
Hadoop介绍
Hadoop-大数据开源世界的亚当夏娃。
核心是HDFS数据存储系统,和MapReduce分布式计算框架。
HDFS
原理是把大块数据切碎,
每个碎块复制三份,分开放在三个廉价机上,一直保持有三块可用的数据互为备份。使用的时候只从其中一个备份读出来,这个碎块数据就有了。
存数据的叫datenode(格子间),管理datenode的叫namenode(执伞人)。
MapReduce
原理是大任务先分堆处理-Map,再汇总处理结果-Reduce。分和汇是多台服务器并行进行,才能体现集群的威力。难度在于如何把任务拆解成符合MapReduce模型的分和汇,以及中间过程的输入输出<k,v> 都是什么。
单机版Hadoop介绍
对于学习hadoop原理和hadoop开发的人来说,搭建一套hadoop系统是必须的。但
- 配置该系统是非常头疼的,很多人配置过程就放弃了。
- 没有服务器供你使用
这里介绍一种免配置的单机版hadoop安装使用方法,可以简单快速的跑一跑hadoop例子辅助学习、开发和测试。
要求笔记本上装了Linux虚拟机,虚拟机上装了docker。
安装
使用docker下载sequenceiq/hadoop-docker:2.7.0镜像并运行。
[root@bogon ~]# docker pull sequenceiq/hadoop-docker:2.7.0
2.7.0: Pulling from sequenceiq/hadoop-docker860d0823bcab: Pulling fs layer e592c61b2522: Pulling fs layer
下载成功输出
Digest: sha256:a40761746eca036fee6aafdf9fdbd6878ac3dd9a7cd83c0f3f5d8a0e6350c76a
Status: Downloaded newer image for sequenceiq/hadoop-docker:2.7.0
启动
[root@bogon ~]# docker run -it sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash --privileged=true
Starting sshd: [ OK ]
Starting namenodes on [b7a42f79339c]
b7a42f79339c: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-b7a42f79339c.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-b7a42f79339c.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-b7a42f79339c.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-b7a42f79339c.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-b7a42f79339c.out
启动成功后命令行shell会自动进入Hadoop的容器环境,不需要执行docker exec。在容器环境进入/usr/local/hadoop/sbin,执行./start-all.sh和./mr-jobhistory-daemon.sh start historyserver,如下
bash-4.1# cd /usr/local/hadoop/sbin
bash-4.1# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [b7a42f79339c]
b7a42f79339c: namenode running as process 128. Stop it first.
