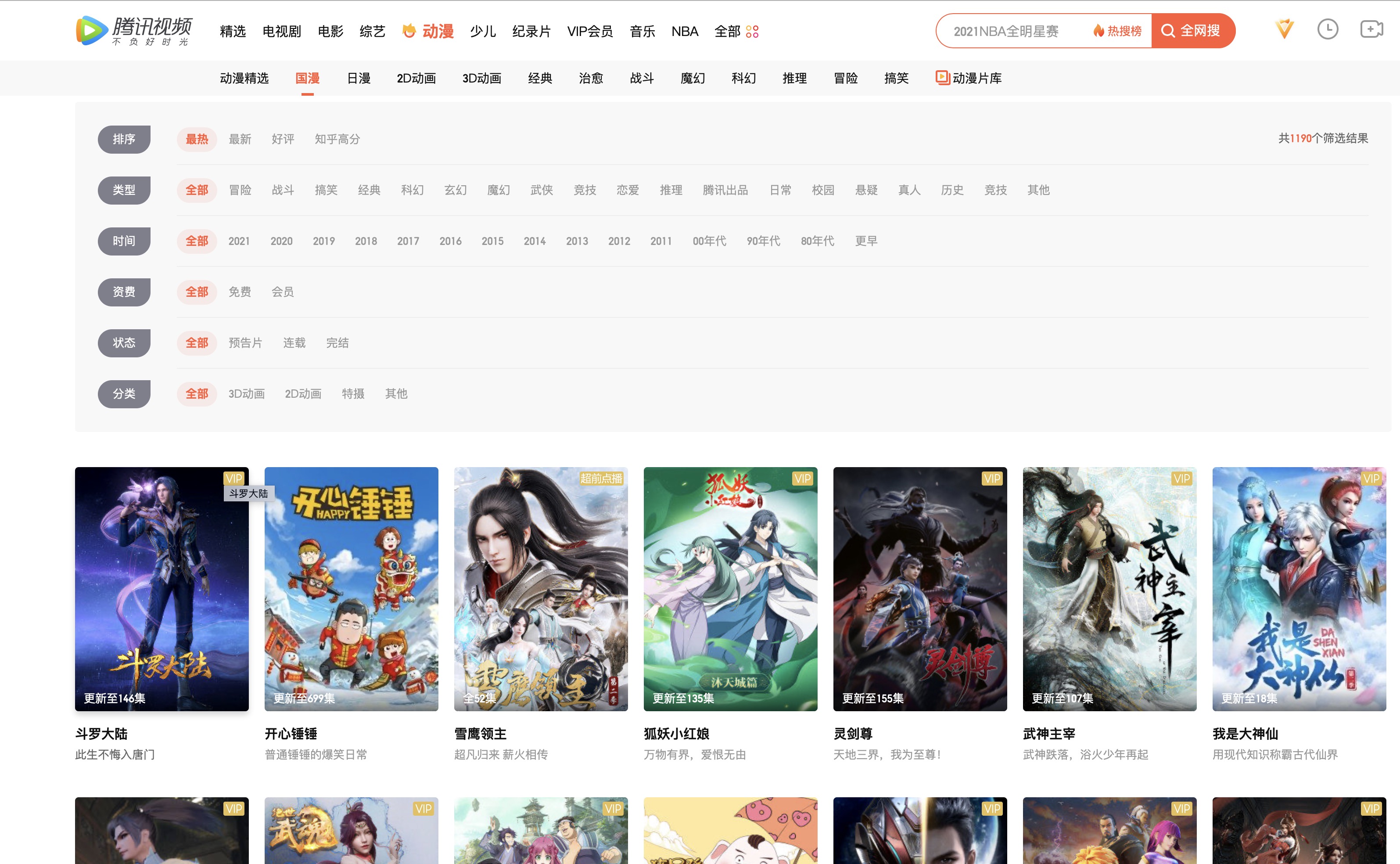
如图,都是国漫分类下的动漫列表。在浏览器中,我们点击哪个动漫就能进入它的播放页,所以在这个页面上我们可以解析到这些国漫的_播放页链接_。
我们查看此页面的网页源码:
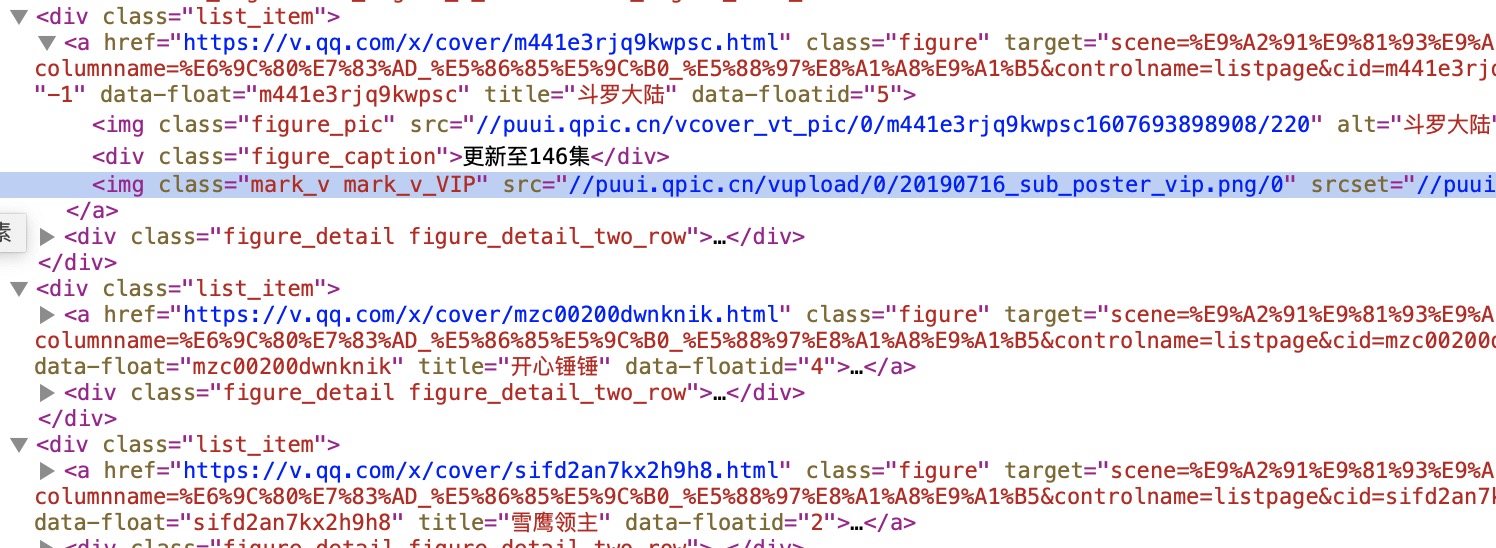
如图,我们可以获取到各个_国漫播放页的url_。
3.定向到信息页
以第一个国漫斗罗大陆为例,我们获取到它的播放页url,进行请求并返回播放页内容。
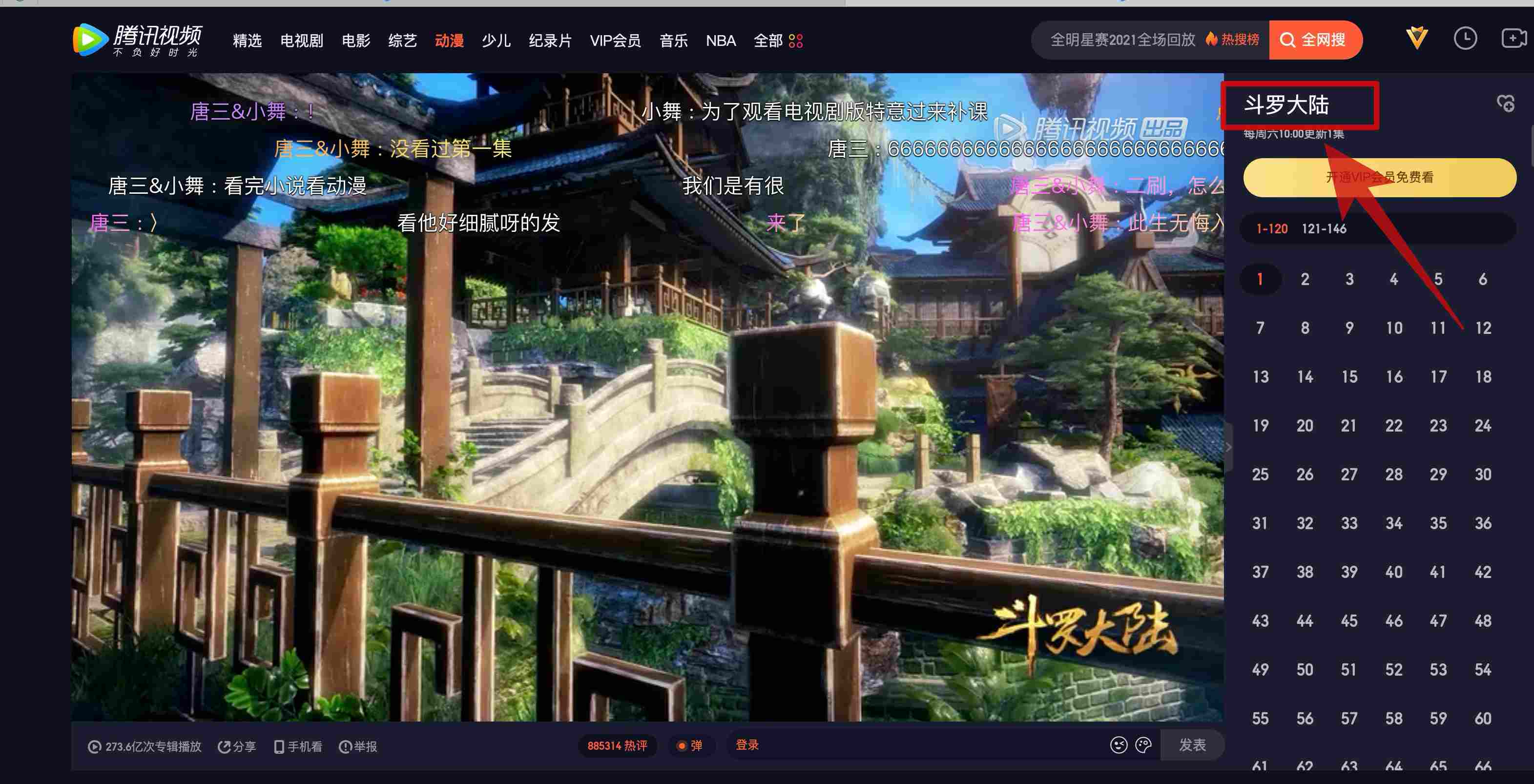
我们发现,点击右上角的斗罗大陆就会进入详情页。所以我们需要解析右上角_详情页的url_进行请求,来获取详情页的网页内容。

4.获取数据
