
数据仓库简介
信息已经成为任何组织的主要资产。
企业各级用户,包括运营管理者、中层管理者和高层管理,都希望获得能够做出合理决策并为业务增值的信息。每个层级者对所希望获取的信息有着不同的要求,但共同的要求包括信息的准确、完整和一致等。
一个理性的经营者将使用可用且可信的信息作为可能影响业务基线的智能决策的根基。
当我们使用数据或信息这两个术语时,我们通常可以互换使用它们。然而,数据、信息、知识和智慧都有象征和离散的意义。但它们在信息层次结构中也是相互关联的(图1.1)。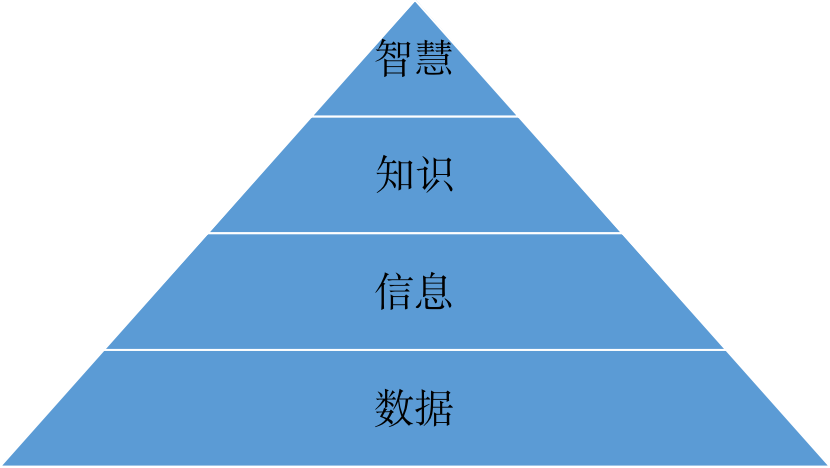
数据,在层次结构的底部,是具体的,客观的事实或观察。例如,“DL404航班上午8点30分到达”或“洛杉矶国际机场在美国加州”。这些事实如果单独存在,就没有内在意义,但可以很容易地捕捉、传输和存储电子信息。
信息,是基础数据的浓缩形式。业务人员通过将数据组织为分析单元(例如,客户、产品、日期),将数据转换为信息,并赋予其相关性和目的。对于这种相关性和目的来说,在信息被接收和使用的环境中考虑信息是很重要的。一个职能部门的管理者与其他部门的管理者有不同的信息需求,他们从自己的角度来看待信息。同样,这些信息需求在组织层次结构中也各不相同。根据经验,信息用户在组织层次结构中的位置越高,需要的汇总(或浓缩)信息就越多。
知识,朝向信息层次的顶端,是经过合成和语境化以提供价值的信息。管理者利用信息,加上自己的经验、判断和智慧来创造知识,知识比信息更丰富更深,因此更有价值。它是用值、规则来表示的底层信息和来自其他上下文的附加信息的混合。
智慧,是金字塔的最高层次。它将知识作为底层放置到一个框架中,允许它被应用到未知的,不一定是直觉的情况。因为知识和智慧很难构建,而且往往是隐性的,所以很难在机器上捕获它们,也很难转移。
因此,数据仓库的目标并不是创造知识或智慧。相反,数据仓库(或商业智能)的重点是通过将数据转移到适当的上下文中,将数据聚合、整合和汇总为信息。
由于信息的价值是在组织内提供给用户的,因此,信息资产必须在用户请求时随时可用,并具有预期的质量。
在过去,是直接对业务系统进行分析的,如电商网店或客户关系管理(CRM)系统。然而,由于当今的组织中有大量的数据,从这些原始数据中提取有用和重要的信息,成为了分析型商业用户的一个问题。另一个问题是,在传统组织中通常存在被称为“数据孤岛”的孤立数据源。这些“数据孤岛”和其他数据源之间唯一的联系是数据的业务主键,用于识别两个系统中的同一业务对象。因此,必须在某个点上对这些业务主键进行异构数据源的集成,但通常超出了普通业务分析人员的能力。
操作业务的用户在日常工作中经常查询或更新特定业务对象的数据。这些操作是使用事务性查询执行的。
例子包括问题的支持票、机票的预订或电子邮件的传输。在这些情况下,业务用户处理作为其业务流程一部分的业务对象。中层或高层管理人员通常有其他任务要完成。他们希望从他们负责的业务或业务单元获得信息。他们利用这些信息来做出管理决策。出于这个目的,他们经常对数据库发出分析查询来汇总数据。通过这样做,他们将原始数据(如销售事务)转换为更有用的信息(如每月和客户的销售报告)。此类分析查询与事务性查询不同,因为首要的查询通常聚合或汇总大量原始数据。如果业务用户对业务数据库发出分析查询,关系数据库管理系统(RDBMS)必须从磁盘存储中检索所有底层记录,以便执行聚合。
数据仓库的历史
在数据仓库出现之前,用户必须直接从存储在业务系统中的行数据里查询所需的信息,如简介中所述那样。
这样的原始数据通常存储在为用户应用程序服务的关系数据库中。虽然查询一个作业型数据库的优点是业务用户能够从这些系统接收实时信息,但使用分析查询将原始数据转换为有用的信息会降低作业数据库的速度。这是由于聚合需要即时读取大量记录来提供业务的统计信息(例如,每月的销售额,每年的收入等)。业务用户和分析用户同时使用同一个数据库通常会使数据库过载,并影响双方数据的可用性。
