Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。Flink被设计为在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
什么是Flink
1.1. 处理无界和有界数据
数据可以作为无界流或有界流被处理
Unbounded streams(无界流)有一个起点,但没有定义的终点。它们不会终止,而且会源源不断的提供数据。无边界的流必须被连续地处理,即事件达到后必须被立即处理。等待所有输入数据到达是不可能的,因为输入是无界的,并且在任何时间点都不会完成。处理无边界的数据通常要求以特定顺序(例如,事件发生的顺序)接收事件,以便能够推断出结果的完整性。
Bounded streams(有界流)有一个定义的开始和结束。在执行任何计算之前,可以通过摄取(提取)所有数据来处理有界流。处理有界流不需要有序摄取,因为有界数据集总是可以排序的。有界流的处理也称为批处理。
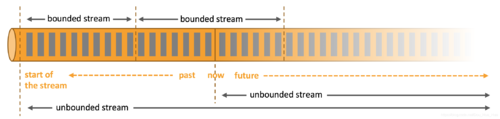
Apache Flink擅长处理无界和有界数据集。对时间和状态的精确控制使Flink的运行时能够在无边界的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部处理,从而产生出色的性能。
1.2. 部署应用程序在任何地方
Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink可以与所有常见的群集资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立群集运行。
Flink被设计为能够很好地工作于前面列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,该模式允许Flink以惯用的方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据该应用程序配置自动识别所需的资源,并向资源管理器请求。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信均通过REST调用进行。这简化了Flink在许多环境中的集成。
1.3. 部署应用程序在任何地方
Flink的设计目的是在任何规模上运行有状态流应用程序。应用程序可能被并行化为数千个任务,这些任务分布在集群中并同时执行。因此,一个应用程序可以利用几乎无限数量的cpu、主内存、磁盘和网络IO。而且,Flink很容易维护非常大的应用程序状态。它的异步和增量检查点算法确保对处理延迟的影响最小,同时保证精确一次(exactly-once)状态一致性。
1.4. 利用内存性能
有状态的Flink应用程序针对本地状态访问进行了优化。任务状态始终在内存中维护,如果状态大小超过可用内存,则在访问高效的磁盘数据结构中维护。因此,任务通过访问本地(通常在内存中)状态来执行所有计算,从而产生非常低的处理延迟。通过定期异步将本地状态检查点指向持久存储,Flink确保了故障发生时的一次状态一致性。
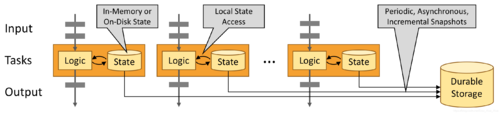
1.5. 流应用程序的构建块
流应用程序的类型由框架控制流、状态和时间的能力来定义
Streams(流)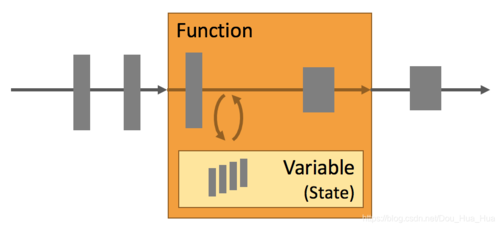
Flink是一个通用的处理框架,可以处理任何类型的流。
Bounded and unbounded streams : 流可以是无边界的,也可以是有边界的。Flink具有复杂的特性来处理无界流,但也有专门的操作符来高效地处理有界流。
Real-time and recorded streams : 所有数据都以流的形式生成。有两种处理数据的方法。在生成流时对其进行实时处理,或将流持久化到存储系统,并在以后进行处理。Flink应用程序可以处理记录的流和实时流。
