
数据结构基本上就是——它们是可以处理一些 数据 的 结构 。或者说,它们是用来存储一组相关数据的。
在Python中有四种内建的数据结构——列表、元组和字典,集合。我们将会学习如何使用它们,以及它们如何使编程变得简单
一、列表list
是处理一组有序项目的数据结构,即你可以在一个列表中存储一个 序列 的项目。假想你有一个购物列表,上面记载着你要买的东西,你就容易理解列表了。只不过在你的购物表上,可能每样东西都独自占有一行,
而在Python中,你在每个项目之间用逗号分割。列表中的项目应该包括在方括号中,这样Python就知道你是在指明一个列表。
一旦你创建了一个列表,你可以添加、删除或是搜索列表中的项目。由于你可以增加或删除项目,我们说列表是 可变的 数据类型,即这种类型是可以被改变的
# 购物清单
shoplist = ['苹果', '芒果', '胡萝卜', '香蕉']
基本操作
print ('我有', len(shoplist),'个商品在我的购物清单.')
print ('它们是:'), # 提示
for item in shoplist:
print(item)
print ('我还买了大米.')
shoplist.append('大米')
print ('现在我的购物清单是', shoplist)
# ['苹果', '芒果', '胡萝卜', '香蕉','大米']
基本操作——增
append 追加
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li.append('大米')
print(li)
# ['苹果', '芒果', '胡萝卜', '香蕉','大米']
li.append(1)
# ['苹果', '芒果', '胡萝卜', '香蕉','大米', 1]
print(li.append('hello'))
#None:无返回值,li.append()只是一个方法、动作
print(li)
# ['苹果', '芒果', '胡萝卜', '香蕉','大米', 1 , 'hello']
**insert **插入
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li.insert(3,'草莓')
print(li)
# ['苹果', '芒果', '胡萝卜', '草莓', '香蕉']
extend追加到末尾
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li.extend('cc')
print(li)
# ['苹果', '芒果', '胡萝卜', '香蕉', 'c', 'c']
li.extend([1,2,3])
print(li)
# ['苹果', '芒果', '胡萝卜', '香蕉', 'c', 'c', 123]
li.extend(123) #报错:数字不能迭代
print(li)
#TypeError: 'int' object is not iterable
应用实例:
连续输入员工姓名,输入Q/q退出并打印列表
li = []
while True:
username = input("请输入要添加的员工姓名:")
if username.strip().upper() == 'Q':
break
li.append(username)
print(li)
print(li)
运行结果:
 ]
]
列表——删
remove:按照元素删除
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li.remove('芒果')
print(li)
# ['苹果', '胡萝卜', '香蕉']
pop:按照索引删除——有返回值
li = ['苹果', '芒果', '胡萝卜', '香蕉']
name = li.pop(1) #有返回值
print(name,li)
# 芒果 ['苹果', '胡萝卜', '香蕉']
name = li.pop() #不写索引则默认删除最后一个
print(name,li)
# 香蕉 ['苹果', '胡萝卜']
clear: 清空
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li.clear()
print(li)
#[]
del:删除
li = ['苹果', '芒果', '胡萝卜', '香蕉']
del li[2:]
print(li)
# ['苹果', '芒果']
del li #删除之后,已经不存在,打印报错
print(li)
#NameError: name 'li' is not defined
循环删除
li = [11,22,33,44,55]
for i in range(len(li)):
print(i)
del li[0]
print(li)

列表——改
**li[索引] **= ‘被修改的内容’
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li[0] = '火龙果' #将索引为0的位置改为‘火龙果’
print(li)
# ['火龙果', '芒果', '胡萝卜', '香蕉']
**li[切片] **= ‘被修改的内容’(迭代式:分成最小的元素,一个一个添加)
li = ['苹果', '芒果', '胡萝卜', '香蕉']
li[0:2] = 'abcd'
# 将索引0-2替换为abcd,切片之后迭代处理
print(li)
// ['a', 'b', 'c', 'd', '胡萝卜', '香蕉']