localhost: datanode running as process 219. Stop it first.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: secondarynamenode running as process 402. Stop it first.
starting yarn daemons
resourcemanager running as process 547. Stop it first.
localhost: nodemanager running as process 641. Stop it first.
bash-4.1# ./mr-jobhistory-daemon.sh start historyserver
chown: missing operand after `/usr/local/hadoop/logs'
Try `chown --help' for more information.
starting historyserver, logging to /usr/local/hadoop/logs/mapred--historyserver-b7a42f79339c.out
Hadoop启动完成,如此简单。
要问分布式部署有多麻烦,数数光配置文件就有多少个吧!我亲眼见过一个hadoop老鸟,因为新换的服务器hostname主机名带横线“-”,配了一上午,环境硬是没起来。
运行自带的例子
回到Hadoop主目录,运行示例程序
bash-4.1# cd /usr/local/hadoop
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
20/07/05 22:34:41 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/07/05 22:34:43 INFO input.FileInputFormat: Total input paths to process : 31
20/07/05 22:34:43 INFO mapreduce.JobSubmitter: number of splits:31
20/07/05 22:34:44 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1594002714328_0001
20/07/05 22:34:44 INFO impl.YarnClientImpl: Submitted application application_1594002714328_0001
20/07/05 22:34:45 INFO mapreduce.Job: The url to track the job: http://b7a42f79339c:8088/proxy/application_1594002714328_0001/
20/07/05 22:34:45 INFO mapreduce.Job: Running job: job_1594002714328_0001
20/07/05 22:35:04 INFO mapreduce.Job: Job job_1594002714328_0001 running in uber mode : false
20/07/05 22:35:04 INFO mapreduce.Job: map 0% reduce 0%
20/07/05 22:37:59 INFO mapreduce.Job: map 11% reduce 0%
20/07/05 22:38:05 INFO mapreduce.Job: map 12% reduce 0%
mapreduce计算完成,有如下输出
20/07/05 22:55:26 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=291
FILE: Number of bytes written=230541
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=569
