
概要
本篇开始介绍Elasticsearch生产集群的搭建及相关参数的配置。
ES集群的硬件特性
我们从开始编程就接触过各种各样的组件,而每种功能的组件,对硬件要求的特性都不太相同,有的需要很强的CPU计算能力,有的对内存需求量大,有的对网卡要求高等待,下面我们讨论一下ES集群对几种硬件的特性需求。
CPU
ES集群对CPU的要求相对低一些,毕竟纯计算的比重要小一些,选用主流的CPU,2核到8核的都可以。
如果有两种CPU可以挑选,一种是主频高但核数少的CPU,另一种是主频一般核数多的CPU,肯定选后一种,因为多核的CPU可以提供更多的并发处理能力,远比单核高性能带来的效益要高。
内存
ES集群对内存的要求很高,部署ES集群时,要把大部分资源投入到内存当中。内存分配主要有两部分,JVM heap内存(堆内存)和OS Cache内存。
JVM heap内存用得不多,主要是OS Cache,我们知道,ES建立的倒排索引,正排索引,过滤器缓存,都是优先放在内存当中的,OS Cache的大小直接决定搜索的性能,如果OS Cache不够,ES搜索等操作只有被迫读硬盘,延时就会从毫秒级升到秒级。
OS Cache具体在多大才算够,取决于数据量,如果是百万级别的数据,16GB左右应该可以接受,如果是亿级,一般单节点都是64GB内存。生产环境最低要求内存应不低于8GB。
硬盘
硬盘成本本身比较便宜,能用SSD就用SSD,访问速度肯定比机械硬盘快,预估好数据量后就尽可能多规划一些容量。
另外尽量使用本地存储,网络存储还依赖于网络传输,这个容易造成一些延迟。
网络
对ES集群这种分布式系统来说,快速并且可靠的网络还是比较重要的,shard的分配和rebalance都需要占用大量的带宽,集群最好部署在同一个局域网内,异地容灾等跨数据中心的部署方案,要考虑到网络故障带来的影响。
JVM选择
使用ES官网推荐的JDK版本,服务端和客户端尽量使用同一个版本的JDK。
涉及到ES服务端的JVM调优设置,保持原样不要轻易改动,毕竟ES已经花了大量人力物力验证过的,随意调整jvm参数可能适得其反。
容量规划
规划集群里,要规划好投入几台服务器,数据量上限是多少,业务模型数据读写的比例是多少,历史数据的迁移方案等,一般来说,百万到10亿内的数据量,使用ES集群还是能够支撑下来的,ES节点数建议不要超过100个。
举个例子:数据量10亿以内,部署5台服务器,8核64GB内存,是能够支撑的。
生产案例模拟
Linux操作系统搭建
我们使用Linux虚拟机来演示一个生产ES集群的搭建。我们创建4台虚拟机,每台2核CPU,4GB内存,操作系统为CentOS 7 64bit。
虚拟机我用的是VMware workstation,有用virtual box也行,CentOS 7、JDK的安装不赘述。记得把CentOS的防火墙关了。
修改每台机器的hostname信息,命令vi /etc/hostname,修改文件,保存即可,建议修改成elasticsearch01,elasticsearch02,elasticsearch03,elasticsearch04。
假定我们4台虚拟机的域名和IP是这样分配的:
192.168.17.138 elasticsearch01
192.168.17.137 elasticsearch02
192.168.17.132 elasticsearch03
192.168.17.139 elasticsearch04
把这段配置放在 /etc/hosts文件末尾,4台机器做相同的配置。
这4台机器之间,可以配置免密登录,如在elasticsearch01机器上,我们执行以下操作:
- 生成公钥文件,命令:
ssh-keygen -t rsa
一直输入回车,不要设置密码默认会将公钥放在/root/.ssh目录下生成id_rsa.pub和id_rsa两个文件
- 拷贝公钥文件
cp id_rsa.pub authorized_keys
- 将公钥文件拷贝到另外三台机器
ssh-copy-id -i elasticsearch02
ssh-copy-id -i elasticsearch03
ssh-copy-id -i elasticsearch03
拷贝完成后,可以在目标机器上/root/.ssh/目录下看到多了一个authorized_keys文件。
- 尝试免密登录,在elasticsearch01机器上输入
ssh elasticsearch02,如果不需要输入密码就能登录到elasticsearch02,说明配置成功,其他机器类似。
这4台机器也可以相互做ssh免密设置。
这里补充一点免密登录的方向性问题,上面的案例是在elasticsearch01机器生成的公钥,并且发送给了elasticsearch02等三台机器,那么我从elasticsearch01跳到elasticsearch02是不需要密码的,反过来从elasticsearch02登录到elasticsearch01,还是需要密码的。
最后补充几个常用检查命令:
- 检查NetManager的状态:systemctl status NetworkManager.service
- 检查NetManager管理的网络接口:nmcli dev status
- 检查NetManager管理的网络连接:nmcli connection show
Elasticsearch服务端
这里选用的JDK版本为1.8.0_211,Elasticsearch版本为6.3.1,自行安装不赘述。
ES解压后的目录结构:
# 用 "tree -L 1" 命令得到的树状结构
.