li[0:3]=['我','喜欢','吃','水果']
print(li)
// ['我', '喜欢', '吃', '水果', 'd', '胡萝卜', '香蕉'
列表——查
从头到尾 :for循环
li = ['苹果', '芒果', '胡萝卜', '香蕉']
for i in li:
print(i)
某一个:索引
li = ['苹果', '芒果', '胡萝卜', '香蕉']
print(li[1]) #芒果
一段:切片
li = ['苹果', '芒果', '胡萝卜', '香蕉']
print(li[0:2]) #['苹果', '芒果', '胡萝卜']
列表——嵌套
li = ['苹果', '芒果', '胡萝卜', ['a','b','c'],'香蕉']
print(li[2][1]) #萝
li[3][0].upper()
#把列表中第四个元素列表的第一个元素变为大写
print(li)
# ['苹果', '芒果', '胡萝卜', ['a', 'b', 'c'], '香蕉']
列表——循环打印
#索引默认从零开始
li = ['alex','taibai','wusir','egon']
for i in li:
print(li.index(i),i)
指定索引从100开始
运行结果:
其他常用操作
split**:**字符串转换成列表 str—>list
s = 'xcsd_cdc_eht_木木'
print(s.split('_'))
// ['xcsd', 'cdc', 'eht', '木木']
s1 = 'xc sdc dc eht曾 木木'
print(s1.split(' '))
// ['xc', 'sdc', 'dc', 'eht曾', '木木']
**join:**列表转换成字符串 list—>str
join(可迭代对象iterable) split
可迭代对象iterable:list,str,元祖
li = ['xcsd', 'cdc', 'eht', '木木']
s = ''.join(li)
print(s) #xcsdcdceht木木
s1 = '_'.join(li)
print(s1) #xcsd_cdc_eht_木木
range:顾头不顾尾——相当于有序的数字列表(可以反向,加步长)
for i in range(2,6):
print(i)
应用实例:
循环打印,列表里遇到列表也需要循环打印
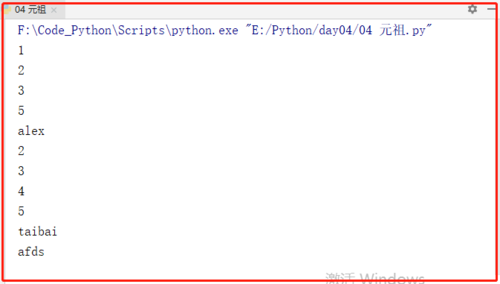
li = [1,2,3,5,'alex',[2,3,4,5,'taibai'],'afds']
for i in li:
if type(i) == list:
for n in i:
print(n)
else:
print(i)
运行结果:
二、元祖
元组和列表十分类似,只不过元组和字符串一样是 不可变的 即你不能修改元组。元组通过圆括号中用逗号分割的项目定义。
元组通常用在使语句或用户定义的函数能够安全地采用一组值的时候,即被使用的元组的值不会改变
tu1 = (1)
tu2 = (1,)
print(tu1,type(tu1)) #1
print(tu2,type(tu2)) #(1,)
tu3 = ([1])
tu4 = ([1],)
print(tu3,type(tu3)) #[1]
print(tu4,type(tu4)) #([1],)
元组的基本操作
tu = (1,2,3,'alex','egon')
print(tu[2]) #3
print(tu[0:2]) #(1, 2)
for i in tu:
print(i) #循环打印元祖
字典
字典类似于你通过联系人名字查找地址和联系人详细情况的地址簿,即,我们把键(名字)和值(详细情况)联系在一起。注意,键必须是唯一的,就像如果有两个人恰巧同名的话,你无法找到正确的信息。
注意,你只能使用不可变的对象(比如字符串)来作为字典的键,但是你可以把不可变或可变的对象作为字典的值。
基本说来就是,你应该只使用简单的对象作为键。
键值对在字典中以这样的方式标记:d = {key1 : value1, key2 : value2 }。
注意它们的键/值对用冒号分割,而各个对用逗号分割,所有这些都包括在花括号中
dict
key(键)必须是不可变数据类型,可哈希
value(值)任意数据类型
dict 优点:二分查找去查询
存储大量的关系型数据
特点:<=3.5版本无序,3.6以后都是有序
1.字典— 增
dic[‘键’] = 值
dic1 = {'age':18,'name':'xc','sex':'female'}
dic1['height'] = 165
print(dic1)
# 没有键值对,增加
# {'age': 18, 'name': 'xc', 'sex': 'female', 'height': 165}
dic1['age'] = 21
print(dic1)
#有键值对,则修改
#{'age': 21, 'name': 'xc', 'sex': 'female', 'height': 165}
setdefault 设置默认
# dic1 = {'age':18,'name':'xc','sex':'female'}
dic1.setdefault('weight',120)
print(dic1)
# 没有键值对,增加
# {'age': 18, 'name': 'xc', 'sex': 'female', 'weight': 120}
dic1.setdefault('name','aa')
print(dic1)