对详情页的网页内容进行解析,得出自己想要的数据,具体代码在第一篇文章的样例中。
从上面的四个步骤来看,爬虫对网站的爬取就是层层递进,逐级访问。我们要找准网站入口,明确想要获取的数据内容,规划好网站入口到获取数据的路径。
当然其中还是有很多可以优化的地方,例如从第二步可以略过第三步,直接请求第四步的详情页。我们比对一下播放页和详情页的url。
# 斗罗大陆的播放页和详情页
https://v.qq.com/x/cover/m441e3rjq9kwpsc.html
https://v.qq.com/detail/m/m441e3rjq9kwpsc.html
# 狐妖小红娘的播放页和详情页
https://v.qq.com/x/cover/0sdnyl7h86atoyt.html
https://v.qq.com/detail/0/0sdnyl7h86atoyt.html
从上面两对url中我们不难看出其中的规律。所以我们在第二步解析出国漫播放页的url之后,经过处理,就可以直接得到详情页的url。
备注:上面对腾讯视频的爬取分析仅做流程参考,实际开发可能涉及异步请求等方面的知识。
存储模块
爬取的数据只有存储下来,爬虫才变得更有意义。
通常爬取数据格式有文本、图片等,这里先看图片如何下载并保存到本地目录。
图片下载
之前我用scrapy内置的ImagesPipeline下载GIF动图的时候,折腾了老半天,下载下来的还不是动图。于是回归原始,终成功,一行代码慰平生。
代码如下:
urllib.request.urlretrieve(imageUrl, filename)
所以,不论以后你用原生爬虫还是scrapy的时候,下载图片就记住一行代码就行了!