HDFS: Number of bytes written=197
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5929
Total time spent by all reduces in occupied slots (ms)=8545
Total time spent by all map tasks (ms)=5929
Total time spent by all reduce tasks (ms)=8545
Total vcore-seconds taken by all map tasks=5929
Total vcore-seconds taken by all reduce tasks=8545
Total megabyte-seconds taken by all map tasks=6071296
Total megabyte-seconds taken by all reduce tasks=8750080
Map-Reduce Framework
Map input records=11
Map output records=11
Map output bytes=263
Map output materialized bytes=291
Input split bytes=132
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=291
Reduce input records=11
Reduce output records=11
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=159
CPU time spent (ms)=1280
Physical memory (bytes) snapshot=303452160
Virtual memory (bytes) snapshot=1291390976
Total committed heap usage (bytes)=136450048
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=437
File Output Format Counters
Bytes Written=197
hdfs命令查看输出结果
bash-4.1# bin/hdfs dfs -cat output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
例子讲解
grep是一个在输入中计算正则表达式匹配的mapreduce程序,筛选出符合正则的字符串以及出现次数。
shell的grep结果会显示完整的一行,这个命令只显示行中匹配的那个字符串
grep input output 'dfs[a-z.]+'
正则表达式dfs[a-z.]+,表示字符串要以dfs开头,后面是小写字母或者换行符\n之外的任意单个字符都可以,数量一个或者多个。
输入是input里的所有文件,
bash-4.1# ls -lrt
total 48
-rw-r--r--. 1 root root 690 May 16 2015 yarn-site.xml
-rw-r--r--. 1 root root 5511 May 16 2015 kms-site.xml
-rw-r--r--. 1 root root 3518 May 16 2015 kms-acls.xml
-rw-r--r--. 1 root root 620 May 16 2015 httpfs-site.xml
-rw-r--r--. 1 root root 775 May 16 2015 hdfs-site.xml
-rw-r--r--. 1 root root 9683 May 16 2015 hadoop-policy.xml
-rw-r--r--. 1 root root 774 May 16 2015 core-site.xml
