
近日,由 TiDB 社区主办,专属于全球开发者与技术爱好者的顶级挑战赛事——TiDB Hackathon 2020 比赛圆满落幕。今年是 TiDB Hackathon 第四次举办,参赛队伍规模创历届之最,共有 45 支来自全球各地的队伍报名,首次实现全球联动。经过 2 天时间的极限挑战, 大赛涌现出不少令人激动的项目。
本篇文章的作者为 ️ ️队的杨可奥,他们团队在本次 Hackathon 比赛中尝试使用 SPDK 提供的工具让 TiKV 基于用户态存储运行,并获得了显著的性能提升。
现代软件的结构建立在一层一层抽象之上,在大部分时候,这样的“抽象”意味着对调度细节的隐藏和对性能的损耗。应用不制定查询计划,而将制定查询计划的任务交给数据库;数据库不直接写入磁盘,而由操作系统来决定写入的时机和量;操作系统也不会直接在磁片 / 颗粒上操作,而是批量发送指令再由磁盘的控制器来决定执行的方案。在大部分时候,这些调度交由知识更加丰富的一方来进行决策,所以表现地也还不错;而隐含于其中的性能损耗(比如使用系统调用时的额外开销)对性能不敏感的应用来说也无关紧要。
可惜的是,数据库恰巧是个反例 ——在这篇文章中,将会讲述现代储存结构中一系列抽象的弊端,以及本次 Hackathon 期间 ️ ️队通过在 TiKV 中引入 SPDK 工具来克服这些问题的努力。
问题背景
对于数据库而言,直接可用的存储抽象是从文件系统开始的,通过创建文件、对文件进行写入和读取来间接地读写硬盘。从应用发起相关的系统调用开始,直到数据落在磁盘、颗粒上,大致需要以下几个步骤:
- 操作系统收到系统调用;
- 文件系统的抽象层(VFS),页缓存等机制在此时发挥作用;
- 文件系统的具体实现;
- 对块设备的读写,IO 调度器、设备映射(device mapper)等功能在此时发挥作用;
- 通过硬件驱动向存储设备发送指令;
- 硬件内部的控制器处理这些指令,在磁盘、颗粒上进行操作。
这样做直接带来了几个问题:
其一是系统调用具有不可忽视的开销。对于 IO 操作这类复杂的系统调用,除了需要由用户态切换入内核态之外,操作系统也需要进行进程状态的保存和恢复。在存储设备的性能大幅提升的今天,这二者的开销占据的比例也逐渐变得不可忽视。
其二是文件系统的实现对上层应用的影响巨大。因为不同的文件系统使用不同的数据结构来管理文件、适用于不同的应用场景:比如 XFS 在大量小文件时表现不佳。这种影响对于上层应用来说是不可控的。
其三是 Linux 作为一个通用操作系统,在页缓存算法的选取、对底层硬件的支持上都以“通用”为第一要求,这使得它的设计无法对某类专门应用(比如数据库)和某些特定硬件(比如 NVMe 磁盘)做出充分的优化。
其四是存在着重复日志的问题。抽象的每一层都试图通过日志保证自身的稳定性:NVMe 控制器有日志、文件系统也可能有日志、RocksDB 也有日志。在现在的情形下要保证整体的稳健是缺一不可的。但如果能全局考虑、整体分析,能否节省出一些呢?
面对这些问题,解决的方式是显而易见的 ——将应用向下延伸,探得越深,需要自己做的事情就越多越复杂,而带来的性能上的收益就越大。
技术实现