├── bin
├── config
├── lib
├── LICENSE.txt
├── logs
├── modules
├── NOTICE.txt
├── plugins
└── README.textile
- bin:存放es的一些可执行脚本,比如用于启动进程的elasticsearch命令,以及用于安装插件的elasticsearch-plugin插件
- config:用于存放es的配置文件,比如elasticsearch.yml
- logs:用于存放es的日志文件
- plugins:用于存放es的插件
- data:用于存放es的数据文件的默认目录,就是每个索引的shard的数据文件,一般会另外指定一个目录。
Elasticsearch参数设置
在config目录下的文件,包含了ES的基本配置信息:
.
├── elasticsearch.yml
├── jvm.options
├── log4j2.properties
├── role_mapping.yml
├── roles.yml
├── users
└── users_roles
默认参数
Elasticsearch的配置项比较丰富并且默认配置已经非常优秀了,基本上我们需要改动的是跟服务器环境相关的配置,如IP地址,集群名称,数据存储位置,日志存储位置等外围参数,涉及到内部机制及JVM参数的,一般不干预,不恰当的JVM参数调整反而会导致集群出现性能故障,如果没有充足的理由或数据验证结果,不要轻易尝试修改。
集群和节点名称
在elasticsearch.yml文件里这项配置表示集群名称,配置项默认是注释掉的,集群名称默认为elasticsearch。
#cluster.name: my-application
这个配置项强烈建议打开,用项目约定的命名规范进行重命名,并且将研发环境、测试环境、STG准生产环境、生产环境分别命名,如elasticsearch_music_app_dev表示研发环境,elasticsearch_music_app_sit表示测试环境,elasticsearch_music_app_pro表示生产环境等。避免开发测试环境连错环境,无意中加入集群导致数据问题。
cluster.name: elasticsearch_music_app_pro
节点名称的配置项
#node.name: node-1
默认也是注释掉的,ES启动时会分配一个随机的名称,建议还是自行分配一个名称,这样容易记住是哪台机器,如
node.name: es_node_001_data
文件路径
涉及到文件路径的几个参数,主要有数据、日志、插件等,默认这几个地址都是在Elasticsearch安装的根目录下,但Elasticsearch升级时,有些目录可能会有影响,安全起见,可以单独设置目录。
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
例如我们可以在/var目录下创建相应的文件夹,并且赋予相应的读写权限,如:
path.data: /var/es/data
path.logs: /var/es/logs
日志文件配置
log4j2.properties文件,ES日志框架选用的是log4j2,也就是log4j的进化版本,对Java技术栈熟悉的童鞋,看到这个配置文件会非常熟悉,默认的日志输入配置、格式均能满足日常的故障定位和分析,也不需要什么改动。
默认是一天生成一个日期文件,如果ES承载的数据量特别大,可以调整日志文件产生频率和每个日志文件的大小,以及ES最多存储日志的大小、数量。
Elasticsearch集群发现机制
配置参数
Zen Discovery是Elasticsearch集群发现机制的默认实现,底层通信依赖transport组件,我们完成Elasticsearch集群的配置主要有下面几个参数:
- cluster.name 指定集群的名称。
- node.name 节点名称。
- network.host 节点绑定的IP。
- node.master 可选值为true/false,决定该节点类型为master eligible或data node。
- discovery.zen.ping.unicast.hosts gossip路由服务的IP地址,即集群发现协议通信的公共节点,可以写多个,有节点启动时会向里面的IP发送消息,获取集群其他节点的信息,最后加入集群。
Elasticsearch集群是点对点(P2P)的分布式系统架构,数据索引、搜索操作是node之间直接通信的,没有中心式的master节点,但Elasticsearch集群内的节点也分成master node和data node两种角色。
正常情况下,Elasticsearch集群只有一个master节点,它负责维护整个集群的状态信息,集群的元数据信息,有新的node加入或集群内node宕机下线时,重新分配shard,并同步node的状态信息给所有的node节点,这样所有的node节点都有一份完整的cluster state信息。
集群发现的一般步骤如下:
- 节点配置network.host绑定内网地址,配置各自的node.name信息,cluster.name设置为相同的值。