-rw-r--r--. 1 root root 4436 May 16 2015 capacity-scheduler.xml
结果输出到output。
计算流程如下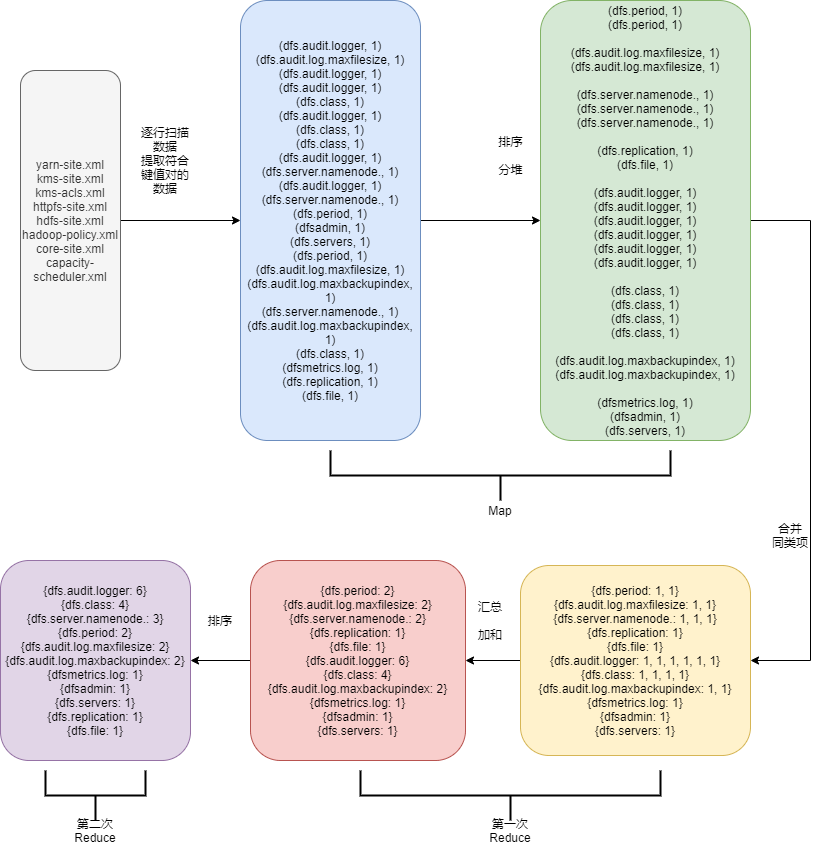
稍有不同的是这里有两次reduce,第二次reduce就是把结果按照出现次数排个序。map和reduce流程开发者自己随意组合,只要各流程的输入输出能衔接上就行。
管理系统介绍
Hadoop提供了web界面的管理系统,
| 端口号 | 用途 |
|---|---|
| 50070 | Hadoop Namenode UI端口 |
| 50075 | Hadoop Datanode UI端口 |
| 50090 | Hadoop SecondaryNamenode 端口 |
| 50030 | JobTracker监控端口 |
| 50060 | TaskTrackers端口 |
| 8088 | Yarn任务监控端口 |
| 60010 | Hbase HMaster监控UI端口 |
| 60030 | Hbase HRegionServer端口 |
| 8080 | Spark监控UI端口 |
| 4040 | Spark任务UI端口 |
加命令参数
docker run命令要加入参数,才能访问UI管理页面
docker run -it -p 50070:50070 -p 8088:8088 -p 50075:50075 sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash --privileged=true
执行这条命令后在宿主机浏览器就可以查看系统了,当然如果Linux有浏览器也可以查看。我的Linux没有图形界面,所以在宿主机查看。
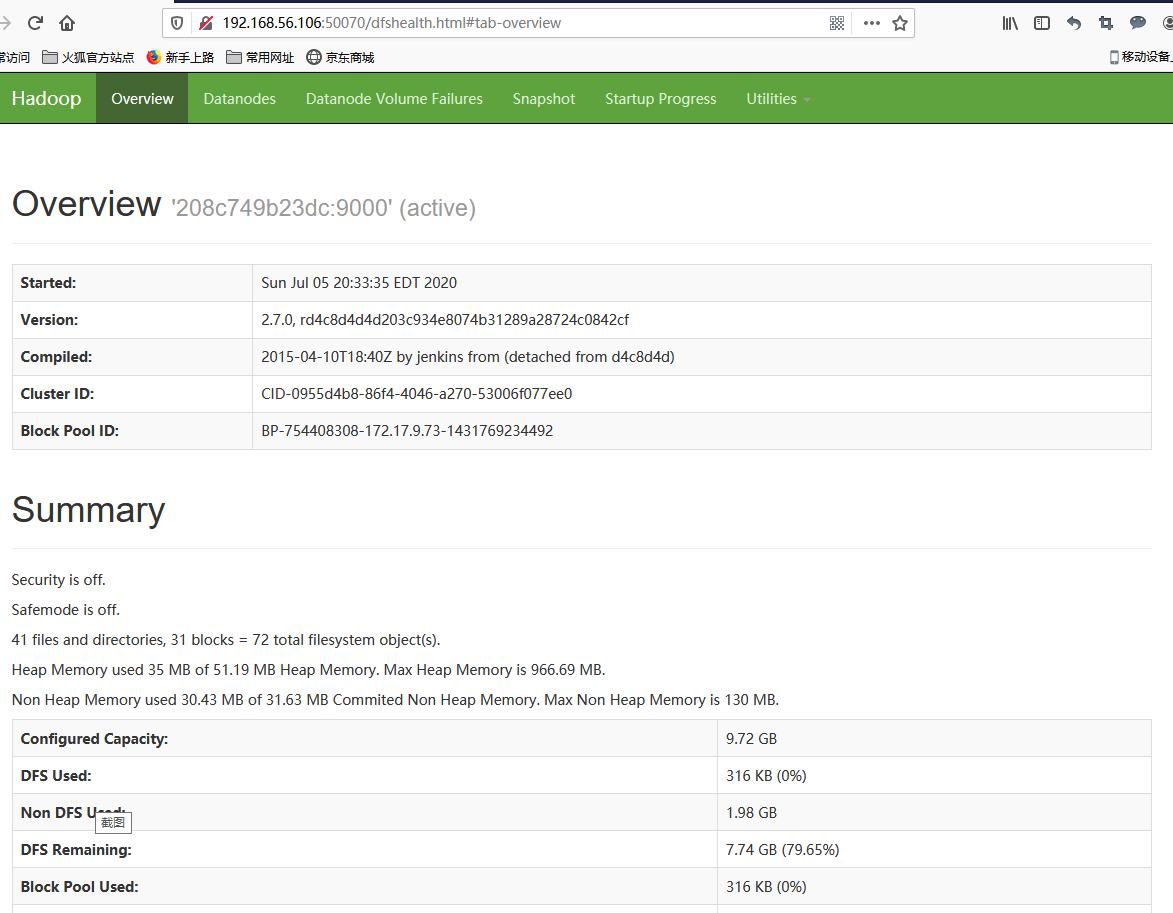
50070 Hadoop Namenode UI端口
50075 Hadoop Datanode UI端口
8088 Yarn任务监控端口
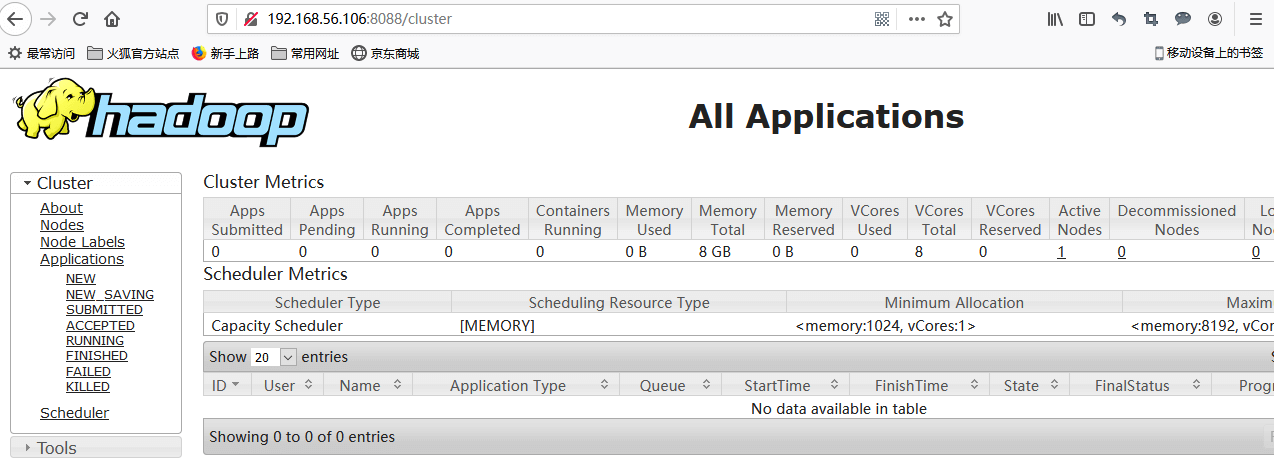
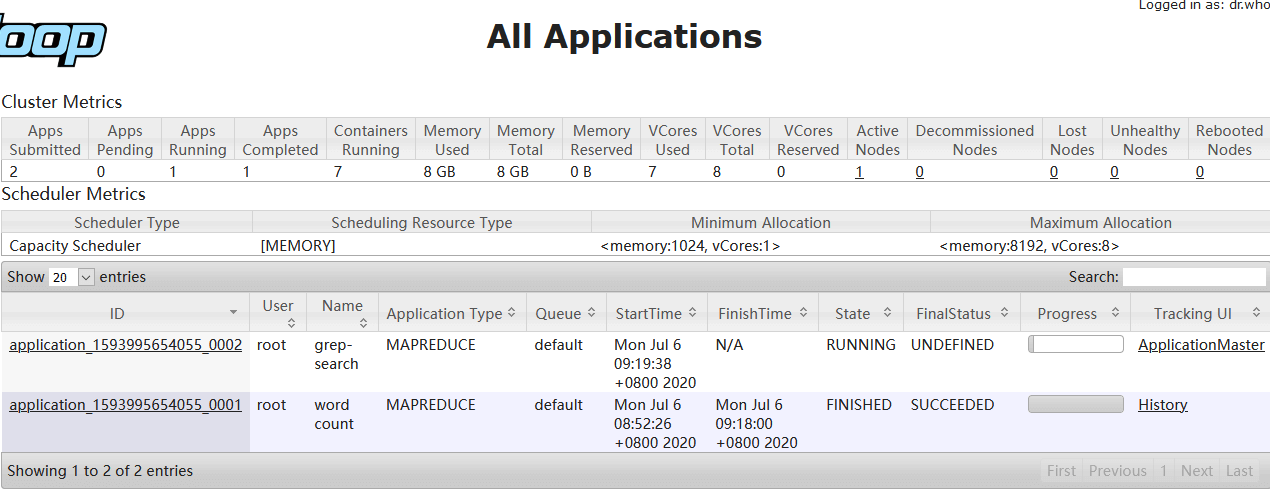
已完成和正在运行的mapreduce任务都可以在8088里查看,上图有gerp和wordcount两个任务。
一些问题
一、./sbin/mr-jobhistory-daemon.sh start historyserver必须执行,否则运行任务过程中会报
20/06/29 21:18:49 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:10020. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
java.io.IOException: java.net.ConnectException: Call From 87a4217b9f8a/172.17.0.1 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
二、./start-all.sh必须执行否则报形如
Unknown Job job_1592960164748_0001错误
三、docker run命令后面必须加–privileged=true,否则运行任务过程中会报java.io.IOException: Job status not available
四、注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。或者换成output01试试?
总结
本文方法可以低成本的完成Hadoop的安装配置,对于学习理解和开发测试都有帮助的。如果开发自己的Hadoop程序,需要将程序打jar包上传到share/hadoop/mapreduce/目录,执行
bin/hadoop jar share/hadoop/mapreduce/yourtest.jar
来运行程序观察效果。