#有键值对,不做任何操作
# {'age': 18, 'name': 'xc', 'sex': 'female', 'weight': 120}
2. 字典—— 删
删除优先使用pop(有返回值,要删除的内容不存在时不报错),而不是del
pop 删除
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.pop('age'))
#有age直接删除---有返回值,按键删除
print(dic1)
#18 {'name': 'xc', 'sex': 'female'}
print(dic1.pop('erge','没有此键/None'))
#没有erge----可设置返回值:没有此键/None
print(dic1)
popitem 随机删除
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.popitem())
#('sex', 'female')
#随机删除:有返回值-----返回元祖:删除的键值
clear 清空
dic1 = {'age':18,'name':'xc','sex':'female'}
dic1.clear() #清空字典
print(dic1) #{}
del 删除
dic1 = {'age':18,'name':'xc','sex':'female'}
del dic1['name']
# 有,则删除
# del dic1['name1'] #没有,则报错
print(dic1)
#{'age': 18, 'sex': 'female'}
3. 字典—— 改
update
dic = {'age':18,'name':'xc','sex':'female'}
dic2 = {'name':'alex','weight':'168'}
dic2.update(dic)
#有则更新覆盖,没有则增加
print(dic)
#{'age': 18, 'name': 'xc', 'sex': 'female'}
print(dic2)
#{'name': 'xc', 'weight': '168', 'age': 18, 'sex': 'female'}
4. 字典——查
keys,values,items
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.keys(),type(dic1.keys()))
#键 dict_keys(['age', 'name', 'sex'])
print(dic1.values())
#值 dict_values([18, 'xc', 'female'])
print(dic1.items())
#元祖 dict_items([('age', 18), ('name', 'xc'), ('sex', 'female')])
得到键值,首选get
print(dic1['name']) #有则打印
#print(dic1['name1']) #没有则报错
print(dic1.get('name'))
#有name直接输出---有返回值
print(dic1.get('name1','没有此键'))
#没有name1----可设置返回值:没有此键/None
循环输出
for i in dic1:
print(i) #循环打印键(默认为键)
for i in dic1.keys():
print(i) #循环打印键
for i in dic1.values():
print(i) #循环打印值
5. 字典的嵌套
dic = { 'name':['alex','wusir','xinchen'],
'py9':{
'time':'1213',
'study_fee':19800,
'addr':'CBD',
},
'age':21
}
dic['age'] = 56
# 找到age,再更新为56
print(dic)
dic['name'].append('rt')
#找到name,在添加名字
print(dic)
dic['name'][1] = dic['name'][1].upper()
#找到name,再把wusir变为大写
print(dic)
dic['py9']['female'] = 6
#找到元祖,增加键值对female:6
print(dic)
应用实例:
#输入一串字符,遇到字母,转换为‘_’,并打印输出
info = input('请输入:')
for i in info:
if i.isalpha():
info = info.replace(i,'_')
print(info)
运行结果:

四、集合
集合 类似于列表,但每个元素都必须是独一无二且不可变的:
它是无序的
基本操作
print(set1)
#{1, 2, 3}
set2 = {1,2,3,[2,3],{'name':'xc'}}
#列表是可变的(不可哈希),所以出错
print(set2)
#TypeError: unhashable type: 'list'
1. 集合——增
add
set1 = {'alex','wusir','ritian','egon','barry'}
# (1)add #因为集合是无序的,所以每次运行结果不一定一样,增加的位置也不一定一样
set1.add('nvshen')
#{'ritian', 'nvshen', 'egon', 'wusir', 'alex', 'barry'}
print(set1)
update
set1.update('xc')
#迭代添加,依然是无序的
