
一文搞懂序列化与反序列化
日常求赞,感谢老板。
一、是什么
序列化:就是将对象转化成字节序列的过程。
反序列化:就是讲字节序列转化成对象的过程。
对象序列化成的字节序列会包含对象的类型信息、对象的数据等,说白了就是包含了描述这个对象的所有信息,能根据这些信息“复刻”出一个和原来一模一样的对象。
二、为什么
那么为什么要去进行序列化呢?有以下两个原因
- 持久化:对象是存储在JVM中的堆区的,但是如果JVM停止运行了,对象也不存在了。序列化可以将对象转化成字节序列,可以写进硬盘文件中实现持久化。在新开启的JVM中可以读取字节序列进行反序列化成对象。
- 网络传输:网络直接传输数据,但是无法直接传输对象,可在传输前序列化,传输完成后反序列化成对象。所以所有可在网络上传输的对象都必须是可序列化的。
三、怎么做
怎么去实现对象的序列化呢?
Java为我们提供了对象序列化的机制,规定了要实现序列化对象的类要满足的条件和实现方法。
- 对于要序列化对象的类要去实现Serializable接口或者Externalizable接口
- 实现方法:JDK提供的ObjectOutputStream和ObjectInputStream来实现序列化和反序列化
下面分别实现Serializable和Externalizable接口来演示序列化和反序列化
1.实现Serializable接口
public class TestBean implements Serializable {
private Integer id;
private String name;
private Date date;
//省去getter和setter方法和toString
}
序列化:
public static void main(String[] args) {
TestBean testBean = new TestBean();
testBean.setDate(new Date());
testBean.setId(1);
testBean.setName("zll1");
//使用ObjectOutputStream序列化testBean对象并将其序列化成的字节序列写入test.txt文件
try (FileOutputStream fileOutputStream = new FileOutputStream("D:\\test.txt");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);) {
objectOutputStream.writeObject(testBean);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
执行后可以在test.txt文件中看到序列化内容
反序列化:
public static void main(String[] args) {
try (FileInputStream fileInputStream = new FileInputStream("D:\\test.txt");
ObjectInputStream objectInputStream=new ObjectInputStream(fileInputStream)) {
TestBean testBean = (TestBean) objectInputStream.readObject();
System.out.println(testBean);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
输出结果
TestBean{id=1, name='zll1', date=Fri Nov 27 14:52:48 CST 2020}
注意:
- 一个对象要进行序列化,如果该对象成员变量是引用类型的,那这个引用类型也一定要是可序列化的,否则会报错
- 同一个对象多次序列化成字节序列,这多个字节序列反序列化成的对象还是一个(使用==判断为true)(因为所有序列化保存的对象都会生成一个序列化编号,当再次序列化时回去检查此对象是否已经序列化了,如果是,那序列化只会输出上个序列化的编号)
- 如果序列化一个可变对象,序列化之后,修改对象属性值,再次序列化,只会保存上次序列化的编号(这是个坑注意下)
- 对于不想序列化的字段可以再字段类型之前加上transient关键字修饰(反序列化时会被赋予默认值)
2.实现Externalizable接口
实现Externalizable接口必须重写连个方法
- writeExternal(ObjectOutput out)
- readExternal(ObjectInput in)
举个例子:
public class TextBean implements Externalizable {
private Integer id;
private String name;
private Date date;
//可以自定义决定那些需要序列化
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeInt(id);
out.writeObject(name);
out.writeObject(date);
}
//可以自定义决定那些需要反序列化
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
this.id = in.readInt();
this.name = (String) in.readObject();
this.date = (Date) in.readObject();
}
//省去getter和setter方法和toString
}
序列化:
public static void main(String[] args) {
TextBean textBean = new TextBean();
textBean.setDate(new Date());
textBean.setId(1);
textBean.setName("zll1");
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("D:\\externalizable.txt"))) {
outputStream.writeObject(textBean);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
反序列化:
public static void main(String[] args) {
try (ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D:\\externalizable.txt"))) {
TextBean textBean = (TextBean) objectInputStream.readObject();
System.out.println(textBean);
//输出结果:TextBean{id=1, name='zll1', date=Fri Nov 27 16:49:17 CST 2020}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
注意:
- 序列化对象要提供无参构造
- 如果序列化时一个字段没有序列化,那反序列化是要注意别给为序列化的字段反序列化了
3.serialVersionUID的作用
先讲述下序列化的过程:在进行序列化时,会把当前类的serialVersionUID写入到字节序列中(也会写入序列化的文件中),在反序列化时会将字节流中的serialVersionUID同本地对象中的serialVersionUID进行对比,一直的话进行反序列化,不一致则失败报错(报InvalidCastException异常)
serialVersionUID的生成有三种方式(private static final long serialVersionUID= XXXL ):
- 显式声明:默认的1L
- 显式声明:根据包名、类名、继承关系、非私有的方法和属性以及参数、返回值等诸多因素计算出的64位的hash值
- 隐式声明:未显式的声明serialVersionUID时java序列化机制会根据Class自动生成一个serialVersionUID(最好不要这样,因为如果Class发生变化,自动生成的serialVersionUID可能会随之发生变化,导致匹配不上)
序列化类增加属性时,最好不要修改serialVersionUID,避免反序列化失败
IDEA中新建Class可以在类名上按alt+enter:
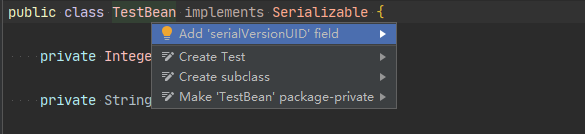
如果不显示上图提示,可以按照下面步骤设置:

四、最后
其实对于对象转化成json字符串和json字符串转化成对象,也是属于序列化和反序列化的范畴,相对于JDK提供的序列化机制,各有各的优缺点:
- JDK序列化/反序列化:原生方法不依赖其他类库、但是不能跨平台使用、字节数较大
- json序列化/反序列化:json字符串可读性高、可跨平台使用无语言限制、扩展性好、但是需要第三方类库、字节数较大