State(状态)
每个重要的流应用程序都是有状态的,只有在个别事件上应用转换的应用程序才不需要状态。任何运行基本业务逻辑的应用程序都需要记住事件或中间结果,以便在稍后的时间点访问它们,例如在接收下一个事件时或在特定的持续时间之后。
在Flink中,应用程序状态是非常重要的。这一点在很多地方都有体现:
Multiple State Primitives : Flink为不同的数据结构(例如,原子值、list、map等)提供状态原语
Pluggable State Backends : 应用程序状态由可插入状态后端管理并进行检查点
Exactly-once state consistency : Flink的检查点和恢复算法保证了故障情况下应用状态的一致性
Very Large State : 由于其异步和增量检查点算法,Flink能够维护几个tb大小的应用程序状态
Scalable Applications : 通过将状态重新分配给更多或更少的worker,Flink支持有状态应用程序的伸缩
Time(时间)
时间是流应用程序的另一个重要组成部分。大多数事件流具有固有的时间语义,因为每个事件都是在特定的时间点产生的。此外,许多常见的流计算都是基于时间的,比如窗口聚合、会话、模式检测和基于时间的连接。流处理的一个重要方面是应用程序如何度量时间,即事件时间和处理时间的差异。
Flink提供了一组丰富的与时间相关的特性:
Event-time Mode : 使用事event-time语义处理流的应用程序根据事件的时间戳计算结果。因此,无论是处理记录的事件还是实时事件,事件时间处理都可以提供准确一致的结果。
Watermark Support : Flink在事件时间应用程序中使用水印来推断时间。 水印还是权衡结果的延迟和完整性的灵活机制。
Late Data Handling : 在带有水印的事件时间模式下处理流时,可能会发生所有相关事件到达之前已经完成计算的情况。这种事件称为迟发事件。Flink具有多个选项来处理较晚的事件,例如通过侧面输出重新路由它们并更新先前完成的结果。
Processing-time Mode : 除了event-time模式外,Flink还支持processing-time语义。处理时间模式可能适合具有严格的低延迟要求的某些应用程序,这些应用程序可以忍受近似结果。
1.6. 分层API
Flink提供了三层API。每个API在简洁性和表达性之间提供了不同的权衡,并且针对不同的使用场景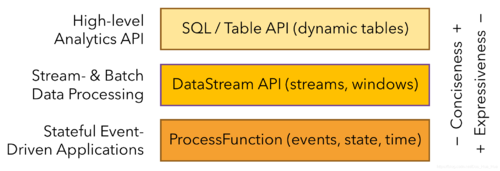
1.7. Stateful Functions
Stateful Functions 是一个API,它简化了分布式有状态应用程序的构建。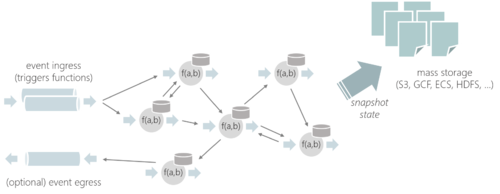
应用场景
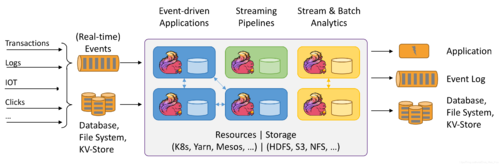
Apache Flink是开发和运行许多不同类型应用程序的最佳选择,因为它具有丰富的特性。Flink的特性包括支持流和批处理、复杂的状态管理、事件处理语义以及确保状态的一致性。此外,Flink可以部署在各种资源提供程序上,例如YARN、Apache Mesos和Kubernetes,也可以作为裸机硬件上的独立集群进行部署。配置为高可用性,Flink没有单点故障。Flink已经被证明可以扩展到数千个内核和TB级的应用程序状态,提供高吞吐量和低延迟,并支持世界上一些最苛刻的流处理应用程序。
下面是Flink支持的最常见的应用程序类型:
Event-driven Applications(事件驱动的应用程序)
Data Analytics Applications(数据分析应用程序)
Data Pipeline Applications(数据管道应用程序)
2.1. Event-driven Applications