在这次实践中,我们将 “下探” 到上述的步骤五 —— 即从 TiKV 直接向 NVMe 磁盘发送指令。正如前文所言,“下探” 到哪一步事实上是一个权衡。我们团队认为当前阶段 NVMe 磁盘逐渐普及开来,并且提供了特别多相较于传统技术的新特性(比如 4KB 原子写、极低延迟和超高并发队列),这使得针对 NVMe 设备进行设计变得更有必要。幸运的是,这种想法和社区环境是相符的:**Intel 已经提供了开源的存储工具包 SPDK,里面包含了 NVMe 的用户态驱动和对它的一些包装。**所谓用户态驱动,便是通过 VFIO 等方式将硬件 IO 内存映射至用户态可访问的内存,从而达到由应用程序不经过操作系统直接访问硬件的目的,这一技术更广泛地应用在虚拟机程序上,让虚拟机能够直接访问硬件(比如访问显卡或网卡)达到“穿透”的目的。在此之上,SPDK 还实现了一套名为 BlobFS 的“文件系统”,提供类似 POSIX 文件系统的函数接口。以下是使用 SPDK BlobFS 进行 IO 操作的大致步骤:
- 应用程序调用 blobfs_create, blobfs_read 等函数;
- 从文件系统操作映射到对存储设备的操作;
- 向 NVMe 设备发送指令(技术上讲,是向 NVMe 设备对应的内存区域中写入指令)。
相比起 Linux 功能全面、复杂的 IO 栈,使用 SPDK 之后的 IO 步骤显得简单不少。相比之下,使用 SPDK blobfs 能够带来以下显著优势:
- 函数调用的开销远小于系统调用。
- blobfs 利用了 NVMe 设备能够进行原子读写的特性,简化了文件系统元数据的管理。
- 拥有不同于通用 Page Cache 的缓存策略,对连续读写有较大优化。对于 Rocksdb 来说,这种缓存策略对 LSM 的 Compaction 优化较为明显。但同时也失去了对点查的额外缓存。
可以看出,这些优势与上文提到的四个问题对应,消除了系统调用的开销、使用了更适合数据库程序和 NVMe 磁盘的数据结构与缓存算法、简化了文件系统的日志。在将 SPDK blobfs 集成至 TiKV 中之后,应该能够获得较大的性能提升。
结果分析
期待着获得性能提升的尝试最终总要跑一跑 Benchmark 来看看它是否能达到预期。因为测试资源和时间有限,同时为了单纯地比较 IO 上的提升,我们选取了 ycsb workload-a 为基准进行了测试。最终结果超出了我的预期:
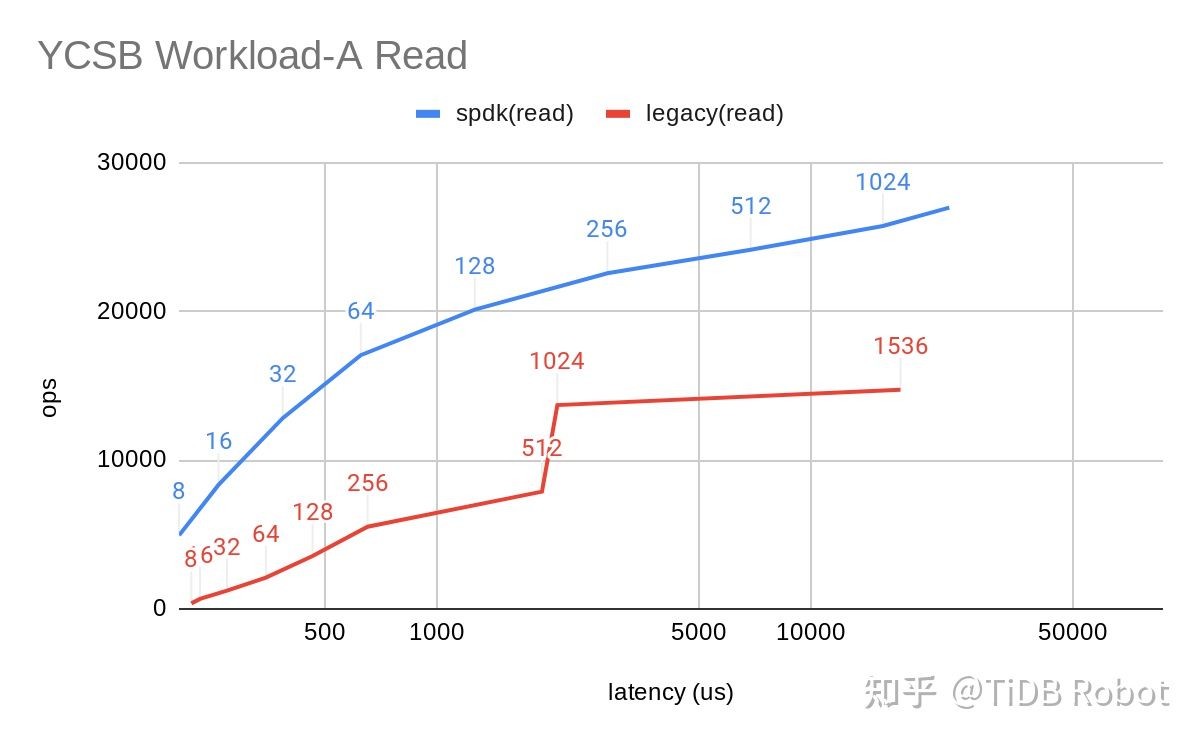

图中数据点的标签为客户端线程数,可以看出在容忍相同的延迟的前提下,基于 SPDK 的 TiKV 能够提供更高的 Ops 即更大的吞吐量。
可见的未来
单论该项目的未来发展,可能更多的取决于历史的发展 —— NVMe 磁盘是否已经足够普及?TiKV 是否到了一定要通过它来提升性能的地步?**我个人是很看好的:NVMe 磁盘的应用无论在民用还是工业都是大势所趋;而 TiKV 作为一款优秀的数据库产品,更高的性能也是它一贯地追求。**并且现在 TiDB 的云服务问世,提供云服务对用户来说能够显著降低 SPDK 的使用和配置门槛(是无感知的提升)。
而在方法论上,进行这一选题的方法也已经在业内开花结果多年:比如将“下探”的过程更进一步,在软件中完成 NVMe 控制器的工作,既是现在的 Open Channel SSD 技术,已经有论文研究了 LSM tree 中 sst 只读与 SSD 中块只读(复写需要先擦除)的这一共性,以减少意料之外的擦除带来的性能下降;也可以后退一步,向 Linux 块设备抽象上读写,比如 Ceph 的 BlueFS,相比于直接的文件系统读写将拥有更高的性能,而比起 SPDK 这样的方法能有更好的硬件兼容性和更低的风险。
这些技术都颇为有趣,也许在将来其中的一个或多个会出现在 TiKV 中,成为迈向更高存储性能的基石。