- discovery.zen.ping.unicast.hosts配置了几个gossip路由的node。
- 所有node都可以发送ping消息到路由node,再从路由node获取cluster state回来。
- 所有node执行master选举。
- 所有node都会跟master进行通信,然后加入master的集群。
master选举
node.master设置为true的,将成为master eligible node,也叫master候选节点,只有master eligible node才能被选举成master node。如果是个小集群,那么所有节点都可以是master eligible node,10个节点以上的集群,可以考虑拆分master node和data node,一般建议master eligible node给3个即可。
master选举过程是自动完成的,有几个参数可以影响选举的过程:
-
discovery.zen.ping_timeout: 选举超时时间,默认3秒,网络状况不好时可以增加超时时间。
-
discovery.zen.join_timeout: 有新的node加入集群时,会发送一个join request到master node,同样因为网络原因可以调大,如果一次超时,默认最多重试20次。
-
discovery.zen.master_election.ignore_non_master_pings:如果master node意外宕机了,集群进行重新选举,如果此值为true,那么只有master eligible node才有资格被选为master。
-
discovery.zen.minimum_master_nodes: 新选举master时,要求必须有多少个 master eligible node去连接那个新选举的master。而且还用于设置一个集群中必须拥有的master eligible node。如果这些要求没有被满足,那么master node就会被停止,然后会重新选举一个新的master。这个参数必须设置为我们的master eligible node的quorum数量。一般避免说只有两个master eligible node,因为2的quorum还是2。如果在那个情况下,任何一个master候选节点宕机了,集群就无法正常运作了。
集群故障探查
有两种集群故障探查机制
- master主动对集群中所有的其他node发起ping命令,判断它们是否是存活着的。
- 每个node向master node发送ping请求,判断master node是否存活,否则就会发起一个选举过程。
有下面三个参数用来配置集群故障的探查过程:
- ping_interval:ping一次node的间隔时间,默认是1s
- ping_timeout:每次ping的timeout等待时长,默认是30s
- ping_retries:对node的ping请求失败了,重试次数,默认3次。
集群状态更新
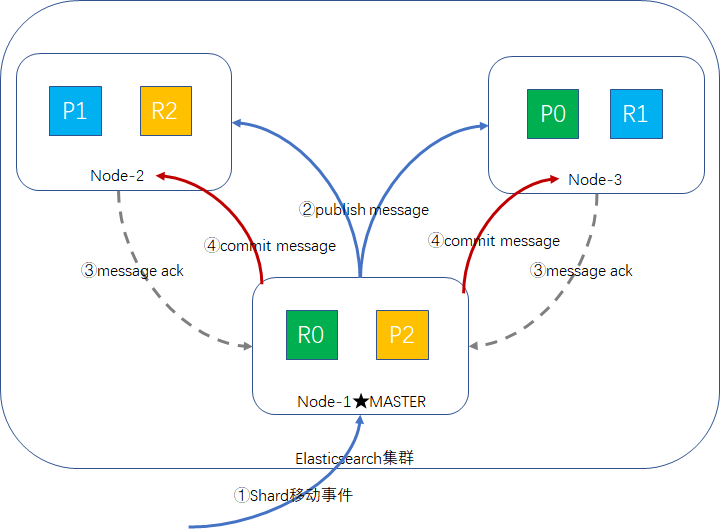
master node是集群中唯一可以对cluster state进行更新的node。更新的步骤如下:
- master node收到更新事件,如shard移动,可能会有多条事件,但master node一次只处理一个集群状态的更新事件。
- master node将事件更新到本地,并发布publish message到集群所有的node上。
- node接收publish message后,对这个message返回ack响应,但是不会立即更新。
- 如果master没有在指定的时间内(discovery.zen.commit_timeout配置项,默认是30s),从至少N个节点(discovery.zen.minimum_master_nodes配置项)获取ack响应,那么这次cluster state change事件就会被reject,最终不会被提交。
- 如果在指定时间内,指定数量的node都返回了ack消息,那么cluster state就会被commit,然后master node把 commit message发送给所有的node。所有的node接收到那个commit message之后,接着才会将之前接收到的集群状态应用到自己本地的状态副本中去。
- master会等待所有node的commit message 的ack消息,在一个等待超时时长内,如果接收到了响应,表示状态更新成功,master node继续处理内存queue中保存的下一个更新事件。
discovery.zen.publish_timeout默认是30s,这个超时等待时长是从plublish cluster state开始计算的。
我们可以参照此图:
master node宕机问题
Elasticsearch集群中,master node扮演着非常重要的角色,如果master node宕机了,那岂不是群龙无首了?虽然有master选举,但这个也是要时间的,没有master node那段空档期集群该怎么办?