找个图片链接测试一下:
右键图片,选择拷贝图像地址。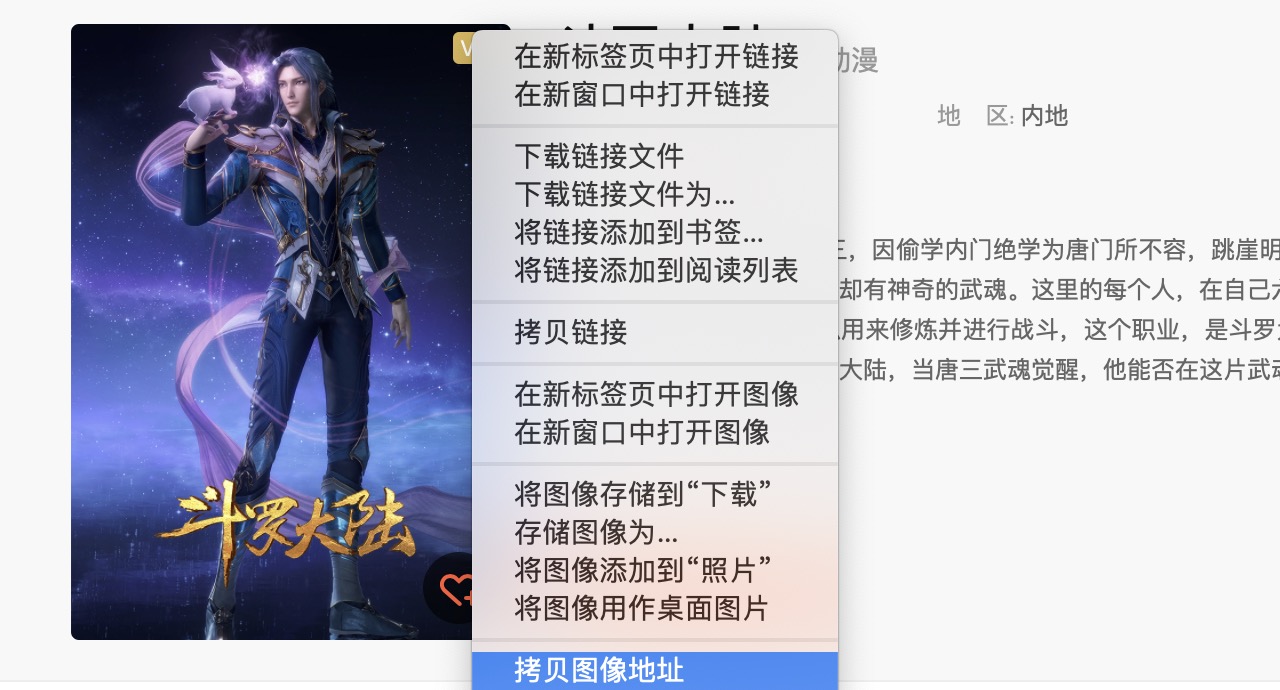
将图片地址放入程序中,代码如下:
import urllib.request
urllib.request.urlretrieve('http://puui.qpic.cn/vcover_vt_pic/0/m441e3rjq9kwpsc1607693898908/0', './1.jpg')
我将图片下来,保存到当前目录并命名为1.jpg,运行程序。
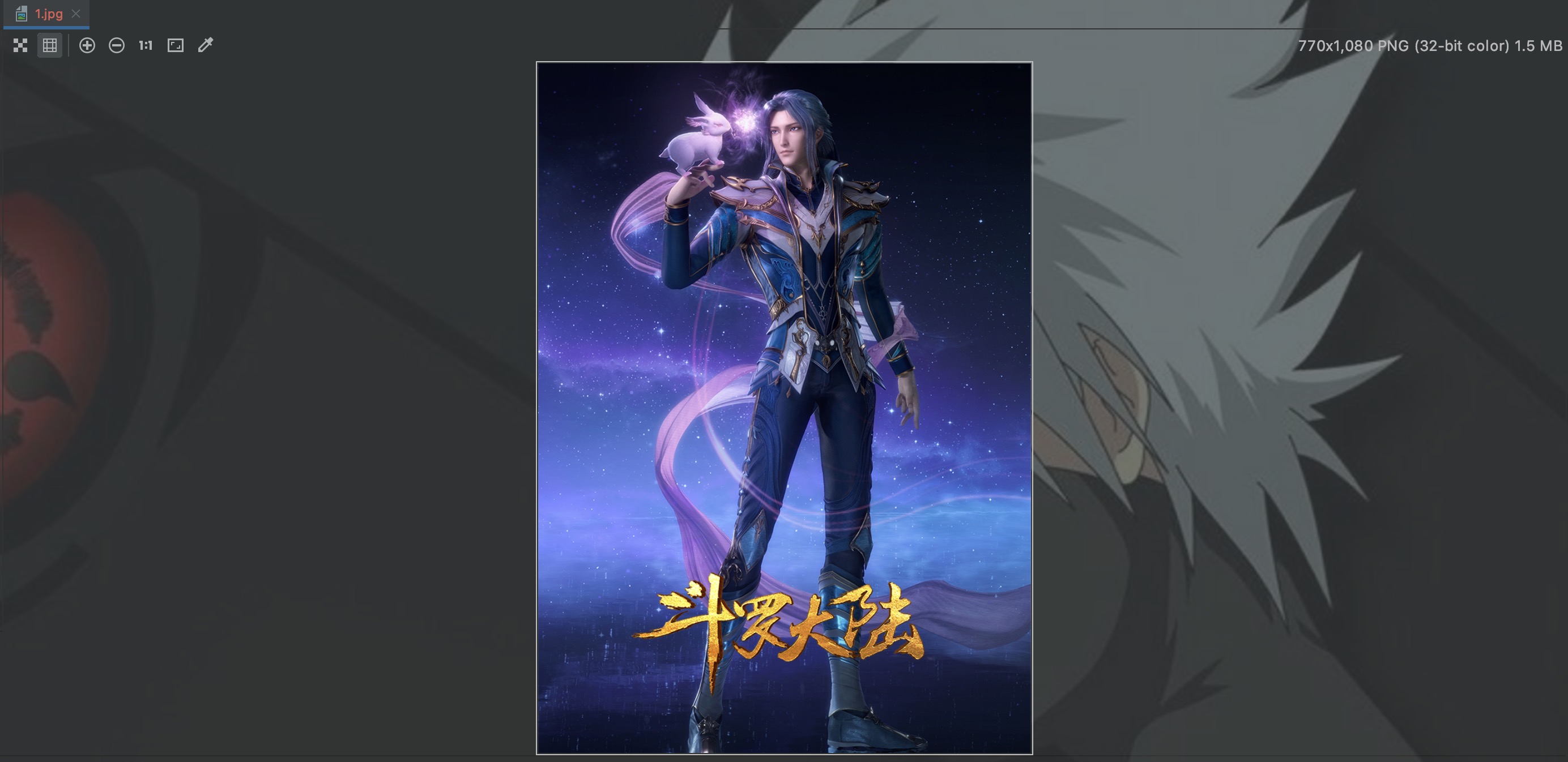
文本数据
- 存放于文件中
with open("/path/file.txt", 'a', encoding='utf-8') as f:
f.write(data + '\n')
-
使用pymsql模块将数据存放到MySQL的数据表中

-
使用pandas或者xlwt模块将数据存放到excel中
结语
本篇文章主要写了一下自己对爬虫程序模块设计的理解,也是对爬虫基础知识的一个总结和收尾。期待下一次相遇。
写的都是日常工作中的亲身实践,置身自己的角度从0写到1,保证能够真正让大家看懂。
作者: Seven0007
出处:https://www.cnblogs.com/seven0007/p/scrapy05.html