事件驱动的应用程序是一个有状态的应用程序,它从一个或多个事件流中获取事件,并通过触发计算、状态更新或外部操作对传入的事件作出反应。
事件驱动的应用程序基于有状态的流处理应用程序。在这种设计中,数据和计算被放在一起,从而可以进行本地(内存或磁盘)数据访问。通过定期将检查点写入远程持久存储,可以实现容错。下图描述了传统应用程序体系结构和事件驱动应用程序之间的区别。
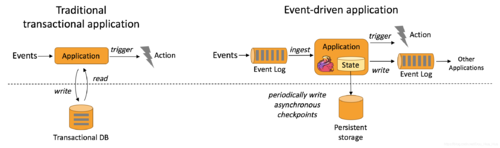
代替查询远程数据库,事件驱动的应用程序在本地访问其数据,从而在吞吐量和延迟方面获得更好的性能。可以定期异步地将检查点同步到远程持久存,而且支持增量同步。不仅如此,在分层架构中,多个应用程序共享同一个数据库是很常见的。因此,数据库的任何更改都需要协调,由于每个事件驱动的应用程序都负责自己的数据,因此更改数据表示或扩展应用程序所需的协调较少。
对于事件驱动的应用程序,Flink的突出特性是savepoint。保存点是一个一致的状态镜像,可以用作兼容应用程序的起点。给定一个保存点,就可以更新或调整应用程序的规模,或者可以启动应用程序的多个版本进行A/B测试。
典型的事件驱动的应用程序有:
欺诈检测
异常检测
基于规则的提醒
业务流程监控
Web应用(社交网络)
2.2. Data Analytics Applications
传统上的分析是作为批处理查询或应用程序对已记录事件的有限数据集执行的。为了将最新数据合并到分析结果中,必须将其添加到分析数据集中,然后重新运行查询或应用程序,结果被写入存储系统或作为报告发出。
有了复杂的流处理引擎,分析也可以以实时方式执行。流查询或应用程序不是读取有限的数据集,而是接收实时事件流,并在使用事件时不断地生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。Dashboard应用程序可以从外部数据库读取最新的结果,也可以直接查询应用程序的内部状态。
Apache Flink支持流以及批处理分析应用程序,如下图所示:
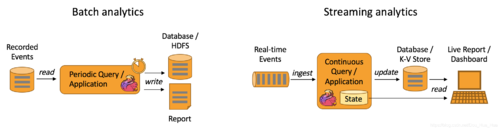
典型的数据分析应用程序有:
电信网络质量监控
产品更新分析及移动应用实验评估
消费者技术中实时数据的特别分析
大规模图分析
2.2. Data Pipeline Applications
提取-转换-加载(ETL)是在存储系统之间转换和移动数据的常用方法。通常,会定期触发ETL作业,以便将数据从事务性数据库系统复制到分析数据库或数据仓库。
数据管道的作用类似于ETL作业。它们转换和丰富数据,并可以将数据从一个存储系统移动到另一个存储系统。但是,它们以连续流模式运行,而不是周期性地触发。因此,它们能够从不断产生数据的源读取记录,并以低延迟将其移动到目的地。例如,数据管道可以监视文件系统目录中的新文件,并将它们的数据写入事件日志。另一个应用程序可能将事件流物化到数据库,或者增量地构建和完善搜索索引。
下图描述了周期性ETL作业和连续数据管道之间的差异: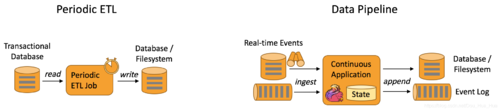
与周期性ETL作业相比,连续数据管道的明显优势是减少了将数据移至其目的地的等待时间。此外,数据管道更通用,可用于更多场景,因为它们能够连续消费和产生数据。
典型的数据管道应用程序有:
电商中实时搜索索引的建立
电商中的持续ETL
安装Flink
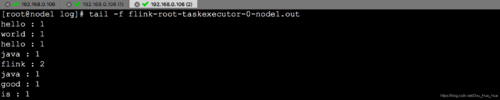
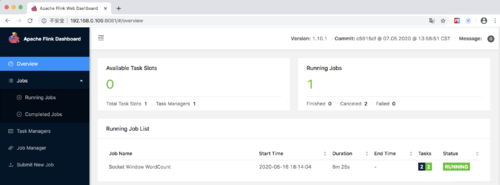
下载安装包,这里下载的是 flink-1.10.1-bin-scala_2.11.tgz
./bin/start-cluster.sh # Start Flink
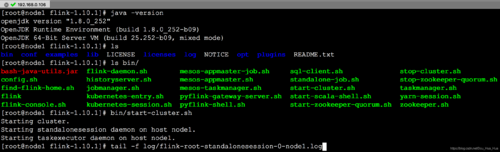
运行 WordCount 示例