说了一半,基本上是完了,但我们也可以设置,群龙无首时哪些操作可以做,哪些操作不能做。
discovery.zen.no_master_block配置项可以控制在群龙无首时的策略:
- all: 一旦master宕机,那么所有的操作都会被拒绝。
- write:默认的选项,所有写操作都会被拒绝,但是读操作是被允许的。
split-brain(脑分裂问题)
在Elasticsearch集群中,master node非常重要,并且只有一个,相当于整个集群的大脑,控制将整个集群状态的更新,如果Elasticsearch集群节点之间出现区域性的网络中断,比如10个节点的Elasticsearch集群,4台node部署在机房A区,6台node部署在机房B区,如果A区与B区的交换机故障,导致两个区隔离开来了,那么没有master node的那个区,会触发master选举,如果选举了新的master,那么整个集群就会出现两个master node,这种现象叫做脑分裂。

这样现象很严重,会破坏集群的数据,该如何避免呢?
回到我们前面提到的discovery.zen.minimum_master_nodes参数,这个值的正确设置,可以避免上述的脑分裂问题。
discovery.zen.minimum_master_nodes参数表示至少需要多少个master eligible node,才可以成功地选举出master,否则不进行选举。
足够的master eligible node计算公式:
quorum = master_eligible_nodes / 2 + 1
如上图我们10个node的集群,如果全部是master eligible node,那么quorum = 10/2 + 1 = 6。
如果我们有3个master eligible node,7个data node,那么quorum = 3/2 + 1 = 2。
如果集群只有2个节点,并且全是master eligible node,那么quorum = 2/2 + 1 = 2,问题就来了,如果随便一个node宕机,在只剩下一个node情况下,无法满足quorum的值,master永远选举不成功,集群就彻底无法写入了,所以只能设置成1,后果是只要这两个node之间网络断了,就会发生脑分裂的现象。
所以一个Elasticsearch集群至少得有3个node,全部为master eligible node的话,quorum = 3/2 + 1 = 2。如果我们设置minimum_master_nodes=2,分析一下会不会出现脑分裂的问题。
场景一:A区一个node,为master,B区两个node,为master eligible node

A区因为只剩下一个node,无法满足quorum的条件,此时master取消当前的master角色,且无法选举成功。
B区两个master eligible node,满足quorum条件,成功选举出master。
此时集群还是只有一个master,待网络故障恢复后,集群数据正常。
场景二:A区一个node,为master eligible node,B区2个node,其中一个是master

A区只有一个master eligible node,不满足quorum的条件,无法进行选举。
B区原本的master存在,不需要进行选举,并且满quorum的条件,master角色可以保留。
此时集群还是一个master,正常。
综上所述:3个节点的集群,全部为master eligible node,配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。
minimum_master_nodes动态修改
因为集群是可以动态增加和下线节点的,quorum的值也会跟着改变。minimum_master_nodes参数值需要通过api随时修改的,特别是在节点上线和下线的时候,都需要作出对应的修改。而且一旦修改过后,这个配置就会持久化保存下来。
修改api请求如下:
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}
响应报文:
{
"acknowledged": true,
"persistent": {
"discovery": {
"zen": {
"minimum_master_nodes": "2"
}
}
},
"transient": {}
}
也可以通过命令查询当前的配置:
GET /_cluster/settings
响应结果如下:
{
"persistent": {
"discovery": {
"zen": {
"minimum_master_nodes": "1"
}
}
},
"transient": {}
}
留一个问题
上图10个节点的集群,假设全是master eligible node,按照上述的网络故障,会不会出现脑分裂现象 ?配置项minimum_master_nodes最低要配置成多少,才不会出现脑分裂的问题?
小结
本篇主要介绍了Elasticsearch集群的部署和参数设置等知识,大部分都不需要人工干预,默认值已经是最优选,集群发现机制和master选举机制了解一下就OK。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区