决策支持系统
为了能够迅速获得决策过程所需的信息,企业组织引进了决策支持系统,这些系统结合了各种可扩展和可交互的信息技术和工具,通过处理和分析数据来支撑管理人员进行决策。
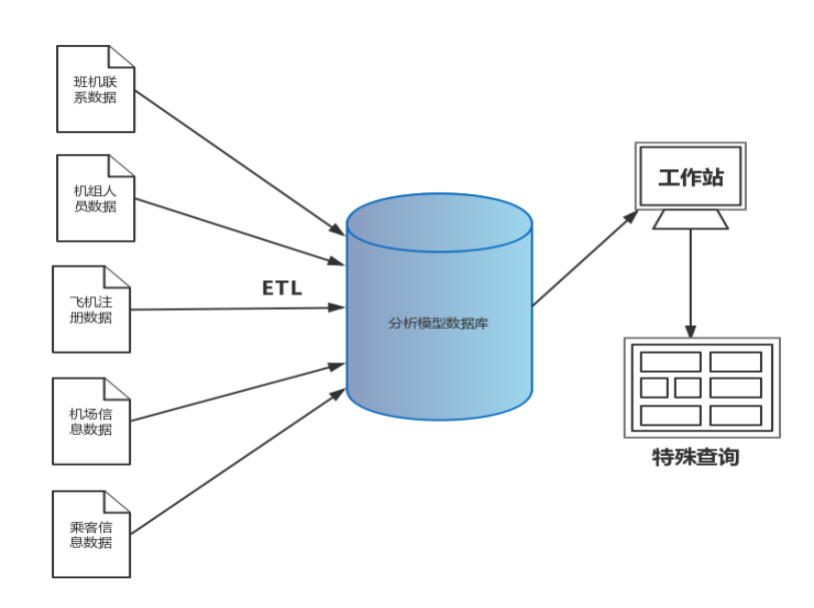
为了实现其目标,决策支持系统由一个分析模型数据库组成,该数据库提供了从源系统提取的选定数据。源系统是在组织中可用的业务系统,但可以包括任何其他企业数据源。示例可能包括汇率、天气信息或管理人员在形成决策时所需的任何其他信息。原始数据在分析模型数据库中聚合,或者在进入系统的过程中聚合。使用的是从数据源提取、转换和加载数据到目标的ETL(提取、转换、加载)工具来完成数据的聚合工作。
图1.2中的分析模型数据库是由一个处理五个数据源数据的ETL工作流加载的。然后,通过ETL工作流(在数据准备过程中)或业务用户查询数据时聚合数据。业务用户可以使用特殊查询和针对数据库的其他复杂分析来查询分析模型数据库。在大部分情况下,这些数据是为了前述的分析目的而形成的,只包含相关的分析信息。因为决策支持系统(DSS)与源系统分离,与决策支持系统(DSS)的交互不会减慢业务系统的速度。
下一节将讨论本书中涉及的数据仓库系统。这些系统在20世纪90年代被引入,此后一直作为决策支持系统的数据后台。
数据仓库系统
数据仓库系统(DWH)是一个数据驱动的决策支持系统,它在战略意义上支持决策制定过程,此外还支持运营决策,例如检测信用卡欺诈的实时分析或对产品和服务的实时建议。数据仓库提供了非易失的、面向主题的数据,这些数据在所有目标级别上对业务用户进行集成并保持一致。学科导向不同于ERP或业务系统的功能导向,侧重于一个主题领域进行分析。保险公司主题领域的示例可能是客户、保单、保险费和索赔。另一方面,主题领域“产品”、“订单”、“供应商”、“材料清单”和“原材料”是制造企业的示例。这个组织视图允许对与同一现实世界事件或对象相关的所有数据进行集成分析。
在业务用户可以使用数据仓库提供的信息之前,数据是从源系统加载到数据仓库的。正如简介中所述,在许多情况下,对组织内部或外部的各种数据源的集成都是在业务主键上实现的。如果业务对象(如客户)在每个系统中具有不同的业务视角,那么这就会成为一个问题。例如,组织中的客户号码是字母和数字组合,但其中一个业务系统只允许业务主键使用数字。当业务系统的数据库包含脏数据(通常是无效或过时的数据,或者没有业务规则)时,还会出现其他问题。脏数据的示例包括输入错误、传输错误或OCR处理过的不可读文本等。在将这些脏数据呈现给传统数据仓库中的业务用户之前,必须对数据进行清洗,这是数据集市加载过程的一部分。其他问题包括跨源系统的数据的不同数据类型或字符编码。然而,这种数据清洗也有例外:例如,当业务用户需要数据质量的报告,就不需要数据清洗了。
在将数据加载到数据仓库时经常执行的另一项任务是对原始数据进行一些聚合,以满足所需的粒度。数据粒度是数据仓库支持的数据单元。数据粒度的不同就像是销售人员和销售区域之间的差异。在某些情况下,业务用户只希望分析区域内的销售情况,而对给定销售人员的销售情况不感兴趣;另一个原因可能是法律问题,例如受限于工会的协议或法律约束力。
在其他情况下,业务分析师实际上想要分析销售人员的销售情况,比如在计算销售佣金时。
在大多数情况下,数据仓库工程师遵循以尽可能细的粒度加载数据的目标,从而允许多个层次进行分析。然而,在某些情况下,业务系统只提供粗粒度的原始数据。
许多数据仓库的一个重要特征是保存历史数据。所有已加载到数据仓库中的数据都将存储起来,供时变分析使用。这允许分析数据随时间的变化,这是业务用户的一个常见需求,例如,分析给定地区过去几个季度的销售发展。因为数据仓库中的数据是历史数据,而且在大多数情况下,源系统中的数据不再可用,所以数据是非易失的。这也是信息系统可审计的重要要求。