print(set1)
#{'egon', 'x', 'wusir', 'nvshen', 'c', 'alex', 'ritian', 'barry'}
2. 集合——删
set1 = {'alex','wusir','ritian','egon','barry'}
pop–随机删除
print(set1.pop())
#egon:有返回值,返回本次删除的内容
print(set1)
#{'barry', 'alex', 'wusir', 'ritian'}
remove——指定元素删除
set1.remove('alex')
print(set1)
#{'egon', 'wusir', 'barry', 'ritian'}
clear——清空
set1.clear()
print(set1)
#空集合:set()
del
del set1
#删除之后集合不存在,报错
print(set1)
#NameError: name 'set1' is not defined
3.集合不能改
集合是无序;
集合中的元素是不可变数据类型
4. 集合——查
set1 = {'alex','wusir','ritian','egon','barry'}
for i in set1:
print(i)
运行结果:

5. 集合之间的操作
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
交集
print(set1 & set2)
#(1) {4, 5}
print(set1.intersection(set2))
#(2) {4, 5}
并集
print(set1 | set2)
#(1) {1, 2, 3, 4, 5, 6, 7, 8}
print(set1.union(set2))
#(2) {1, 2, 3, 4, 5, 6, 7, 8}
反交集–除交集以外的其他元素
print(set1 ^ set2)
#(1) {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2))
#(2) {1, 2, 3, 6, 7, 8}
差集–前者独有的
print(set1 - set2) #(1) {1, 2, 3}
print(set1.difference(set2)) #(2) {1, 2, 3}
print(set2 - set1) #(1) {8, 6, 7}
print(set2.difference(set1)) #(2) {8, 6, 7}
子集与超集
set3 = {1,2,3,4,5}
set4 = {1,2,3,4,5,6,7,8}
print('------ set3是set4的子集 ------')
print(set3 < set4) #True
print(set3.issubset(set4)) #True
print('------ set4是set3的超集 ------')
print(set4 > set3) #True
print(set4.issuperset(set3)) #True
五、公共方法
排序
正向排序:sort()
li = [1,5,4,2,6,7,3]
li.sort()
print(li) #[1, 2, 3, 4, 5, 6, 7]
倒序排序:li.sort(reverse = True)
li = [1,5,4,2,6,7,3]
li.sort(reverse = True)
print(li) #[7, 6, 5, 4, 3, 2, 1]
反转:li.reverse()
li = [1,5,4,2,6,7,3]
li.reverse()
print(li) #[3, 7, 6, 2, 4, 5, 1]
补充:
字符串列表排序——根据字符串的第一个字符对应的ASCII码排序
li = ['ojhy','asa','cvd','hdk']
li.sort()
print(li) #['asa', 'cvd', 'hdk', 'ojhy']
count() 数元素出现的次数
li = ['xcsd', 'cdc', '木木',[1, 5, 2], 'eht', '木木']
num = li.count('木木')
print(num) #2:'木木'出现2次
len() 计算列表的长度
li = ['xcsd', 'cdc', '木木',[1, 5, 2], 'eht', '木木']
l = len(li)
print(l) #6:列表长度为6
li.index(‘元素’) 查看索引
li = ['xcsd', 'cdc', '辛辰',[1, 5, 2], 'eht', '辛辰']
print(li.index('eht'))
#4:'eht'的索引为4元祖
六. 区别与异同
| 列表list | 元组 tuple | 集合 set | 字典 dict | |
|---|---|---|---|---|
| 可否读写 | 读写 | 只读 | 读写 | 读写 |
| 可否重复 | 是 | 是 | 否 | 是 |
| 存储方式 | 值 | 值 | 键 (不能重复) |
键值对 (键不能重复) |
| 是否有序 | 有序 | 有序 | 无序 | 自动正序 |
| 初始化 | [1,‘a’] | (‘a’, 1) | set([1,2]) 或 {1,2} |
{‘a’:1,‘b’:2} |
| 添加 | append | 只读 | add | d[‘key’] = ‘value’ |
| 读元素 | l[2:] | t[0] | 无 | d[‘a’] |





