

本来是雄心壮志的想实现一个Java版本的、比较通用的爬虫框架的,但是整理后又发现此法真的是非常的简单粗暴,跟scrapy等没得比,其实没得比都是正常的啦,我自己本来就水,而且没有深入的去进行实现设计,所以,姑且总结一下当前的能力吧。
实现语言:Java
模拟HTTP请求:HttpClient 4.0
目标页面结构分析、HTTP请求头信息分析:Firefox + firebug / Chrome(F12 开发者模式)
HTML解析:Jsoup
基本思路
网络爬虫的基本思路是:爬虫线程从待抓取URL队列中拿取一个URL -> 模拟浏览器GET请求到目标URL -> 将网页内容下载回来 -> 然后对页面的内容进行解析、获取目标数据保存到相应的存储 -> 再以一定的规则从当前抓取的网页中获取接下来需要继续爬取的URL。
当然以上思路是建立在爬取过程无需模拟登录、被爬的网站比较善良不会做一些“反爬”的工作的基础上,然而现实中,模拟登录有时还是非常重要的(如新浪微博);不会反爬的网站也少之又少,当频访问站点时,可能会被冻结账号、封IP、返回“系统繁忙”“请慢点儿访问”等信息。因此需要对爬虫进行健壮性增强:增加对反爬信息的处理、动态切换账号/IP、访问时间delay等。
程序架构
由于模拟登录模块比较复杂,并且不同的网站实现的机制也不尽相同,因此这里只给出一个示意图,下文主要针对不需要进行登录的爬虫进行分析。
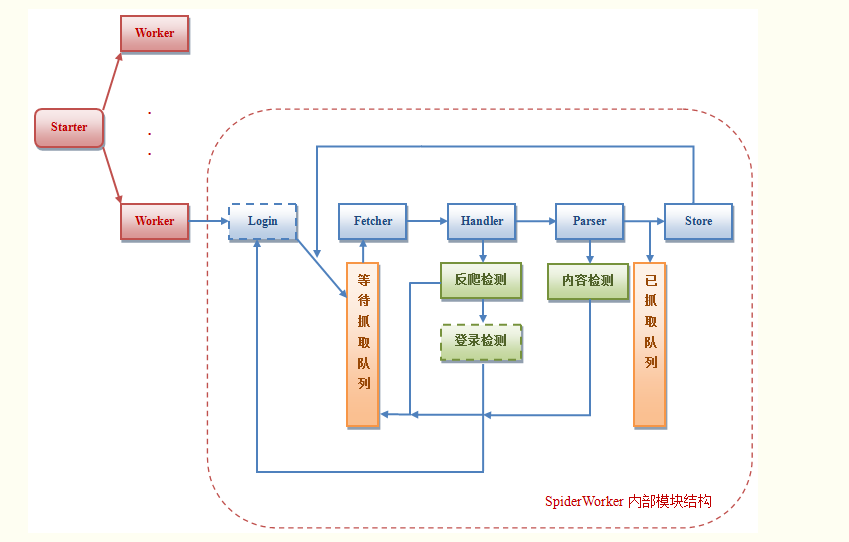
Worker:每一个worker就是一个爬虫线程,由主线程SpiderStarter创建
Login(可选):爬虫模拟登录模块,可以设置一个账号队列,一旦账号被冻结,则将其放入队列尾部,并从头部获取一个新账号再次登录。队列的长度需 >= 账号冻结时间 / 每个账号可以支持的连续爬取时间
Fetcher:爬虫模拟浏览器发出GET URL请求,下载页面
Handler:对Fetcher下载的页面进行初步处理,如判断该页面的返回状态码是否正确、页面内容是否为反爬信息等,从而保证传到Parser进行解析的页面是正确的
Parser:对Fetcher下载的页面内容进行解析,获取目标数据
Store:将Parser解析出的目标数据存入本地存储,可以是MySQL传统数据库,也可以Redis等KV存储
待抓取队列:存放需要抓取的URL
已抓取队列:存放已经抓取到的页面的URL
程序流程图
以下为爬虫实现的流程图,图中绿色方框代表这几个步骤是在同一个模块中的,模块名称用红字表明。

本文为慕课网作者原创,转载请标明【原文作者及本文链接地址】。侵权必究,谢谢合作!
















热门评论
-

imeilige2015-12-29 1
-

soothing2017-07-17 0
-

梦也笙箫寒2016-12-08 0
查看全部评论说好的实现呢
实现。。实现呢?有实现代码就好了。
请问,我想获取页面的div.ID,使用getElementById ,ID是循环的,改怎样说实现获取所有ID属性相同的数据呢?